...
Lecture / écriture d’une sélection 1/4
HDF5 prend en charge l’accès aux sélections d’un ensemble de données en une seule opération de lecture / écriture. Actuellement les sélections sont limitées à des hyperslabs, des unions d’hyperslabs et à des listes de points indépendants
a)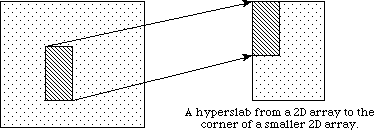 Dans l’exemple a), un seul hyperslab est lu à partir du milieu d’un tableau à deux dimensions dans un fichier et est stocké dans le coin d’une matrice à deux dimensions (plus petite), en mémoire
Dans l’exemple a), un seul hyperslab est lu à partir du milieu d’un tableau à deux dimensions dans un fichier et est stocké dans le coin d’une matrice à deux dimensions (plus petite), en mémoire
Lecture / écriture d’une sélection 2/4
b)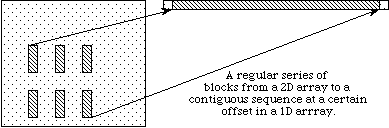 Dans l’exemple b), une série régulière de blocs est lue à partir d’un tableau à deux dimensions dans un fichier et est stockée (à un offset donné) comme une séquence contiguë de valeurs dans un tableau unidimensionnel, en mémoire
Dans l’exemple b), une série régulière de blocs est lue à partir d’un tableau à deux dimensions dans un fichier et est stockée (à un offset donné) comme une séquence contiguë de valeurs dans un tableau unidimensionnel, en mémoire
Lecture / écriture d’une sélection 3/4
c)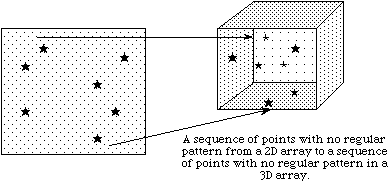 Dans l’exemple c), une séquence de points sans motif régulier est lue à partir d’un tableau à deux dimensions dans un fichier et est stockée comme une séquence de points sans motif régulier dans un tableau à trois dimensions, en mémoire
Dans l’exemple c), une séquence de points sans motif régulier est lue à partir d’un tableau à deux dimensions dans un fichier et est stockée comme une séquence de points sans motif régulier dans un tableau à trois dimensions, en mémoire
Lecture / écriture d’une sélection 4/4
d)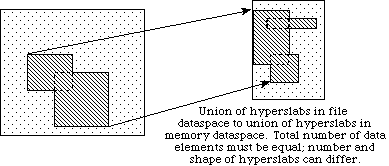 Dans l’exemple d), une union d’hyperslabs est lue dans le dataspace ”fichier” et les données sont stockées suivant une autre union d’hyperslabs dans le dataspace ”mémoire”
Dans l’exemple d), une union d’hyperslabs est lue dans le dataspace ”fichier” et les données sont stockées suivant une autre union d’hyperslabs dans le dataspace ”mémoire”
Sélection d’hyperslabs
Les hyperslabs sont des parties de jeux de données. Un hyperslab peut être un ensemble logiquement contigu de points (ou un motif régulier de points, ou de blocs) dans un espace de données. L’image suivante illustre une sélection de blocs 3x2 espacés régulièrement dans un espace de données 8x12 :
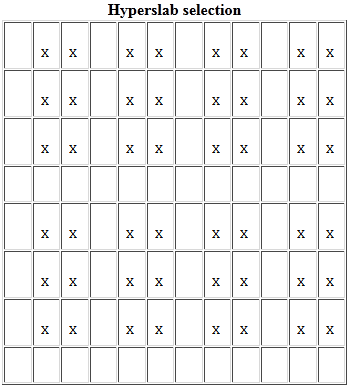 Quatre paramètres sont nécessaires pour décrire un hyperslab :
Quatre paramètres sont nécessaires pour décrire un hyperslab :
-
Start: un point de départ pour l’hyperslab. Dans l’exemple, start est : (0,1)
-
Stride: le nombre d’éléments pour séparer chaque élément ou bloc à sélectionner. Dans l’exemple, stride est : (4,3). Si le paramètre stride est défini à NULL, la taille du stride est : ”un dans chaque dimension”
-
Count: le nombre d’éléments ou blocs de sélection pour chaque dimension. Dans l’exemple, count est : (2,4)
-
Block: la taille du bloc sélectionné. Dans l’exemple, le bloc est : (3,2). Si le paramètre block est défini à NULL, la taille du bloc est : ”un seul élément dans chaque dimension”
Exemple sans stride et sans block 1/3
Supposons que nous voulons lire un hyperslab de dimension 3x4 à partir d’un dataset en commençant par l’élément <1,2>. Le code suivant illustre la sélection de l’hyperslab dans le dataspace ”fichier” :
Exemple sans stride et sans block 2/3
Nous devons définir ensuite l’espace de données dans la mémoire de manière analogue. Supposons, par exemple, que nous avons en mémoire un tableau de dimension 7x7x3 dans lequel nous souhaitons lire l’hyperslab de dimension 3x4 décrit ci-avant en commençant à l’élément <3,0,0>. Comme le dataspace ”mémoire” comporte trois dimensions, il faut décrire l’hyperslab en mémoire comme un tableau à trois dimensions, avec la dernière dimension à 1 : 3x4x1
→ Nous devons donc décrire deux choses : les dimensions du tableau en mémoire, et la taille et la position de l’hyperslab que nous souhaitons lire. Le code ci-après illustre comment procéder :
Exemple sans stride et sans block 3/3
Exemple avec strides et blocks 1/3
Considérons le dataspace de dimension 8x12 décrit ci-avant, dans laquelle nous avons sélectionné huit blocs 3x2. Supposons que nous souhaitons combler ces huit blocs :
Rappel, cet hyperslab a les paramètres suivants: start = (0,1), stride = (4,3), count = (2,4), block = (3,2)
Supposons que l’espace de données source en mémoire soit ce tableau de 50 éléments appelé ”vector” :
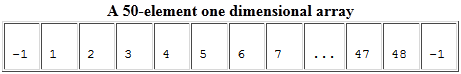
Exemple avec strides et blocks 2/3
Le code suivant va écrire les 48 éléments de ”vector” vers notre fichier, en commençant par le deuxième élément du vecteur :
Exemple avec strides et blocks 3/3
Après ces opérations, le dataspace ”fichier” aura donc les valeurs suivantes :

Sélection d’une liste de points indépendants 1/3
Un hyperslab spécifie un motif régulier d’éléments dans un ensemble de données. Mais il est également possible de spécifier une liste d’éléments indépendants
Supposons, par exemple, que nous souhaitons écrire dans le dataspace de dimension 8x12 décrit ci-avant les valeurs 53, 59, 61, 67 pour les éléments suivants : (0,0), (3,3), (3,5) et (5,6). Le code suivant sélectionne les points et les écrit dans le dataspace ”fichier” :
Sélection d’une liste de points indépendants 2/3
Sélection d’une liste de points indépendants 3/3
Après ces opérations, le dataspace ”fichier” aura donc les valeurs suivantes :
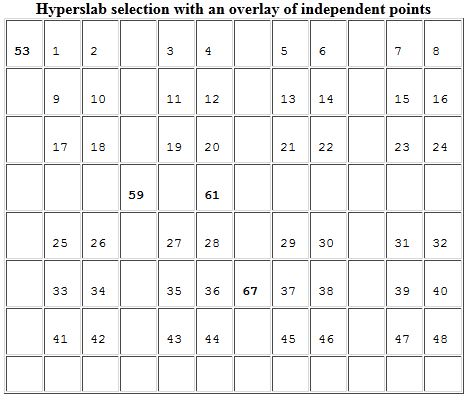
(Sélection d’une union d’hyperslabs)
←
→
01/07/13 - M. TOLA - Liris -
/
#