Apport des ontologies pour la recherche d’information
Plan :
Cadre général
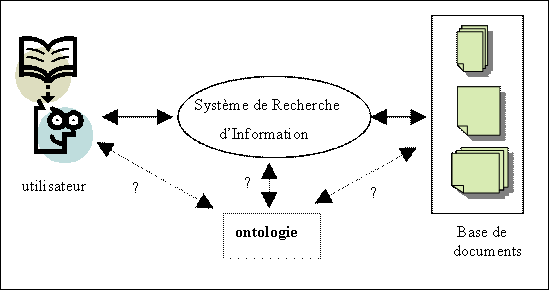
Dans cette session, nous étudions l’apport des ontologies pour la recherche d’information dans une base documentaire. Le cadre général que nous considérons est le suivant (cf. figure 1) :
FIG 1 – Cadre général de l’étude
Ce cadre général couvre la recherche d’information sur le Web. Quiconque a déjà utilisé des moteurs de recherche sur le Web a immanquablement été confronté à des réponses volumineuses contenant des documents n’ayant aucun rapport avec ses attentes. On comprend dès lors que l’amélioration des performances de ces moteurs de recherche soit un souci des concepteurs du Web.
Les ontologies constituent pour cela une technologie jugée prometteuse. Nous allons voir que différentes utilisations des ontologies peuvent être envisagées. Dans cette session, deux scénarios, parmi les plus courants, sont examinés. L’ensemble de ces utilisations relève de ce qu’on nomme aujourd’hui le « Web sémantique ».
Indexation conceptuelle
Un des problèmes de l’indexation actuelle des documents par des mots, ou groupes de mots, est de ne pas permettre de prendre en compte les phénomènes de la langue que sont la synonymie et l’homonymie :
Pour pallier ces problèmes, la solution consiste à indexer les documents par des concepts, tout en conservant les liens : concept/terme(s). Cette solution se situe dans la droite ligne des pratiques des documentalistes qui exploitent déjà des « thésaurus » - des ensembles structurés de termes – pour indexer des documents. Le thésaurus est remplacé par une ontologie, un ensemble structuré de concepts.
Pour montrer l’apport d’une indexation conceptuelle, nous distinguons, d’une part, l’exploitation des liens : concept/terme(s), et d’autre part, l’exploitation des relations sémantiques structurant l’ontologie. Dans ce qui suit, nous considérons que l’utilisateur continue à employer des mots dans ses requêtes.
Grâce à l’utilisation des liens : concept/terme(s), nous pouvons attendre le comportement suivant du SRI :
Grâce maintenant à l’exploitation de la structure de l’ontologie, c’est-à-dire à la prise en compte des relations existant entre concepts, on peut attendre du SRI cet autre comportement :
En résumé, l’apport d’une ontologie dans le cadre d’une indexation conceptuelle est double :
Ajout, aux documents, de « méta-données »
L’indexation conceptuelle, que nous venons de voir, revient à indexer les documents par leur contenu, puisque les concepts composant l’index sont sensés correspondre à des concepts présents dans les documents. D’autres informations, cependant, se révèlent utiles pour retrouver un document et jouer ainsi le rôle d’index : son titre, le nom de son (ou ses) auteur(s), sa date de publication, la langue dans laquelle il est écrit, etc.
Ces informations, qualifiées parfois de contextuelles (pour marquer l’opposition au contenu), portent le nom de « méta-données ». Le préfixe « méta » signifie que ces informations ne concernent pas le sujet traité dans le document mais qu’il s’agit de données portant sur le document lui-même. Ces méta-données peuvent être, suivant les technologies utilisées, intégrées dans le document, ou bien rassemblées en dehors des documents, dans une base de méta-données jouant le rôle d’un catalogue de bibliothèque.
L’importance de ces méta-données explique, du reste, qu’elles aient fait l’objet de travaux de normalisation, conduisant à des propositions de standards. Un des standards les plus utilisés est Dublin Core, qui émane d’une association internationale de bibliothécaires. Dublin Core (http://dublincore.org/) repose sur :
L’enjeu de cette ontologie est de permettre à une large communauté d’utilisateurs de partager la signification de ces éléments, de façon à les utiliser correctement. Les utilisateurs de l’ontologie étant en premier lieu des êtres humains, et non des machines, l’ontologie Dublin Core est spécifiée en langue naturelle. Compte tenu de la portée internationale de cette ontologie, des définitions en langue naturelle existent dans plus de 20 langues incluant le finnois, le norvégien, le thaï, le japonais, le portugais, l’allemand et, bien sûr, le français.
En figure 2 est présenté un extrait de l’ontologie Dublin Core en français (traduction d’Anne-Marie Vercouste, Inria). Pour la plupart des éléments, Dublin Core propose une liste de valeurs possibles. Ces listes font référence à d’autres standards existants, par exemple aux normes ISO définissant des codes pour les noms de pays et de langues. Chaque définition est d’autre part accompagnée d’un commentaire pour préciser le sens de certains termes, ou donner des exemples à titre d’illustration.

FIG 2 – Extrait de l’ontologie de Dublin Core
Bien entendu, ces méta-données sont faites également pour être utilisées par des moteurs de recherche. Un SRI exploitant ces méta-données présente un comportement analogue aux moteurs de recherche associés aux systèmes de gestion de fichiers : l’utilisateur se voit ainsi proposer le choix du (ou des) élément(s) pour effectuer sa recherche.
Implémentation, en DefOnto, d’un SRI
Dans cette section, nous voyons le principe d’une implémentation en DefOnto d’un SRI suivant l’approche des méta-données. DefOnto permet de représenter des méta-données et leur sémantique – l’ontologie – associée. L’objet de cette section est d’illustrer, à partir d’un exemple simple, le second apport de l’ontologie, une fois représentée dans un langage opérationnel comme DefOnto. L’ontologie opérationnelle permet en effet de déduire des informations implicites à partir des méta-données.
L’utilisation des constructions de DefOnto est directe :
Cette répartition des rôles est illustrée dans les figures 3, 4 et 5, qui présentent un exemple simple.
Il reste à voir comment un SRI peut interroger le contenu des méta-données. DefOnto dispose pour cela d’un langage de requêtes. Ce langage comporte deux types de « filtres », des filtres « conceptuels » et des filtres « relationnels », dont la syntaxe (la notation) et la sémantique (comment ils sont évalués) sont les suivants :

FIG 3 – Représentation d’un document, décrit au
moyen de trois éléments, et d’une personne

FIG 4 – Représentation des concepts LIVRE et AUTEUR
Voyons maintenant comment l’ontologie est exploitée. Lors de l’évaluation de filtres, l’ontologie est utilisée pour réaliser des inférences. Nous illustrons ce rôle sur deux exemples.
Exemple 1
Requête : [Document *x] ; réponse : *x Î {LivreTBL}
Le lien de subsomption entre les concepts Livre et Document permet d’inférer que, comme LivreTBL est un Livre, c’est également un Document.
Exemple 2
Requête : [Auteur *x] ; réponse : *x Î {TimBernersLee}
Pour produire cette réponse, deux inférences sont réalisées. D’une part, comme LivreTBL aPourAuteur TimBernersLee et que les relations aPourAuteur et estAuteurDe sont inverses, le SRI déduit que TimBernersLee estAuteurDe LivreTBL. D’autre part, comme un Auteur est une Personne qui estAuteurDe Documents et que TimBernersLee est justement une Personne qui estAuteurDe un Document (puisque un Livre est un Document), TimBernersLee est bien un Auteur. CQFD !

FIG 5 – Représentation des relations A POUR AUTEUR et TITRE
Dans les deux exemples, l’ontologie a permis d’inférer des informations qui n’étaient pas explicites dans les méta-données.
Exercices
Exercice 1
L’indexation de documents rédigés dans des langues différentes est aujourd’hui devenu une nécessité, que ce soit sur le Web ou sur les intranets de sociétés multinationales. Proposer une technique, fondée sur l’indexation conceptuelle, permettant d’indexer une collection de documents multilingue.
Solution de l’exercice 1
La technique consiste à considérer les termes appartenant à des langues différentes et étant la traduction l’un de l’autre (ex : « voiture », « car », « wagen ») comme des termes synonymes exprimant une même notion (cf. figure ci-dessous).
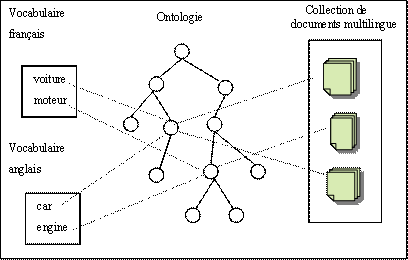
Note : cette proposition d’une « synonymie étendue » repose sur l’hypothèse que les concepts sont indépendants de la langue. Bien qu’une telle hypothèse soit théoriquement réfutée par les linguistes, en pratique elle donne de bons résultats.
Exercice 2
L’objet de cet exercice est d’indexer, au moyen d’une ontologie, trois documents : les trois lois de la robotique (Isaac Asimov, 1950) :
Première Loi
Un robot ne peut nuire à un être humain ni laisser sans assistance un être humain en danger.
Deuxième Loi
Un robot doit obéir aux ordres qui lui sont donnés par les êtres humains, sauf quand ces ordres sont incompatibles avec la Première Loi.
Troisième Loi
Un robot doit protéger sa propre existence tant que cette protection n’est pas incompatible avec la Première ou la Deuxième Loi.
Pour cela, on procèdera en deux étapes :
1) Déterminer les concepts présents dans chacun des documents.
2) Placer ces concepts dans la taxinomie des concepts généraux extraite de SUMO (présentée dans une session précédente), au moyen de liens de spécialisation. Ceci revient à caractériser – en partie – ces concepts.
Note : on laissera toutefois de côté la notion d’« incompatibilité », présente la Deuxième et la Troisième Lois, qui ne peut être définie à partir de ce petit nombre de concepts génériques.
Solution de l’exercice 2
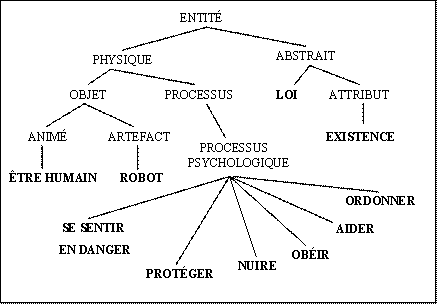
Première étape : nous avons exprimé les concepts d’action au moyen d’un verbe (considéré comme le terme vedette) et d’un substantif (considéré comme terme synonyme).
Ensemble des concepts pour la Première Loi : {robot ; nuire/nuisance ; être humain ; aider/assistance ; danger}
Ensemble des concepts présents dans la Deuxième Loi : {robot ; obéir/obéissance ; ordonner/ordre ; incompatibilité ; loi}
Ensemble des concepts présents dans la Troisième Loi : {robot ; protéger/protection ; existence ; incompatibilité ; loi}
Deuxième étape : les actions sont considérées comme des processus psychologiques, même si elles ont pour agent un robot ! l’existence est considérée comme un attribut d’un robot.
Test
Concernant l’indexation conceptuelle
Dans le cadre de l’indexation conceptuelle, les documents sont indexés par rapport à :
Concernant les méta-données
Le rôle des ontologies dans la mise en œuvre des méta-données se limite à :
Réponses au test
Dans le cadre de l’indexation conceptuelle, les documents sont indexés par rapport à :
Le rôle des ontologies dans la mise en œuvre des méta-données se limite à :
3. autre. Comme on l’a vu dans le cours, l’ontologie joue bien un double jeu, c’est-à-dire qu’elle permet d’aider des personnes à spécifier des méta-données et d’aider des agents logiciels à réaliser des inférences à partir de ces méta-données. Ce double jeu est à l’image du Web sémantique dont un des enjeux principaux est de « faire sens » à la fois pour des êtres humains et des machines. Pour en savoir plus, il est conseillé de lire le livre … présenté en figure 3.