Image understanding: integrating both domain knowledge and Gestalt vision
Indexing systems, allowing users to find images which are relevant to their queries are therefore strongly needed. Nowadays, a lot of content-based systems have come out, describing an image with low-level features such as color, texture or even shape of one main object. However, such systems are usually not relevant as one may search an image based on what it depicts (its semantics) and not on its color or textural aspect.
Trying to extend content-based tools in order to derive semantics from low-level features may be impossible without any prior knowledge, since such a link does not exist without any ambiguity. This is what is often called the semantic gap.
Thus, we need to integrate additional knowledge related to the application domain, in order to find what a part of a picture is likely to depict in a given context.
A lot of knowledge-based image understanding systems is available. For instance SIGMA [1] or Schema [2] perform image understanding tasks on aerial images, based on several descriptions of objects which are bound to appear. Other works such as [3] deal with object recognition in macroscopic or microscopic biological images.
Nevertheless, as pointed out by [4] such systems are strongly domain-dependent as they integrate prior knowledge about the scene or several objects in the algorithms of image understanding. In fact, the domain knowledge is not clearly separated from the procedures.
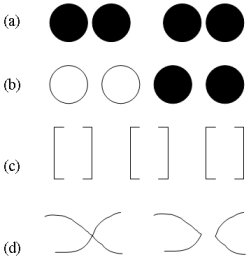
That's why some works have risen about generic grouping algorithms: some of them try to group altogether some regions of a segmented image, regardless of any domain of application, based on the maximization of the groupings' likelihood [5]. Most of time though, Gestalt theory [6] is used, which argues that human vision performs domain-independent groupings (called Gestalts) based mainly on five properties: proximity, similarity, closure, continuity and symmetry (See Figure 1).
Some properties of Gestalt vision: patterns are likely to be group according to proximity (a), similarity (b), closure (c) and good continuation (d).
Generic Framework
These may reflect some statistical regularities of our visual environment. Thus, [7] and [8] implement a Gestalt-based grouping process of segment lines. In [7], gestalts' relevance is evaluated by the Dempster-Schafer theory of evidence, while [8] controls them using Markov Random Fields. In both cases however, the generic grouping algorithm is totally disconnected from the knowledge about objects it handles.
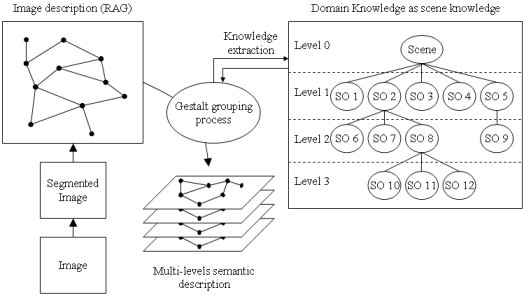
On the contrary, we argue that an image understanding system should be aware of (though not fully dependent on) what it treats. Consequently, we propose a generic process of grouping segmented regions, under the control of domain knowledge. Thus, the system is able to interface with different domain knowledge, depending on the image under treatment, and can extract from it all information needed to assist the grouping task.
Such domain knowledge is modeled by ontology and should easily be mapped into the region-based description (that is a topological graph with additional descriptors). That's why domain knowledge should be modeled as scene knowledge, dealing about how objects appear in images. Besides, considering that semantic objects do not all deal with the same level of details (some are global components of the scene while others are more detailed components), a given object is not relevant at all levels of details and should thus not be perceived at all levels. Consequently, we model the notion of scene composition, in order to structure the scene. Hence, semantic objects are organized at different levels. Grouping process will then be performed at each level of the hierarchy, from the most global and then recursively at each sub-level. This process provides a finer context at each level of understanding and also leads to a multi-level description of the image.
More information
Research Report RR-2004-003 PDF Master of Science Report on knowledge representation for image understanding (in french)PDF
[1] T. Matsuyama, V. Hang, SIGMA: A Framework for Image Understanding Integration of Bottom-up and Top-down Analyses, Plenum, New-York, 1990.
[2] B. Draper, A. Colins, J. Brolio et al, "The Schema System", International Journal of Computer Vision, Vol. 2(3), pp. 209-250, 1989.
[3] C. Hudelot, M. Thonnat, "An Architecture for Knowledge-Based Image Interpretation", Workshop on Computer Vision System Control Architecture, Austria, 2003.
[4] D. Crevier, R. Lepage, "Knowledge-Based Image Understanding Systems: a Survey", Computer Vision and Image Understanding, Vol. 67(2), pp. 161-185, 1997.
[5] A. Amir, M. Lindenbaum, "A Generic Grouping Algorithm and its Quantitative Analysis", IEEE Transactions on Pattern Analysis and Machine Acquisition, Vol. 20(2), pp. 168-180, 1998.
[6] M. Wertheimer, "Principles of Perceptual Organization", Readings in Perception, pp. 115-135, 1958.
[7] P. Vasseur, C. Pégard, M. Mouaddib et al, "Perceptual Organization Approach by Dempster-Schafer Theory", Pattern Recognition, Vol. 32, pp. 1449-1462, 1999.
[8] A. Maßmann, S. Posch, G. Sagerer et al, "Using Markov Random Fields for Perceptual Grouping", Proc. Of International Conference on Image Processing, Vol. 2, pp. 207-210, 1997.
 Research Report RR-2004-003 PDF
Research Report RR-2004-003 PDF