Introduction à l’analyse de données
Séance 7 - indexes multi-niveaux (suite)
Vu précédement
- Données tabulaires
- Pandas, Dataframes, Series, indexes
- Filtrer les données (colonnes, lignes)
- Combiner des données, (concat, jointure, aggrégation)
- Figures
- Indexation à plusieurs niveaux
Exercices set_index
- Obtenir la DataFrame indexée par Subject et Space
- Obtenir la DataFrame indexée par Subject, Space et l’index original avec un niveau nommé essai (on peut utiliser .rename sur un index)
Exercices groupby
- Faire une dataframe du temps de réponse moyen par Name_A, Name_B
- Faire une dataframe du temps de réponse max par sujet et par différence de distance (symbolique)
- Faire une dataframe du nombre, puis du taux de bonnes réponses par Mode, Side et Space
Figures 3d
Préparation
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import cm
pour chaque figure:
fig, ax = plt.subplots(subplot_kw={'projection': '3d'})
Figures 3D
Scatter
ax.plot_scatter(valeurs_x, valeurs_y, valeurs_z)
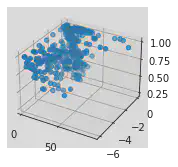
Figures 3D
Surface 3D
ax.plot_trisurf(valeurs_x, valeurs_y, valeurs_z, cmap=cm.jet)
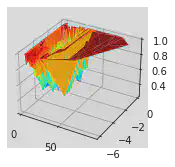
Exercice Scatter
- Faire un scatter plot du taux de réussite en fonction de la différence en mètres d’une part et de l’arrondit du temps de réaction en dixièmes de seconde d’autre part.
Générer un index
Index comprenant toutes les combinaisons de valeurs possibles issues de chaque série d’une liste de séries
pandas.MultiIndex.from_product(
liste_de_series,
names=liste_de_noms)
Réindexer
Changer l’index en gardant les lignes présentes dans l’ancien index et en ajoutant des lignes pour les valeurs présentes uniquement dans le nouvel index
ma_dataframe.reindex(
index=nouvel_index,
fill_value=valeur_si_manquant)
Digression: Créer une liste à partir d’une liste existante
liste_transformee = [ calcul(elt) for elt in liste_depart ]
exemple
valeurs = [ 3, 4, 5, 6 , 7, 8 ]
valeurs_plus_3 = [ v+3 for v in valeurs ]
Exercice: configurations explorées
Quelle exhaustivité dans les combinaisons de paramètres de l’expérience ?
- Générer un index de toutes les combinaisons de valeurs possibles des colonnes de paramètres expérimentaux
- En utilisant groupby sur la liste des colonnes de paramètres expérimentaux (dans le même ordre), faire le compte du nombre d’essai pour chaque combinaison de paramètres
Exercice: configurations explorées (suite)
- Reindexer la dataframe avec l’index précédent, en utilisant 0 pour le fill
- Essayer de déterminer si certains paramètres ont été moins bien explorés que d’autres
Cube de données
(version simplifiée)
- Catégorisation des colonnes en
- mesures
- e.g. prises pendant une expérience
- dimensions
- e.g. paramètres d’un essai
- mesures
- Une ligne = un fait
- e.g. un essai
Dimensions
- valeurs utilisées pour découper l’espace
- fixer une valeur revient à couper une tranche d’espace
Dessin
Mesures
- s’agrège dans une case de l’espace
- les valeurs de plusieurs cases s’agrègent ensemble
- fonctionne bien pour: min, max, sum
- attention à
- count (recoder avec sum)
- mean, std, etc
Cube de l’expérience de discrimination
- mesures: RT, nombre d’essais, nombre d’essais réussis, autre ?
- dimensions: Subject, Name_A, Name_B, Dist_A, Dist_B, Mode, Space, Side, autre ?
Préparer les faits
- Ajouter les colonnes pertinentes (e.g. nombre d’essais (réussis)).
- Comprendre comment on peut/va aggréger les valeurs.
Explorer le cube
- Calculer les valeurs associées à une tranche via des groupby
- Le cas échéant, faire les calculs séparément puis assembler (via
concatoumerge) les dataframes.