Les éléments de biographie de Marvin Minsky et de Roger Schank sont tirés de[Cre93 CREVIER 1993].
[MINSKY
1975]
[En
savoir plus sur Marvin Minsky]
La section suivante de ce chapitre présente ce que nous considérons comme l’apport principal de Minsky dans la représentation de connaissance. Nous suivons le plan de son article [MINSKY 1975].
Marvin MINSKY remarque que les approches faites en Intelligence Artificielle pour élaborer des théories sont trop « précises », locales et non structurées pour servir de support au raisonnement sur le monde réel. Il distingue plusieurs approches dans les travaux de l’intelligence artificielle et de la psychologie cognitive :
· la proposition commune qu’il fait avec Papert, pour diviser la connaissance en sous-structures qu’ils appellent les micromondes,
· a définition « d’espaces problèmes » selon Newell et Simon,
· ’expression d’objets linguistiques selon Schank, Abelson et Norman.
Ces approches lui semblent plus prometteuses et se différenciant des approches traditionnelles faites d’une part en psychologie et d’autre part en Intelligence Artificielle ( qui tentent de décrire la connaissance comme un agrégat de morceaux séparés les uns des autres).
L’essentiel de la théorie développée par Marvin Minsky à cette occasion aboutit à la notion de « frame » que nous avons un peu de mal à traduire de manière unique en français, ce qui amène la plupart des chercheurs à garder ce terme de frame, même si le mot « cadre » pourrait convenir. Le mot cadre doit se lire avec le sens de contexte même si en pratique il s’agit d’une structure de représentation de connaissances. Minsky développe son cheminement de la manière suivante :
Quand on rencontre une nouvelle situation (décrite comme un changement substantiel à un problème en cours), on sélectionne de la mémoire une structure appelée « cadre » (frame). Il s’agit d’une structure remémorée qui doit être adaptée pour correspondre à la réalité en changeant les détails nécessaires.
Un cadre est une structure de donnée pour représenter une situation stéréotypée reconnue comme s’appliquant au problème (dans une certaine mesure).
Les informations sont réparties en trois champs :
· une partie de l’information concerne son usage,
· une autre partie concerne ce qui peut arriver ensuite (c’est à dire décrit le scénario possible de poursuite) ,
· une autre partie encore concerne ce qu’il convient de faire si ce qui était prévu ne se déroule pas.
Un cadre peut être vu comme un réseau de noeuds et de relations entre ces noeuds ( réseau sémantique).
Figure 1—1 Cadre = Réseau de noeuds et de relations ; Les sommets sont toujours vrais, les éléments terminaux sont connectés à tous les points de vue.
Les niveaux sommet sont fixés et représentent les choses qui sont toujours vraies, tandis que les niveaux les plus bas comportent de nombreux emplacements qui doivent être garnis par des instances spécifiques ou des données. Chaque emplacement terminal peut spécifier les conditions à remplir pour lui affecter une information. (Ces informations sont souvent des cadres plus petits). Les collections de cadres sont reliées par des liens d’interdépendance. Les effets de modifications importantes sont représentés par des transformations inter-cadres. Ces informations sur les transformations ( qui caractérisent en fait les distinctions entre cadres) sont utilisées pour mesurer le degré ‘d’évocation’ du cadre par une situation.( au sens analogique donc).
Par exemple, pour l’analyse de scène visuelle, les différents cadres d’un système décrivent la scène selon plusieurs points de vue et les transformations entre un cadre et un autre représentent les effets de déplacement d’un point à l’autre.
Les différents cadres d’un même système partagent les mêmes emplacements terminaux. C’est le point critique qui rend possible la mise en correspondance d’informations recueillies selon différents points de vue. La plus grande part du pouvoir phénoménologique de la théorie s’articule autour de l’inclusion d’attentes et autres suppositions dans le cadre lui-même permettant donc en théorie de découvrir des différences entre ce qui est rencontré et ce qui était prévu et d’apprendre de l’épisode. Les emplacements terminaux d’un cadre sont donc garnis normalement avec des valeurs par défaut. Ces affectations par défaut sont attachées « faiblement » aux emplacements terminaux de telle façon qu’ils puissent être facilement remplacés par des éléments nouveaux. Ils peuvent alors servir comme variables ou comme cas spéciaux pour raisonner par l’exemple, ce qui rend souvent inutile l’usage de quantificateurs logiques.
Les systèmes de cadres sont reliés entre eux par un réseau de recherche d’information qui sera exploité pour trouver le cadre le plus adapté à la situation observée. En cas d’échec à retrouver un cadre correspondant à la réalité, le système propose un cadre général de remplacement. Les liens intercadre rendent possible la représentation des connaissances à propos des faits, des analogies et d’autres informations utiles pour la compréhension
Quand un cadre est proposé pour représenter une situation, un processus de mise en correspondance essaye d’affecter des valeurs à chaque terminal de cadre, cohérents avec les repères en place. Le processus de mise en correspondance est en partie contrôlé par l’information associée avec le cadre ( qui capte l’information permettant le processus de découverte), et en partie par la connaissance sur les objectifs courant du problème.
Marvin Minsky analyse les approches respectives des psychologues et des spécialistes de l’Intelligence Artificielle pour adopter une attitude « raisonnable pour permettre un raisonnement robuste », en proposant de se concentrer sur les notions de « suffisance » et d’« efficacité » plutôt que sur celle de « nécessité ». Cette position l’amène à éviter de réduire la résolution de problème à un nombre restreint de méthodes tout en renonçant à énoncer toutes les procédures possibles. Ces deux extrêmes seraient les défauts respectifs des approches des psychologues et des spécialistes de l’intelligence artificielle.
Marvin Minsky propose la notion « d’exception » pour réagir si on doit abandonner un cadre idéal impossible à instancier. Une exception est une explication de l’abandon, et pourra être utilisée pour éviter d’utiliser ce cadre dans d’autres situations ou l’excuse serait valable.
Le repérage d’une information se fait par l’intermédiaire d’une hiérarchie ( à la manière d’une adresse postale...), et les regroupements sont reliés par les différences qui les séparent. L’acquisition de nouvelles connaissances dépend essentiellement d’acquisition extérieures ( les mots d’une langue, le comportement d’un objet, ce qui est dit par un professeur, la famille, la culture...).
Marvin Minsky fait remarquer les exceptionnelles qualités de l’homme pour corriger ses erreurs avec le processus suivant généralement mis en oeuvre :
· faire une première tentative ( type raisonnement du premier ordre) en assemblant les procédures qui séparément satisfont les buts individuels.
· si quelque chose ne va pas, essayer de caractériser un des défauts comme une sorte d’interaction indésirable entre deux procédures.
· appliquer une technique de correction qui selon ce qui se trouve en mémoire se révèle utile pour réparer ce type d’interaction.
· synthétiser l’expérience pour l’ajouter à la bibliothèque de techniques de réparation.
Ceci peut sembler simpliste mais si le nouveau problème n’est pas trop radicalement différent des anciens, ça a toutes les chances de fonctionner, surtout si on a gardé les approximations convenables au moment du raisonnement du premier ordre.
Marvin Minsky assure que l’approche logique ne peut pas fonctionner en Intelligence Artificielle (rien de moins !). L’ensemble des axiomes et des règles d’inférence qui mènent à la conclusion doivent en effet être connues.
Cette approche logique pose des problèmes quasi insurmontables à chaque étape :
· formaliser la connaissance requise,
· vérifier la pertinence,
· respecter la monotonicité,
· contrôler la connaissance ( par exemple la transitivié limitée de certaines règles, pour éviter des raisonnements qui par l’application d’une règle de proximité rendraient équivalents 0 et 1000, au prétexte que 0 serait proche de 1, que 1 serait proche de 2, etc. et que si X est proche de Y et Y proche de Z alors X proche de Z! Cet écueil est bien connu quand il s’agit de d’indiquer que les derniers élèves d’une promotion méritent ou non un diplôme. Il n’a que 0,01 point de moins que X qui lui a eu son diplôme.!..)).
Pour résumer le point de vue de Minsky :
1. Le raisonnement logique n’est pas
assez flexible
pour servir de base à
2. Marvin Minsky doute de la possibilité pratique de représenter la connaissance ordinaire sous une forme synthétique de propositions indépendamment vraies.
3. La stratégie de séparation complète de connaissances spécifiques depuis les règles générales d’inférence est beaucoup trop radicale. Nous avons besoin de liens directs entre les morceaux de connaissances pour savoir comment ils doivent être utilisés.
4. On a longtemps cru qu’il était crucial de rendre la connaissance accessible sous la forme d’instructions déclaratives, mais ceci semble moins vrai au fur et à mesure que nous apprenons à manipuler les descriptions structurelles et procédurales.
Pour
Marvin Minsky :
«
thinking begins first with suggestive but defective plans and images
that are
slowly (if ever) refined and replaced by better ones ».
L’avis assez radical de Marvin Minsky a provoqué des réactions de justifications de l’approche logique aussi catégoriques (Mac Carthy, Mac Dermott par exemple) et n’est pas très productive. Notre point de vue est qu’il est possible d’utiliser la logique en intelligence artificielle lorsque la connaissance est bien établie, peu sujette au contexte et qu’elle peut être alors assimilée à une théorie du domaine. Le processus d’adaptation d’un schéma ou d’un exemple sera d’autant plus crédible qu’il s’appuiera sur une théorie solide mettant en oeuvre des processus déductifs,. Il reste que nous partageons l’avis énoncé qu’il y a peu de situations du Monde Réel ou un système de logique pure suffit pour y raisonner efficacement.
[SCHANK 1982][SCHANK et al. 1989]
Les premiers objectifs de Schank et son équipe, quand ils ont fait émerger la notion de raisonnement basé sur les cas, concernaient la compréhension d’ « histoires » énoncées en langage naturel. L’hypothèse fondamentale est que la compréhension du texte s’appuie sur des « schémas » mentaux qui comblent les vides laissés naturellement par l’expression en langage naturel. Le concept est résumé par la phrase de Schank : « Comprendre c’est expliquer ». Autrement dit, le processus de compréhension correspond à un processus d’explication qui s’applique de manière itérative comme dans la compréhension de la phrase suivante :
« Jean est allé au restaurant. Il a commandé du jambon. C’était bon. » .
La compréhension de cette phrase fait appel aux connaissances préalables qui permettent d’expliquer ce qu’il se passe globalement et entre chaque segment énoncé. Les connaissances sur le restaurant permettent de savoir quels sont les comportements habituels dans un restaurant - Entrer, Etre placé, Commander un plat, Etre servi, Manger, Régler la note, Quitter le lieu. La description de ce comportement conventionnel est appelé « script » par Schank. Ces connaissances « remplissent » les vides laissés entre l’énoncé - Jean est allé au restaurant - et l’énoncé - il a commandé du jambon - et explique - c’était bon - puisqu’il est là pour manger. Ce script ne pourrait pas s’appliquer directement si Jean allait dans une charcuterie car il n’est pas habituel de consommer ses achats sur place dans ce type de magasin. Toutefois une généralisation des scripts concernant « les commerçants » pourrait être faite à partir de ces deux exemples.
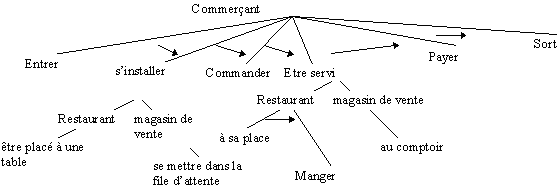
Figure 1—2 Exemple de Script pour le Restaurant
Le script décrit un épisode selon un comportement conventionnel découpé en événements qui se succèdent selon un ordonnancement décrit par l’ordre d’apparition attendu de ces événements. Notre connaissance générale sur les diverses situations rencontrées serait représentée sous forme de schémas mentaux qui nous permettent de prévoir ce qu’il doit se passer « normalement » dans le cours d’une histoire ou même dans la vie courante. Des exceptions à ces situations conventionnelles sont ajoutées au schéma lorsqu’il s’avère inadapté. A la prochaine occasion où cette exception sera rencontrée, elle sera reconnue et traitée selon le sous-schéma qui avait résolu le précédent épisode. Les schémas tels qu’ils viennent d’être décrits sont simplistes pour la clarté de la présentation, mais ils doivent être complétés par de nombreuses informations qui vont les nuancer et les adapter au fur et à mesure de l’expérience acquise. Les principales informations généralement retenues pour préciser ces schémas sont :
· les buts poursuivis,
· les plans mis en oeuvre,
· les relations « sociales »,
· les rôles joués,
· les « traits de caractère »,
· et d’une manière générale tout ce qui peut jouer sur le comportement dans la mise en oeuvre du schéma correspondant à la situation.
Ces informations interviennent donc comme autant
d’explications du comportement observé, puisqu’elles expliquent
en quoi les
événements qui se produisent ont une
« logique » dans
Comment construit-on les premiers schémas? Cette question reste ouverte, mais la réponse la plus fréquemment apportée concerne l’acquisition passive d’une première expérience « guidée » qui servira de modèle pour les autres[WINSTON 1988].
Comme on le voit, l’approche de Schank est au
départ très
directement inspirée de celle de Minsky et les principes
cognitifs sous-jacents
sont largement conservés. Ce qui est différent, c’est
l’usage qui est fait des
expériences concrètes dans
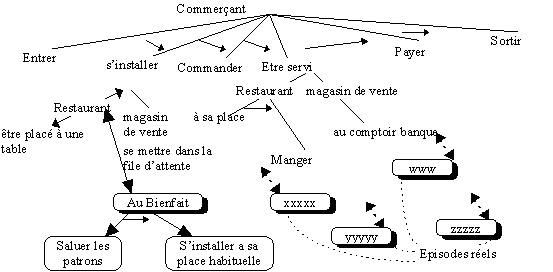
Pour permettre l’évolution dynamique des scripts représentant les schémas, l’équipe de Schank a proposé le concept de mémoire dynamique permettant la gestion de telles connaissances. La mémoire est présentée comme un réseau dense d’expériences ( les épisodes) au degré de généralité varié mais capable de repérer les expériences originales dans leur état « natif » . Ce modèle a été rendu opérationnel au moyen des Memory Organization Packets (MOPS) proposés et implantés par l’équipe de Schank[SCHANK et al. 1989].
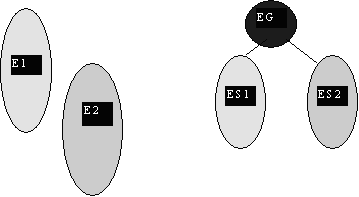
Très schématiquement, le principe d’autoorganisation des MOPS est le suivant :
|
|
Les épisodes E1 et E2 sont combinés pour former un épisode général EG relié à des épisodes spécialisés ES1 et ES2 par un « index » discriminant les deux situations. |
Figure 1—3 Principe de base de la généralisation d’épisode
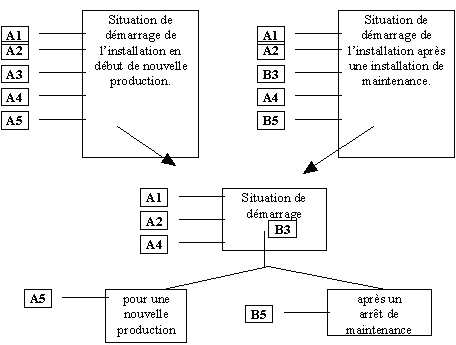
Les schémas suivants proposent une illustration de ce principe sur un exemple emprunté au domaine d’application de la supervision industrielle.
|
|
Les deux situations de démarrage partagent des attributs communs ( attribut doit être interprété ici au sens très large de caractéristiques, événements etc..), sont discriminés par B3 et les spécificités A5 et B5 sont attachées aux feuilles qui spécialisent l’épisode général de démarrage d’installation. |
Figure 1—4 Illustration du principe de généralisation sur une situation de démarrage d’installation
Beaucoup d’autres travaux ont ensuite complété ces approches fondatrices, mais les concepts de base étaient établis, le modèle cognitif est resté le même, tandis que l’approche « Intelligence Artificielle » s’est emparée de ce paradigme pour la résolution de problème et pour l’interprétation.