____________________________________________________________________________
____________________________________________________________________________
____________________________________________________________________________
Ce module construit un raisonnement. Il utilise des mécanismes (heuristiques) du programme du chaînage avant, arrière ou mixte. Il agit suivant un cycle répétitif qui comporte quatre phases.
1.1. Principe de fonctionnement
SCHEMA A FAIRE.
Première phase : la restriction.
Elle permet de déduire le temps du traitement car l'opération suivante examinera en principe un sous ensemble de règles. Quand la base des règles est divisée en paquets , un mécanisme de contrôle doit permettre de passer d'un paquet à l'autre.Ce mécanisme peut être commandé par des méta-règles.
Deuxième phase : détection des règles activables.
Le moteur d'inférences détecte dans la base de connaissances toutes les règles dont le ou les faits situés :
Troisième phase : choix de la règle à activer.
Le
moteur d'inférence ?????????? la règle qui va être activée,
phase très importante qui détermine l'efficacité du système
expert.
L'utilisation des méta-règles pemet d'utiliser des stratégies
pour choisir une règle mais aussi pour déterminer dans quel ordre
les autres règles doivent être activées.
Si le moteur d'inférence ne trouve aucune règle à activer celui-ci s'arrêtera et demandera des informations supplémentaires à l'utilisateur.
Quatrième phase : EXECUTION DE LA REGLE CHOISIE :
Dans
cette phase la règle sélectionnée est exécutée
avec la mise à jour des faits.
Les faits sont extraits de la partie
action dans un contexte de chaînage avant, de la partie prémisse
dans un contexte de chaînage arrière.
Les niveaux d'un moteur :
Les stratégies d'inférence d'un moteur :
Stratégies irrévocables et par tentatives :
Le chaînage avant :
Rappelons que la partie prémisse des règles est la partie déclencheur dans tous les cas :
Le chaînage arrière :
La
base de faits d'un moteur fonctionnant en chaînage arrière contient
tout à la fois des faits établis et des faits à établir.
Ainsi, la partie déclencheur des règles se réfère
uniquement aux faits à établir, cela signifie donc qu'une règle
n'est déclenchée que si les faits de sa partie prémisse sont
des faits à établir de la base de faits. La règle (dite ici
en arrière) déclenchée apporte donc de nouveaux faits à
établir dans la base de faits sauf si ces faits sont déjà
établis. Le moteur s'arrête sur un succès lorsque la base
de faits ne contient plus de faits à établir ou lorsque le fait
à démontrer est maintenant établi.
Dans les autres cas
(plus de règles déclenchables et le fait à démontrer
n'est toujours pas établi par exemple), c'est un échec.
N.B.
: En cas de blocage du moteur (plus de règles déclenchables
et le fait à démontrer ne l'est toujours pas), on peut effectuer
un retour arrière (on repart avec la base de règles et de faits
du cycle précédent, la base de règles étant diminuée
de la règle précédemment déclenchée, celle
qui a abouti à l'échec). Ce retour peut notamment être obtenu
par l'emploi d'un régime d'inférence par tentatives (backtracking).
Le chaînage mixte :
Dans les moteurs d'inférence
fonctionnant en chaînage mixte ou bidirectionnel, la base de faits comprend
des faits considérés comme établis et des faits à
établir.
Avec le chaînage mixte, on va donc utiliser les
mêmes règles (dîtes alors mixtes), soit en avant, soit en arrière,
suivant les cas. Ici, les conditions de déclenchement des règles
peuvent donc porter simultanément sur des faits établis ou à
établir.
En revanche, avec le chaînage bidirectionnel,
on va en fait enchaîner des cycles en chaînage avant (avec des règles
en avant) et des cycles en chaînage arrière (avec des règles
en arrière). Généralement le S.E. procède par chaînage
avant pour déterminer les conclusions partielles puis ces hypothèses
sont ensuite vérifiées en chaînage arrière.
En fait,
ce type de raisonnement varie d'un moteur à l'autre. La mise en œuvre
semble poser quelques difficultés.
Quelle
stratégie choisir ?
En
chaînage avant l'utilisateur n'est pas contraint de préciser
sa question. Il convient bien à des connaissances empiriques éventuellement
accompagnées de méta-connaissances mais elle semble peu efficace
pour les systèmes complexes.
Le chaînage arrière est
préférable si un ou plusieurs buts sont à atteindre ou à
vérifier. Il est recommandé dans le cas d'informations incomplètes
où le dialogue avec l'utilisateur doit s'installer.
Une stratégie peut être en profondeur et irrévocable ou par tentatives. De même pour la largeur.
Le choix d'une règle à déclencher :
Ce
choix influence fortement les performances du système. Souvent, la stratégie
est figée.
Par exemple, on choisit la première règle
ou la plus utilisée …
L'utilisation des méta-règles
pour guider le choix du système est plus intéressante
2.
Le générateur de système experts :
2.1.
Définitions :
Système expert = moteur d'inférence + connaissances
Générateur
de Systèmes experts (G.S.E.) = moteur d'inférence + utilitaires
de développement et d'exploitation.
Un G.S.E. est un outil de développement
(coquille ou shell en anglais) pour construire une base de connaissances et l'exploiter.
2.2.
L'architecture générale des systèmes experts :
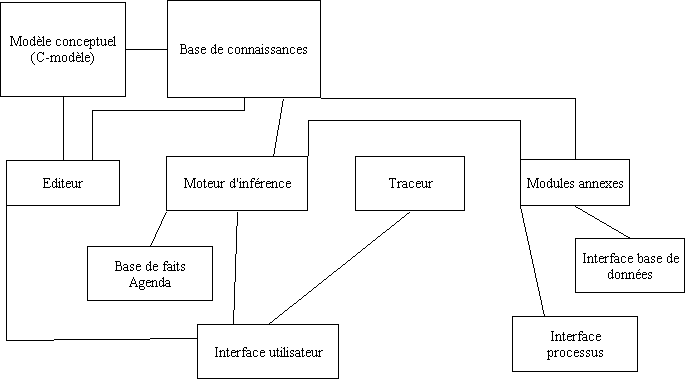
2.2.1. Structure générale d'un générateur de S.E. :
La
base de connaissances :
Meta-règles :
Règles :
La base de faits :
Faits :
Agenda
:
L'éditeur :
Il alimente la base des connaissances. Il sert à acquérir des connaissances dans un dialogue le plus proche possible du langage naturel ou à défaut le plus facilement compréhensible par l'utilisateur expert. Il joue un rôle important dans la structuration des connaissances. Mais c'est un autre module qui vérifie les incohérences. Il tient à jour le dictionnaire des faits des règles ou des objets. Il gère la confidentialité des accès à la base.
Le traceur :
Il permet de suivre la trace des raisonnements.
Le modèle conceptuel ou C-modèle :
Il participe au maintient de la cohérence sémantique statique et dynamique des connaissances (1). Il contient des propriétés auxquelles doivent satisfaire les connaissances acquises.
Les interfaces :
Chaque module doit pouvoir communiquer avec l'utilisateur ou son environnement (base de données, tableur, processus industriels) par l'intermédiaire des interfaces. Les flèches, dans l'architecture de base proposée indique le flux d'informations. Chaque module peut être doté de sa propre interface de dialogue. Les interfaces de processus industriels sont indispensables pour acquérir les données fournie par les capteurs ou pour piloter des automates.
Autres utilitaires :
Ils conviennent pour le calcul, les commentaires, les explications …
2.2.2. L'architecture des systèmes multi-experts :
Les propriétés d'un système multi-experts :
La base de connaissance, nous l'avons vu, correspond au travail d'un spécialiste. Mais certaines applications peuvent couvrir plusieurs domaines qui nécessitent de faire appel à plusieurs spécialistes différents. Un G.S.E. est un outil conçu pour permettre la réalisation de plusieurs systèmes experts mais n'ayant aucun lien entre eux. Un S.E. est une entité indépendante.
Un système multi-experts est un système qui autorise plusieurs systèmes experts à coopérer entre eux. Les applications complexes d'aide à la décision notamment font intervenir des connaissances dans des domaines variés. Un système multi-experts est probablement la seule voie de développement qui respecte l'autonomie de chaque expertise. Les propriétés d'indépendance et de modularité de chaque base de connaissances doivent aussi être assurées.
Le G.S.E. multi-experts doit être capable d'ajouter ou de supprimer de nouveaux modules experts. Par exemple, l'utilisation d'un système expert de terrassement peut conduire l'utilisateur à éprouver le besoin de disposer d'une base de connaissance qui n'existent pas. Par exemple, le choix d'un engin de terrassements en fonction de la nature du sol, de la destination du sol, du climat …. Dans une application au fur et à mesure que les connaissances s'affinent en même temps que le S.E. devient familier, de nouveaux domaines de développement sont à considérer pour proposer les meilleures solutions. Le G.S.E. multi-experts apporte la souplesse d'adaptation.
Le contrôle d'un système multi-experts :
La difficulté est dans la synthèse des connaissances . Les modules experts doivent coopérer le plus intelligemment possible. Le problème de l'intégration des résultats de chaque module expert se pose, avec éventuellement un traitement de synthèse des résultats. La gestion d'un S.E. multi-experts impose trois principales contraintes :
Le G.S.E. multi-experts doit résoudre les problèmes de contrôle de communication entre les modules en satisfaisant aux contraintes énoncées ci-dessus. Le contrôle dans un système multi-experts peut être organisé de deux manières : centralisé et décentralisé.
Le contrôle centralisé fait appel à un module superviseur qui distribue les taches et fait la synthèse des résultats. Deux modes de fonctionnement sont possibles dans ce cas :
Dans un premier mode, les règles et les procédures sont divisées en modules séparés qui communiquent par l'intermédiaire d'un tableau noir (blackboard) [HATO.91] [FERB.89]. Cette architecture apparaît par exemple dans les systèmes Hearsay, ATOME et ATOME-TR [HATO.91].
Dans un deuxième mode, le superviseur possède ses propres connaissances qui lui permettent de contrôler les modules experts (règles et faits) et de gérer les échanges avec les modules. Cette architecture a été retenue par les systèmes ASYMEX et DECIDEX [LEVI.89]. Les systèmes opérationnels fonctionnent avec un contrôle centralisé.
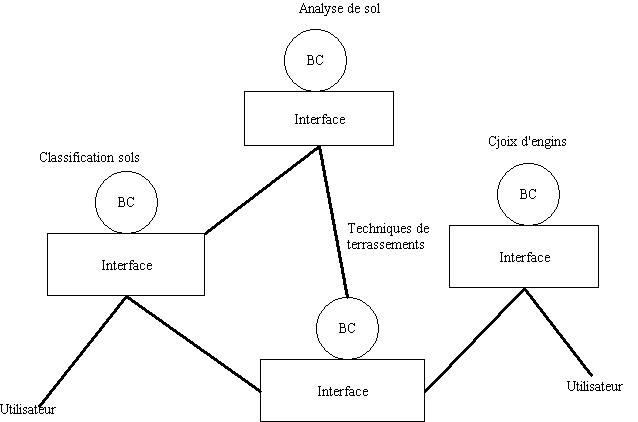
Dans le contrôle décentralisé, aucun module n'a la prééminence sur les autres. La difficulté est de trouver un mécanisme de migration de contrôle d'un module expert à un autre. De plus, le système doit permettre l'ajout ou la suppression de modules-experts avec aisance, sans connaissance approfondie du système de migration. Un prototype a été conçu pour le domaine des terrassements [PETI.89]. Chaque module expert est doté d'une interface qui établit les communications avec les autres modules-experts ou utilisateurs. Le générateur de systèmes multi-experts génère ces interfaces. Des interfaces polymorphes permettent de choisir automatiquement un module expert en fonction du contexte. Une application est résolue avec une structure multi-experts dynamique. La structure du système évolue en fonction du contexte, au fur et à mesure de la résolution du problème. Par exemple, dans le système multi-experts terrassements, l'interface de la BC " classification de sols " fera migrer le contrôle vers la BC terrassements ou la BC " analyse de sols " selon le contexte : météo, saison, région, résultat de tests… Les enchaînements de BC sont fonction du contexte. Bien sûr ce couplage faible entre S.E. autorise l'utilisation de BC représentées par différents formalismes. La puissance du GSME est liée à sa capacité de générer des interfaces sans intervention d'un programmeur.