![]()
![]()
Principes et avantages du routage dynamique
Pour rappel, la fonction de routage doit garantir qu'un noeud I interconnectant deux ou plusieurs sous-réseaux soit capable, à la réception, sur un des un de ces sous-réseaux, d'un paquet à destination de d, de réexpédier ce paquet, via un autre sous-réseau, vers un nud J appartenant à une route d'accès vers d (opération de relayage ou commutation).
En garantissant cette fonctionnalité, tous les noeuds I d'un réseau global R permettent l'acheminement d'un paquet émis par une source quelconque s de R vers une destination quelconque d de R. Ceci contribue à la réalisation du service de la couche Réseau.
Pour être capable de prendre une telle décision de relayage, un nud dispose en permanence de l'information lui permettant de décider vers quel prochain nud il convient de réexpédier un paquet à destination de d. Cette information prend la forme d'une table de routage dont chaque entrée exprime une association entre une destination d et le prochain nud situé sur une route conduisant à d.
La façon dont est obtenue cette information de routage est directement liée à la politique de routage. Il existe 2 grandes classes de politiques de routage :
Ø le routage non adaptatif ou STATIQUE
Ø le routage adaptatif ou DYNAMIQUE
ROUTAGE STATIQUE :
Dans ce cas, le choix de la route à emprunter pour aller du noeud I au noeud J ( " I et J) est calculé par avance. Linformation correspondante est mise en place, sous la forme de tables, sur tous les routeurs et exploitable dès leur initialisation.
Les décisions de routage s'effectuent alors sans aucune considération de la variation de l'état courant du réseau : lévolution de paramètres comme, par exemple, la topologie du réseau ou encore les taux de charge de trafic des liaisons, nest pas considérée.
ROUTAGE ADAPTATIF ou DYNAMIQUE :
Lobjectif dune telle politique de routage est de favoriser des prises de décision de routage dynamiques. Elles vont évoluer au cours du temps afin de mieux prendre en compte les variations des paramètres (topologie, trafic ) et rendre adaptée à ces nouvelles situations les résultats de la fonction de routage.
Ainsi, le calcul périodique et automatique des tables de routage s'effectue à travers l'utilisation d'un algorithme de routage (très souvent issu de la théorie des graphes). Dans un contexte opérationnel, on entrevoit aisément lallègement des tâches de configuration apporté par la mise en place de ces solutions : les équipements de routage devenant assez autonomes pour réagir, de façon pertinente, aux modifications des paramètres du réseau.
La pertinence pouvant aller jusquau calcul de « meilleur(s) chemin(s) » reflétant une optimisation du routage en fonction dun (ou plusieurs) critère(s) dévaluation spécifié(s).
L'implémentation d'un algorithme de routage peut parfois conduire à la définition d'un protocole de routage qui spécifie le format des informations de routage échangées entre les nuds. Ainsi, en contre-partie de lautomatisation, il peut être parfois complexe de déployer et configurer de tels protocoles.
La suite de cette séquence dresse un panorama de lévolution de ces algorithmes de routage dynamique, en détaillant les algorithmes distribués puisquils constituent la base théorique des protocoles de routage dynamique présents dans lenvironnement TCP/IP.
![]()
![]()
Evolution des algorithmes de routage dynamique
A/ Les différentes classes dalgorithmes
Selon la provenance des informations utilisées pour calculer et modifier la valeur des tables de routage, quatre classes peuvent être définies :
Ø algorithmes globaux , utilisent les informations collectées dans l'ensemble du sous-réseau : on parle de routage centralisé.
Ø algorithmes locaux exploitent uniquement l'information propre à un noeud : on parle de routage isolé.
Ø algorithmes hybrides , reposent sur des solutions qui exploitent à la fois des informations locales et globales.
Ø algorithmes distribués , recalculent les solutions à partir des informations communiquées par leurs voisins (nuds adjacents).
Comme déjà précisé, la plupart de ces algorithmes sappuient sur ceux issus de la théorie des graphes. Citons les algorithmes de recherche de plus court chemin dans un graphe (Dijkstra, Bellman, Ford .).
|
|
|
|
Réseau |
Graphe |
|
Routeur Nud |
Sommet |
|
Liaison de communication |
Arc |
|
Coût d'une liaison |
Longueur arc |
Table de correspondance des notions "Réseau" et "Théorie des graphes"
Les critères de détermination du coût dune liaison peuvent être quelconques. A titre dexemples :
Ø Nombre de sauts à effectuer
Ø Temps moyen d'attente et de transmission pour un paquet test
Ø Longueur des files d'attente
Ø Coûts d'exploitation
Ø Distance géographique
Ø ...
Une combinaison multicritères est aussi envisageable.
Il peut être également envisagé de mettre en uvre un routage multiple. Cette approche consiste à disposer de plus dune alternative de routage pour une destination donnée (routage multi chemin) :
Ø chemins « presque équivalents » en terme de longueur
Ø chemins débutant de chacun des voisins
Ø chemins disjoints (Algo de Even)
Ø chemins de coût inférieur à une valeur seuil
Ø ...
Plusieurs approches peuvent être également adoptées pour choisir une ligne parmi les différentes alternatives (choix aléatoire ou paramétré).
Adapté aussi bien au cas des datagrammes que des circuits, le routage multiple peut offrir les avantages suivants :
Augmenter la performance du réseau par une répartition de trafic.
Augmenter la fiabilité en cas de panne de noeuds.
Aiguiller des types de trafic sur différents chemins
B/ Les algorithmes globaux ou routage centralisé
Lobjectif dun routage dynamique centralisé est de tendre vers une connaissance parfaite et globale de l'état du réseau pour prendre les décisions de routage optimales.
Le principe est basé sur lexistence dans le réseau dun Centre de Contrôle de Routage (RCC Routing Control Center). Létablissement des tables de routage sopère en trois étapes .
Quels sont les avantages dune telle approche ?
Ladaptation tend vers la perfection.
Les autres noeuds sont soulagés du calcul du routage.
Quels en sont les inconvénients ?
Panne ou isolement du RCC (solution : doublon + arbitrage)
Vulnérabilité des lignes connectées au RCC (liaisons critiques)
Importance des temps de traitement du RCC (fonction du nombre de noeuds).
Inconsistance de routage possible (délais dacheminement des tables de routage différents selon la proximité des routeurs par rapport au RCC).
C/ Les algorithmes hybrides
Lobjectif est de partager la responsabilité du routage entre un RCC et chaque nud. Le routage DELTA suit lalgorithme suivant :
Etape 1 : Périodiquement, les noeuds envoient au RCC le coût mesuré sur chacune de leur ligne.
Etape 2 : Le RCC calcule les k meilleurs chemins (à D près fixé) pour aller dun noeud I à un noeud J ( quel que soit I et J) et ne conserve que ceux qui empruntent pour chaque I des lignes de sortie différentes.
Etape 3 : Le RCC diffuse ces chemins équivalents aux différents noeuds.
Etape 4 : Chaque noeud I décide localement du choix du chemin.
Outre les bénéfices dun routage multiple, on retrouve la plupart des inconvénients de la solution centralisée à cause de la présence dun RCC.
D/ Les algorithmes locaux ou routage isolé
Le principe général de ces approches est détablir un routage dynamique en utilisant uniquement la connaissance « locale ».
Il se retrouve illustré dans plusieurs algorithmes :
Algorithmes dINONDATION :
Principe :
Chaque paquet entrant est réexpédié sur toutes les lignes de sortie exceptée la ligne darrivée.Inconvénient :
Duplication des paquetsPalliatifs :
Essayer de mettre en place un contrôle de congestion :v par utilisation de compteurs de sauts :
- l'émetteur :initialise ce compteur dans le paquet
- le noeud de commutation : décrémente la valeur du compteur de chaque paquet reçu ; élimine le paquet lorsque le compteur devient nul.
v par utilisation d'estampilles dans les paquets
- l'émetteur : attribue un numéro de série au paquet
- le noeud de commutation : conserve les derniers numéros de série des paquets reçus en provenance de chaque émetteur ; élimine le paquet lorsque le numéro de série dont il est porteur est inférieur à ces valeurs.
Variantes de réexpédition des paquets :
v inondation sélective
v inondation optimale
v inondation aléatoire ...
Principe :
Chaque paquet entrant est réexpédié sur la ligne ayant la file d'attente la plus courte ( quelle que soit sa destination). Lobjectif est donc de se débarrasser au plus vite dun paquet (analogie avec « patate chaude »).Inconvénient :
Pas obligatoirement optimalPalliatif :
Combinaison avec un algorithme statique pour le choix de la ligne
Principe :
Chaque paquet entrant contient l'identificateur de la source et un compteur de sauts.Un noeud de commutation maintient des tables de routage dont chaque entrée contient un triplet :
v un identificateur d'une source
v un nombre de sauts
v une ligne de provenanceLe noeud de commutation modifie sa table de routage dans les 2 cas suivants :
v CAS 1 :
SI l'identificateur de la source du paquet entrant n'est pas encore présent dans sa table de routage
ALORS Ajout du triplet correspondantIllustration cas 1 :

v CAS 2 :
SI l'identificateur de la source du paquet entrant est déjà présent dans sa table de routage
ET la valeur du compteur de sauts du paquet est strictement inférieure à celle du nombre de sauts mémorisée dans la table de routage
ALORS Mise à jour du triplet correspondantIllustration cas 2 :

Dans tous les cas, le noeud de commutation incrémente le compteur de sauts du paquet avant de lexpédier.
Avantage :
En exploitant au niveau local linformation qui transite, lalgorithme converge progressivement vers une solution optimale.Inconvénient :
Nécessité de disposer dans le format de len tête de chaque paquet dun champ compteur de sauts et obligation de le modifier à chaque passage sur un nud.
Chaque nud va constituer dynamiquement ses tables de routage à partir dinformations provenant de ses voisins directs. Ainsi, chacun va adopter le même comportement cyclique quon peut résumer de façon générale comme suit :
1 - Constituer une information de routage initiale
2 - Communiquer régulièrement linformation de routage aux noeuds voisins
3 - Récupérer régulièrement les informations de routage en provenance des noeuds voisins
4 - Mettre à jour linformation de routage en tenant compte des informations provenant des voisins.
Il existe deux classes dalgorithmes de routage distribué :
- routage par « vecteur distance » (distance vector)
- routage par « état de liaison » (link state)
Principe :
Chaque noeud conserve la valeur de la distance entre lui-même et chaque destination possible : cest le vecteur distance.
Ce vecteur distance est calculé à partir des vecteurs distance des noeuds voisins.
Cette technique est directement issue des algorithmes de Bellman et de Ford (version distribuée de Bellman).Vecteur distance et Table de routage :
Chaque entrée de la table de routage dun noeud est un triplet dont les deux premiers termes appartiennent au vecteur distance de ce noeud :
Algorithme :
Initialement :
Chaque routeur est initialisé par un identificateur propre.
Chaque routeur connaît également le coût de chaque liaison adjacente.
Chaque routeur constitue un vecteur distance « singleton » comportant la valeur 0 pour lui-même.
Il diffuse ce vecteur distance sur chacune de ses liaisons le reliant à ses voisins.
De façon courante :
- Chaque routeur qui reçoit, de lun de ses voisins, un vecteur distance sur une liaison L ajoute à chacune des valeurs de ce vecteur le coût de la liaison L.
- Il compare le résultat obtenu avec celles de son propre vecteur distance et éventuellement met à jour ce dernier soit :
- en y rajoutant une destination nouvellement apparue
- en minimisant la distance dune destination déjà connue
Si une modification a été opérée, il diffuse immédiatement son nouveau vecteur distance à chacun de ses voisins.
Si aucune diffusion du vecteur distance na été opérée depuis un intervalle de temps fixé, le routeur expédie son vecteur distance à ses voisins dès que ce temps est écoulé.
Quand communiquer les vecteurs aux voisins ?
1. initialement
2. en cas de modification du vecteur distance
3. lors de la découverte de linterruption dune liaison
4. périodiquementIllustration :
La notation utilisée dans les schémas ci-après illustrant différentes étapes dans la convergence dun algorithme par vecteur distance peut être formalisée comme suit :
Un triplet (S-cible, coût, S-Suivant) associé à un nud, exprime le fait quil existe pour atteindre le nud de nom S-cible à une distance de coût qui passe par le nud voisin S-Suivant.
Routage par ETAT de LIAISON :
Principe :
- Chaque noeud construit et maintient une copie complète de la carte du réseau et calcule localement les meilleurs chemins par lalgorithme de Dijsktra.
- Les modifications de topologie sont communiquées aux autres noeuds par un algorithme dinondation sélective.Algorithme :
- Chaque routeur entre en contact avec ses voisins et apprend leurs noms.
- Chaque routeur construit un paquet connu sous le nom de « paquet détat de liaison » ou LSP (Link State Packet) contenant une liste de noms des voisins repérés et des coûts des liaisons respectives.
- Le LSP est transmis dune manière ou dune autre à tous les autres routeurs, et chaque routeur enregistre le LSP généré le plus récemment par chaque autre routeur.
- Chaque routeur qui possède désormais une connaissance complète de la topologie du réseau et des coûts (convoyée par les LSPs), calcule les routes les plus courtes vers chaque destination par Dijkstra.Quand communiquer les LSPs aux voisins ?
1. initialement
2. en cas de changement du coût dune liaison
3. lors de la découverte dun nouveau voisin
4. lors de linterruption dune liaison
5. périodiquementComment sont transmis les LSPs entre les routeurs ?
Idée 1 : utiliser l'information de routage
pb de récursivité (on utilise linformation de routage pour acheminer de linformation de routage)
Idée 2 : utiliser un algorithme d'inondation
Idée 3 : utiliser des estampilles
Idée 4 : utiliser une combinaison #séquence - âge
pour mettre en place une inondation sélective.Comment sont constitués les LSPs ?
source
numéro de séquence
âge
liste des voisins
Illustration : L'animation ci-après illustre les différentes étapes dans la convergence dun algorithme par état de liaison.
1) Dans la premiere étape, des listes de doublets (S-voisin, coût) sont associés à chacun des nuds. Chaque doublet représente un LSP et exprime le fait quil existe une liaison entre ce nud et le nud S-voisin ayant une distance de coût.
2) Les LSPs initiaux ont été diffusés sur lensemble du réseau. Ainsi chaque nud dispose de la même connaissance à lissue de cette diffusion. On saperçoit que la récolte des LSPs a conduit à lobtention dune description totale dun graphe valué correspondant au réseau.
3) A partir de cette connaissance, chaque nud va localement exécuter lalgorithme de DIJKSTRA pour calculer les meilleurs chemins et élaborer à partir de ces résultats les tables de routage. Ces dernières sont représentées par une liste de triplet (S-Dest, S-Suivant, Coût).
De la même façon que dans le scénario dillustration de lalgorithme « vecteur distance », faisons lhypothèse que la liaison AC tombe. Une fois que les nuds A et C ont chacun constaté le silence entre eux (absence de LSPs échangés depuis un certain temps), ils vont constituer de nouveaux LSPs retranscrivant cette situation et les diffuser au travers du réseau.
5) A lissue de la diffusion sur le réseau, chaque nud ayant constaté une modification de la topologie va appliquer lalgorithme de DIJKSTRA pour obtenir les nouvelles tables de routage.
VECTEUR DISTANCE versus ETAT de LIAISON :
Critère
Vecteur Distance
Etat de liaison
Rapidité de convergence
lent
plus rapide
Occupation mémoire
parfois meilleur
Largeur de Bande
modeste
modeste
Calcul
modeste
modeste
Fonctionnalité
supérieure
Routage Multiple
possible
possible
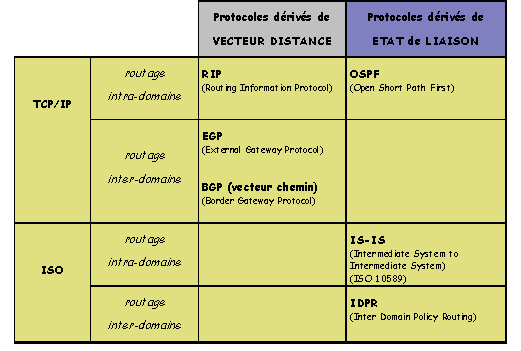
PROTOCOLES de routage DISTRIBUES : normes et standards :
![]()
Introduction au Routage Dynamique dans IP
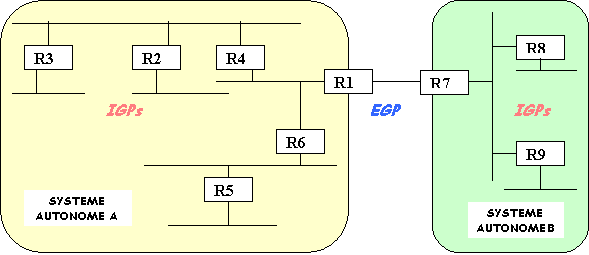
LInternet a introduit la notion de « système
autonome » (AS Autonomous System) pour faciliter la gestion du
routage.
Un système autonome est un domaine
de routage (réseaux et routeurs) sous une responsabilité administrative
unique. Celle-ci est chargée de ladministration des plans dadressage et
de routage, de la sécurité, de la facturation
Tout AS est officiellement identifié par un numéro
sur 2 octets. Cest un organisme certifié (RIPE NCC (Europe), ARIN, APNIC,
IANA) qui attribue ce numéro à lorganisation. Tout comme pour les adresses
IP, des numéros sont réservés pour des usages privés.
Ainsi, lInternet peut être vu comme un ensemble dAS interconnectés. On peut alors distinguer deux catégories dAS :
Les AS « utilisateurs » de linterconnexion qui produisent ou consomment de linformation. Il sagit là des réseaux dentreprises, dinstitutions ou dadministrations
Les AS « transporteurs » qui permettent de véhiculer les informations entre les AS « utilisateurs ». Ceux-ci correspondent davantage aux réseaux des IAP (Internet Access Providers).
Découlant de cette décomposition, deux classes de protocoles de routage peuvent être définies :
Les protocoles internes (IGP Internal Gateway Protocol) sappliquent à lintérieur dun AS. Ils permettent lélaboration des tables de routage des routeurs présents dans un domaine. Leur objectif est de découvrir la topologie du réseau et de calculer les routes éventuellement les mieux adaptées à lintérieur de lAS. RIP, OSPF, EIGRP appartiennent à cette catégorie.
Les protocoles externes (EGP External Gateway Protocol) sont dédiés au routage entre AS. Lobjectif est dans ce cas de supporter les stratégies de routage consenties entre les différents acteurs de linterconnexion. Les protocoles EGP et BGP relèvent de cette catégorie.
![]()
Les Protocoles de Routage Interne
A/ Le protocole RIP
RIP : Routing Information Protocol(RFC 1058 - 2453)
Caractéristiques générales
Protocole de routage « intérieur »
- De type « vecteur distance »
- Créé par Berkeley
- Au dessus de UDP/IP
- Lors dune période « stable », des messages RIP sont émis toutes les 30 secondes
- Rafraîchissement de route obligatoire dans les 3 minutes, sinon la distance devient infinie
- Messages de « Mises à jour déclenchées » (cas de changement) sont séparés par un délai aléatoire variant entre 1 et 5 secondes
- Peu performant, mais beaucoup utilisé car configuration aisée
|
0 |
4 |
8 |
10 |
|
16 |
|
|
24 |
31 |
|
Commande |
Version |
Zéro |
|||||||
|
ID de famille dadresse |
Zéro |
||||||||
|
Adresse IP destination #1 |
|||||||||
|
Zéro |
|||||||||
|
Zéro |
|||||||||
|
Métrique vers destination IP #1 |
|||||||||
|
Adresse IP destination #2 |
|||||||||
|
Zéro |
|||||||||
|
Zéro |
|||||||||
|
Métrique vers destination IP #2 |
|||||||||
|
jusquà 25 destinations peuvent être mentionnées (taille max = 512 octets) |
|||||||||
+ Champ COMMANDE : (8 bits)
+ Indique sil sagit : dune requête (= 1)
(i.e. lors du démarrage, demande denvoi dinformations de routage sans attendre la prochaine diffusion)
ou dune réponse (= 2)
(cas de réponse à une requête, cas denvoi périodique ou polling, ou cas denvoi dune mise à jour suite à une reconfiguration).+ Champ NUMÉRO de VERSION : (8 bits)
+ Numéro de version du protocole RIP.
+ Champ IDENTIFIANT de FAMILLE dADRESSE : (16 bits)
+ Indique la nature de ladressage réseau sur lequel porte le routage (= 2 pour IPv4.)
+ Champ ADRESSE DESTINATION #i : (32 bits)
+ Adresse IP de destination (0.0.0.0 pour le routage par défaut).
+ Champ METRIQUE vers DESTINATION #i : (32 bits)
+ Distance vers la destination #i en nombre de sauts (de 1 à 16). La valeur 16 indique une destination inaccessible.
Remarque : la valeur 0 nest pas utilisée.
LES AMELIORATIONS de RIP v2
Prise en compte du sous adressage
Authentification pour une meilleure sécurisation
Transmission multicast (224.0.0.9) plutôt que broadcast
Meilleure gestion des déclenchements déchanges pour éviter les pics de diffusion
FORMAT d'un MESSAGE RIPv2 (RFC 2453)
|
0 |
4 |
8 |
10 |
|
16 |
|
|
24 |
31 |
|
Commande |
Version |
Zéro |
|||||||
|
ID de famille dadresse ou 0xFFFF |
Marquage de Route ou Mode dauthentification |
||||||||
|
Adresse IP destination #1 |
|||||||||
|
Masque de sous-réseau |
|||||||||
|
Prochain saut |
|||||||||
|
Métrique vers destination IP #1 |
|||||||||
|
|
|||||||||
|
ou |
|||||||||
|
Mot de Passe (16 octets) |
|||||||||
+ Champ IDENTIFIANT de FAMILLE dADRESSE : (16 bits)
+ Sil vaut 0xFFFF, indique un message dauthentification.
+ Champ MARQUAGE ROUTE / MODE AUTHENTIFICATION: (8 bits)
+ Indique sil sagit dune route interne ou externe (compatibilité avec EGPs) dans le cas déchange de route, le mode dauthentification dans le cas dun message ayant le champ identifiant de famille à la valeur 0xFFFF (= 2 pour authentification par mot de passe, = 1/3 pour MD5 ).
+ Champ MASQUE de SOUS-RESEAU : (32 bits)
+ Masque de sous-réseau à appliquer à ladresse IP de destination
+ Champ PROCHAIN SAUT : (32 bits)
+ Adresse IP du prochain saut auquel les paquets à destination de celle mentionnée doivent être expédiés.
+ Champ MOT de PASSE : (128 bits)
+ Mot de passe dans le cas dune authentification.
Remarque : authentification possible avec MD5 (calcul dun sceau transmis avec les paramètres)
LES LIMITES RESIDUELLES
Apparition de boucles (convergence lente)
Métriques limitées
Pas de routage multiple
Davantage ciblé vers les réseaux locaux à diffusion
B/ Le protocole OSPF
OSPF : Open Shortest Path First(RFC 1247-1583-2178)
Caractéristiques générales
Protocole de routage « intérieur » inter-routeurs
De type « état de liaison »
Directement au dessus de IP
Messages multicast sur réseaux à diffusion
Routage multiple possible
Optimisation par décomposition en zones ou aires (areas) du système autonome
Authentification des messages
Adapté à tout type de réseau : diffusion, NBMA, point à point
Très performant, mais plus complexe
HIERARCHISATION SIMPLE en ZONES ou AIRES :
- Zone (ou area) = sous-partie dun AS délimitée par ladministrateur en fonction de la topologie du réseau :
- Un routeur à la frontière dune zone annonce une route par défaut et non toutes les routes apprises
- Chaque zone est représentée par un numéro de 32 bits
- Un réseau fédérateur (backbone) est obligatoire : toutes les zones doivent lui être contiguës.
- Possibilités de liaisons virtuelles (dans les cas où une zone nest pas adjacente au backbone mais à une autre zone).
ILLUSTRATION :
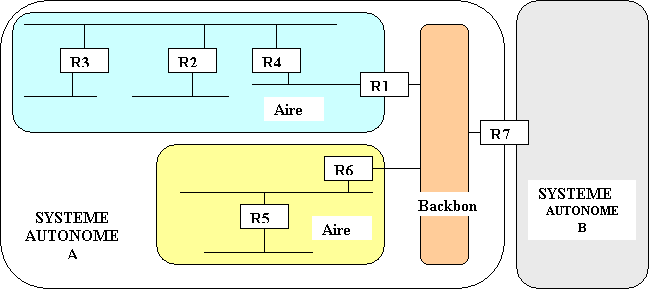
FORMAT de len-tête dun MESSAGE OSPFv2:
|
|
0 |
4 |
8 |
10 |
16 |
|
24 |
31 |
|||
|
Version |
Type |
Longueur Totale |
|||||||||
|
Identité du routeur source |
|||||||||||
|
Identificateur de Zone |
|||||||||||
|
Checksum |
Type authentification |
||||||||||
|
Authentification (8 octets) |
|||||||||||
+ Champ NUMÉRO de VERSION : (8 bits)
+ Numéro de version du protocole OSPF (2 actuellement)
+ Champ TYPE de MESSAGE : (8 bits)
+ Indique le type du message qui déterminera la structure des données émises après len-tête. Les différentes valeurs sont :
1 : message HELLO
2 : description dune base de données
3 : demande dun état des liaisons
4 : mise à jour de létat des liaisons
5 : acquittement reconnaissant un état de liaison+ Champ LONGUEUR TOTALE du paquet OSPF: (16 bits)
+ Champ IDENTITE du ROUTEUR SOURCE : (32 bits)
+ Identité du routeur émetteur fixée par ladministrateur (par convention ladresse IP le plus basse).
+ IDENTIFICATEUR dAIRE : (32 bits)
+ Identifiant de la zone sur laquelle le paquet est actif
+ Champ CHECKSUM sur len-tête: (16 bits)
+ Champ TYPE AUTHENTIFICATION : (16 bits)
+ Algorithme dauthentification utilisé
(0 - - >aucun, 1 - - > par mot de passe en clair, 2 - - > par MD-5).+ Champ Données dAUTHENTIFICATION : (64 bits).
Les DIFFERENTES Bases de DONNEES de ROUTAGE :
OSPF maintient plusieurs bases de données de routage (BDR) :
- Routes dans le réseau
- Tables de routage vers les autres réseaux du domaine
- Table de routage vers les autres AS
- Adresses des routeurs dans le cas dun réseau NBMA
Mises à jour par les mêmes protocoles
Les DIFFERENTES FONCTIONS :
Inondation des informations de routage dans une zone : les routeurs peuvent alors appliquer DIJSKTRA
(Types de message OSPF : 4 et 5)Diffusion des tables de routage construites à la frontière des zones : cacher la complexité dune zone aux autres
(Type de message OSPF : 4)Découverte des routeurs dune zone correspondant à un réseau NBMA (Non Broadcast Multiple Access)
(Types de message OSPF : 3 et 4)Synchronisation des informations : un routeur nouveau peut récupérer les informations sans attendre.
(Types de message OSPF : 2 et 3)Election de routeur désigné sur réseau à diffusion : simplifier le processus de synchronisation des données
(Type de message OSPF : 1)Surveillance des routeurs adjacents : détection de pannes
(Type de message OSPF : 1)
Le ROLE du sous-protocole HELLO :
- Surveillance de la topologie
- Election du routeur désigné
SURVEILLANCE de la TOPOLOGIE : OBJECTIF et PRINCIPE
+ Objectif : apprendre dynamiquement les modifications de la topologie (pannes).
+ Principe : Diffusion périodique de messages HELLO pour :
+ Se signaler comme toujours actif
+ Vérifier la connectivité bi-directionnelle
+ Au démarrage, dans un réseau à diffusion, détecter les routeurs voisins, le routeur désigné la mise à jour des BDR peut alors seffectuer.
ELECTION dun ROUTEUR DESIGNE : OBJECTIF et PRINCIPE
+ Objectif : réduire le nombre déchanges de messages de mises à jour des bases de données de routage (BDR).
+ Principe : Election dun routeur avec lequel dialoguent les autres pour la maintenance des BDR.
+ Algorithme délection : proche de celui de IEEE 802.5 pour lélection du moniteur (priorité la plus forte, si égalité, celui ayant la valeur identificateur la plus grande est élu)
FORMAT dun MESSAGE HELLO :
0
4
8
10
16
24
31
En-Tête OSPF / TYPE = 1
Netmask du routeur source
Intervalle démission
Options
Priorité
Intervalle de mort du routeur
Routeur désigné
Routeur désigné de secours
Routeur voisin #1
Routeur voisin #2
Routeur voisin #n
+ Champ NETMASK : (32 bits)
+ Masque de sous-réseau du routeur émetteur
+ Champ INTERVALLE dEMISSION : (16 bits)
+ Durée en secondes entre deux émissions de HELLO
+ Champ OPTIONS : (8 bits)
+ Caractérisation des capacités du routeur émetteur
DC
EA
N/P
MC
E
T
Quand le bit est positionné à 1 :
DC : apte à gérer des circuits à la demande (X.25, RNIS ).
MC : apte à traiter de lIP multicast.
E : apte à gérer des routes apprises par un protocole de routage externe.
T : apte à gérer le TOS (plus utilisé : 0 actuellement).+ Champ PRIORITE : (8 bits)
+ Utilisé pour la phase délection du routeur désigné (Si 0, le routeur émetteur ne participe pas à lélection (ex : au démarrage)).
+ Champ INTERVALLE de MORT : (32 bits)
+ Durée en secondes au bout de laquelle un routeur est considéré comme mort par lémetteur (dans le cas de non réception de message HELLO de sa part).
+ Champs ROUTEUR DESIGNE et de SECOURS : (2x32 bits)
+ Adresses IP du routeur désigné et de secours si élus et connus, 0.0.0.0. si non encore connus.
+ Champs ROUTEUR VOISIN #i : (nx32 bits)
+ Adresses IP des routeurs voisins que lémetteur a reconnu par écoute du trafic HELLO
Tout routeur qui na pas émis pendant la période de mort est sorti de cette liste.Remarque : Tout routeur qui reçoit un message HELLO et se trouve dans la liste des voisins est certain dune connectivité bidirectionnelle avec le routeur émetteur.
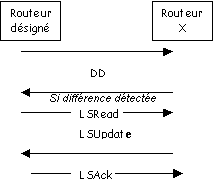
Les DIFFERENTS SOUS-PROTOCOLES sur les BDR :
Ces protocoles sopèrent entre « routeur » et « routeur désigné »
Ils permettent dapprendre la structure des bases de données en les décrivant (Database Description DD)
Demande détat des liaisons (LS Request)
Mise à jour détat des liaisons (LS Update)
Acquittement (LS Acknowledge)
Scénario classique :
- Exemple : FORMAT dun MESSAGE D-D :
+ Champ MTU : (16 bits)
+ MTU de linterface démission
+ Champ OTPIONS : (8 bits)
+ Idem paquet HELLO
+ Champ FLAGS : (8 bits)
+ Gestion dun dialogue :
I
M
MS
+ Quand le bit est positionné à 1 :
I : premier paquet de la description (Initial)
M : dautres paquets suivent (More)
MS : le routeur émetteur est le maître, le récepteur lesclave.+ Champ NUMERO de SEQUENCE : (32 bits)
+ Numérotation unique, incrémentée par le maître
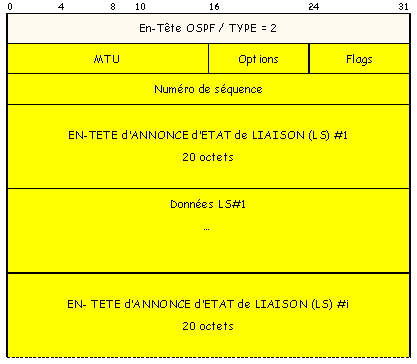
Format du Champ En-Tête dAnnonce : (160 bits)
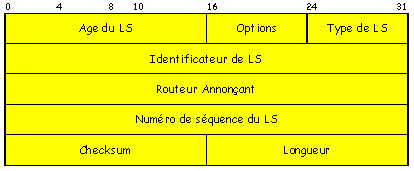
+ Champ AGE du LS : (16 bits)
+ Age de linformation annoncée (synchronisation sur la pérennité des informations)
+ Champ OPTIONS : (8 bits)
+ Idem paquet HELLO
+ Champ TYPE du LS : (8 bits)
+ Donne la nature de linformation :
1. liaison du routeur
2. liaison dans le réseau (réseau NBMA)
3. liste des adresses des réseaux accessibles
4. résumé des adresses des routeurs externes
5. réseaux externes accessibles appris par un EGP
6. routage multicast (RFC 1584)
7. réseaux externes particuliers et accessibles (RFC 1587)+ Champ IDENTIFICATEUR de LS : (32 bits)
+ Diffère selon la valeur du champ type LS. Si type vaut :
1. Identifiant du routeur producteur du messager
2. Adresse IP du routeur désigné
3. Adresse du réseau accessible
4. Identifiant du routeur frontière
5. Adresse du réseau externe+ Champ ROUTEUR ANNONCANT : (32 bits)
+ Identifiant du routeur émetteur de lannonce D-D
+ Champ NUMERO de SEQUENCE du LS : (16 bits)
+ Estampillage du LS (éliminer les duplicatas lors dune inondation, opérer ou non une mise à jour dans la BDR)
+ Champ CHECKSUM : (16 bits)
+ Checksum sur len-tête dannonce.
+ Champ LONGUEUR : (16 bits)
+ Longueur des données qui suivent
+ Champ DONNEES :
+ Information dont le format dépend du type dEL
EIGRP : Enhanced Interior Gateway Routing Protocol (CISCO)
Caractéristiques Générales
Protocole propriétaire, fonctionne sur IP, IPX, AppleTalk
Protocole de routage « intérieur »
Combinaison des avantages « vecteur distance » et « état de liaison »
Valeurs de métriques distinctes :
- Bande passante (par défaut) (fonction du type de linterface)
- Délai
- Fiabilité (par calcul dynamique)
- Charge (calcul moyenne pondérée continue)
Routage multiple possible
Sous-adressage et synthèse de routes possible :
Convergence obtenue grâce à lalgorithme DUAL (Diffusing Uptade Algorithm) :
- Un routeur mémorise les Tables de Routage de ses voisins
- Si pour une destination, un routeur ne dispose pas dun tel itinéraire, envoi dune requête aux voisins qui se propage jusquà lobtention dun itinéraire
- En cas de changement dune TR, seules les modifications sont envoyées et uniquement aux routeurs concernés
- Gestion des meilleures métriques
![]()
![]()
Les Protocoles de Routage Externe
Lobjectif du routage au sein dun AS est surtout déviter la perte de connectivité : lessentiel est dobtenir une route possible. La constitution de cette route est relativement peu importante dans la mesure où, quelle quelle soit, elle implique toujours les équipements dun même système autonome.
Celle-ci devient par contre primordiale dans une perspective de routage entre AS. Il sagit là davantage dun « routage politique ». En effet, le fait dannoncer une route implique que lAS accepte de véhiculer des informations vers cette destination et est capable de joindre cette destination annoncée.
Ces annonces peuvent être supportées par un EGP. Toutefois, il est toujours possible dans le cas du routage entre AS de mettre en place un routage statique. Voici quelques détails sur le dernier standard des EGPs : le protocole BGP.
BGP : Border Gateway Protocol V4 (RFC 1771)
Caractéristiques Générales
Protocole de routage externe : entre Systèmes Autonomes
Agrégation de routes : prise en compte de CIDR (Classless Inter Domain Routing) ou adressage sans classe
- 193.55.64.0
- 193.55.65.0
- 193.55.66.0
- 193.55.67.0
-
BGP utilise le port 179 de TCP : lassociation étant forcément point à point en EGP dans le cas du routage externe, le protocole travaille sur une connexion (pas de mécanisme de diffusion nécessaire)
Authentification des messages
Version dun protocole « interne » iBGP
BGP utilisé soit par des sites multi-domiciliés, soit par des IAP (Internet Access Provider).
Les différents types de messages BGP :
Messages douverture :
Destinés à établir une connexion identifiée, authentifiée précisant quelques paramètres entre les deux routeurs EGP.(Type de message BGP : 1)
Messages de mise à jour :
Permettent déchanger des informations de routage (NLRI : Network Layer Reachability Information)
Les messages sont découpés en deux parties :
- les routes à retirer (étant devenues non valides)
- les routes valides et des attributs.(Type de message BGP : 2)
Messages de notification :
Permettent de signaler une erreur et provoque la fermeture de la connexion(Type de message BGP : 3)
Messages de sonde :
Emis périodiquement pour informer du bon état de la liaison et du routeur émetteur (en-tête seul)(Type de message BGP : 4)
BGP interne :
Dans la pratique il est courant que plusieurs routeurs « frontière » dun même AS (celui dun ISP par exemple) dialoguent chacun indépendamment avec des routeurs dautres AS. Le problème est alors de mutualiser les routes apprises par lensemble de ces routeurs : chacun doit communiquer les annonces quil a apprises de son côté et récupérer celles des autres afin de les annoncer à son tour au routeur de lAS qui le concerne. Ces routeurs vont pouvoir utiliser BGP de façon interne à lAS.
Illustration :
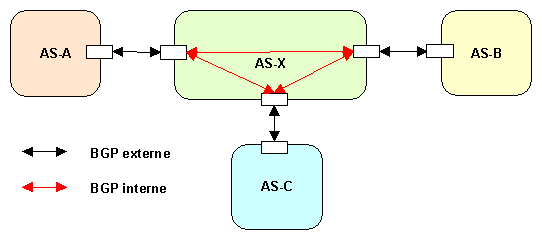
Remarque :
Il est important dassurer une synchronisation entre les versions externes et internes de BGP. Il faut attendre davoir eu connaissance des routes par le protocole interne avant denvoyer celles-ci par le protocole externe.
Les attributs :
Des attributs constituent des informations transportées dans des messages BGP à la fois pour assurer un bon déroulement du protocole et pour permettre la sélection des routes en cas dannonces de routes identiques.
A titre dexemple, voici quelques attributs définis dans BGP :
- ORIGIN :
origine de linformation apprise par le routeur annonçant la route :
1 : route apprise par lAS du routeur annonçant (par un IGP)
2 : route apprise par un EGP
3 : route apprise autrement (configuration statique)- AS PATH :
liste (ordonnée ou non) des AS dont les routeurs ont annoncé cette route à un autre AS : à chaque envoi vers un routeur dun autre AS le routeur émetter rajoute le numéro dAS dans ce champ. Si plus tard, ce même routeur reçoit un message contenant lannonce dune route avec son numéro dAS apparaissant dans cette liste, il en déduit que le paquet dannonce boucle et ne le considère pas.- NEXT HOP :
adresse IP du prochain routeur sur la route annoncée (en principe lémetteur).- MULTI_EXIT_DISC :
facultatif et utilisé entre deux AS connexes, il permet dans le cas où il existe plusieurs routeurs « frontières » dun AS, dindiquer une préférence pour une route (plus la valeur est petite, plus la préférence est grande).- LOCAL_PREF :
analogue au précédent mais permet à lAS recevant de lexploiter dans liBGP.
![]()