Web de données¶§
| author: | Pierre-Antoine Champin |
|---|

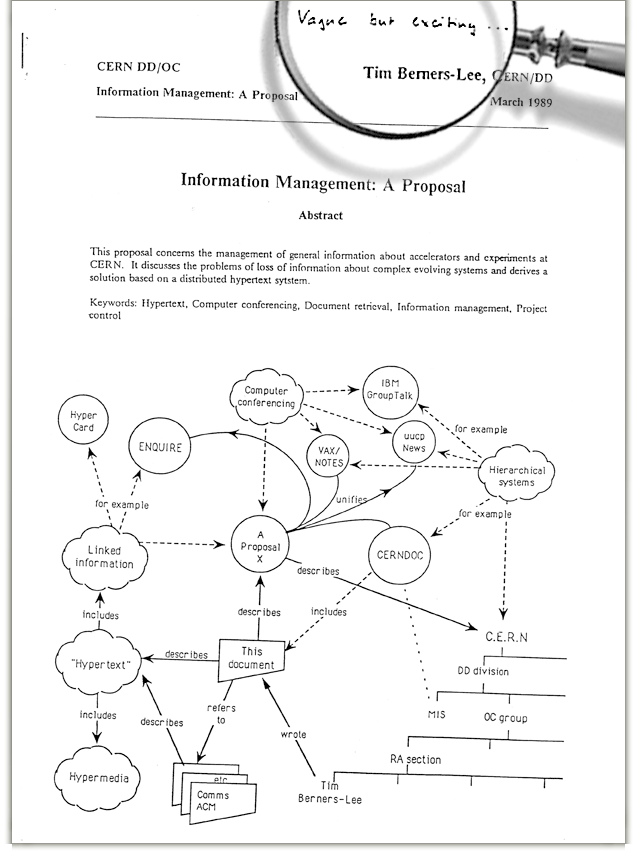
Motivation et historique¶§

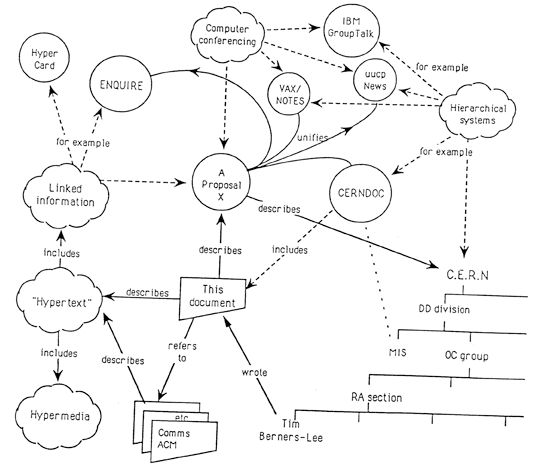
Web de ressources¶§
Le web est constitué de ressources, par exemple :
- le bulletin météo du jour pour Lyon
- le bulletin météo du jour pour le lieu courant
- ma commande de café de jeudi dernier
Chaque ressource est identifiée par un IRI (Internationalized Resource Identifier), e.g.:
⚠ Un IRI n’est pas un nom de fichier (cf. exemples ci-dessus)
Parenthèse : URL/URI/IRI¶§
- URL: Uniform Resource Locator (RFC 1738, 1994)
- URI: Uniform Resource Identifier (RFC 2396, 1998)
- IRI: Internationalized Resource Identifier (RFC 3987, 2005)
- technologies successives
- même concept
Ressources et représentations¶§
- Une ressource n’est jamais manipulée directement, mais toujours à travers des représentations (pour la créer, la consulter, la modifier).
- Les représentations d’une ressource peuvent varier en fonction
- de son état
- de l’agent qui manipule la ressource (négociation de contenu, context)
| représentation : | utilisable par : |
|---|---|
| texte | humains, moteurs de recherche |
| médias (image, son...) | surtout humains |
| données structurées | machines |
De HTML à XML¶§
XML (eXtensible Markup Language) a été recommandé par le W3C en 1998. L’objectif était de pallier la sémantique « faible » de HTML.
<!-- HTML -->
<a href="http://champin.net/">
Pierre-Antoine <strong>Champin</strong>
(<em>Maître de conférences</em>)</a>
<!-- XML -->
<Person homepage="http://champin.net/">
<givenName>Pierre-Antoine</givenName>
<surname>Champin</surname>
<job>Maître de conférences</job></Person>
XML et la sémantique¶§
On a dit tout et son contraire l’apport sémantique de XML :
- XML a plus de sémantique que HTML,
- XML a moins de sémantique que HTML,
Les deux ont leur part de vérité.
XML a plus de sémantique que HTML...¶§
... dans le sens ou il est extensible : on peut donc exprimer des choses que HTML ne permet pas d’exprimer (e.g.``<givenName>``).
- Importance des espaces de noms, qui évitent les collisions de noms et fournissent ainsi une sémantique « structuraliste » (i.e. par différenciation).
<Person xmlns="http://xmlns.com/foaf/0.1/"
xmlns:pro="http://example.com/"
homepage="http://champin.net/">
<givenName>Pierre-Antoine</givenName>
<surname>Champin</surname>
<pro:job>Maître de conférence</pro:job></Person>
XML a moins de sémantique que HTML...¶§
... dans la mesure ou :
- un navigateur standard ne saura pas quoi faire de la balise <givenName>
ou de la balise <ονομα>,
- tout au plus il saura les afficher s’il possède une feuille de style,
- tandis qu’il connaît la sémantique de la balise <em> : elle dénote un
texte à mettre en évidence selon les moyens dont il dispose, par exemple :
- en le mettant en italique (standard)
- en le mettant en gras (police déjà en italique)
- en le mettant en couleurs (police sans italique, terminal)
- en marquant une pause (synthèse vocale)
XML : apports et limitations¶§
Le surplus de sémantique promis par XML n’est donc pas « magique » : il suppose
de créer de nouveaux langages basés sur XML (DTD, schémas),
d’écrire les logiciels qui interpréteront ces nouveaux langages,
→ chaque langage reste relativement idiosyncratique.
XML : apports et limitations (suite)¶§
L’apport est donc essentiellement technique : la base commune de XML permet de factoriser les efforts de développement et d’apprentissage :
- analyseurs syntaxiques (parsers),
- langages de schémas (DTD, XML-Schema, Relax-NG...),
- langages de requêtes (XPath, XQuery),
- langages de transformation (XSL-T),
- méthode de signature cryptographique (xmldsig),
- methode de compression (EXI)...
De XML à RDF¶§
Le modèle sous-jacent de la syntaxe XML est un arbre (XML Infoset), ce qui n’est pas adapté à la structure décentralisée du Web.
L’objectif du Resource Description Framework (RDF), recommandé par le W3C en 1999, vise à munir le Web d’un modèle de données plus adapté, ayant une structure de graphe.
L’objectif est de construire le Semantic Web : un web dans lequel les machines ont (enfin) accès à la sémantique des données.
Recommandation un peu hâtive, présentant quelques défauts importants (notamment l’absence de sémantique formelle).
→ faible adoption de RDF
De RDF à RDF¶§
- En 2004, le W3C publie un nouvel ensemble de recommandations sur RDF pour remplacer celles de 1999.
- Pour des raisons de compatibilité avec l’existant, certains aspects sont conservés malgré les débats qu’ils suscitent, mais les défauts considérés comme majeurs sont corrigés.
- Après cet échec relatif, l’appellation Semantic Web tombe peu a peu en disgrâce. Certains défenseurs de RDF parlent plus modestement de Data Web, puis de Web of Linked Data (2006).

source: http://www.w3.org/RDF/icons/
Le mouvement OpenData¶§
Toute donnée publique (gouvernementale, ONU) ou publiée (scientifique) devrait être accessible sous une forme permettant le traitement automatique (en plus d’une forme lisible pour des humains).
- http://data.gov/
- http://data.un.org/
- http://data.gouv.fr/
- http://opendata69.org/
- Raw Data Now (Tim Berners-Lee à TED)
Linked Open Data¶§
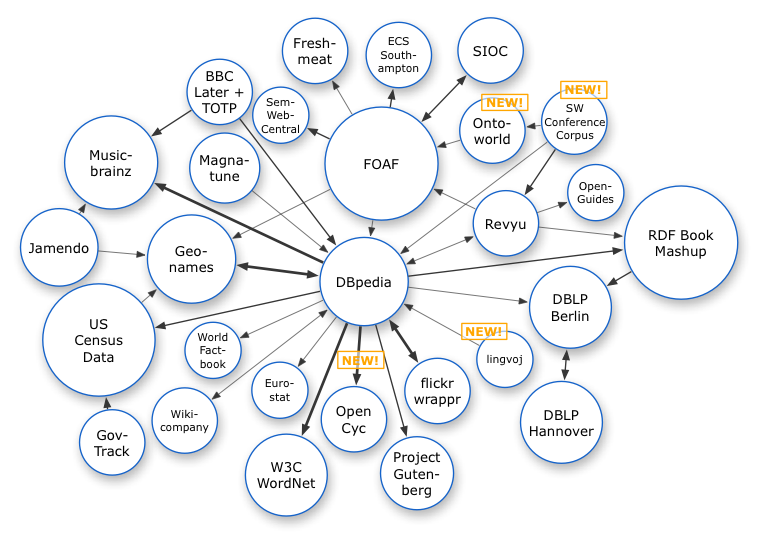
Les quatre principes de Linked Data¶§
- Utiliser des IRIs pour nommer les choses (= ressources).
- Utiliser des IRIs HTTP pour pouvoir obtenir des représentations de ces ressources.
- Fournir ces représentations en utilisant des langages et des protocoles standards (RDF, SPARQL).
- Inclure des liens pour permettre de découvrir de nouvelles ressources.
d’après Tim Berners-Lee, http://www.w3.org/DesignIssues/LinkedData.html
Ouvrir les données liées¶§
- Intérêt des IRIs : tout jeu de données peut référencer des données d’un autre jeu de données
- réutilisation de l’existant
- Intérêt des IRIs déréférençable (cool IRIs) : permet de découvrir de nouvelles données sur le mode de l’hypertexte
- passage à l’échelle
- importance d’un format commun → RDF
- Linked open data star scheme
Projet emblématique : DBpedia¶§
Projet lancé par Chris Bizer en 2007.
Objectif : extraire les informations structurées (infobox) présentes dans Wikipedia pour les exposer en RDF.
En juillet 2011 (version 3.7) :
The new DBpedia data set describes more than 3.64 million things, of which 1.83 million are classified in a consistent ontology, including 416,000 persons, 526,000 places, 106,000 music albums, 60,000 films, 17,500 video games, 169,000 organizations, 183,000 species and 5,400 diseases.
Informations structurées dans Wikipedia¶§
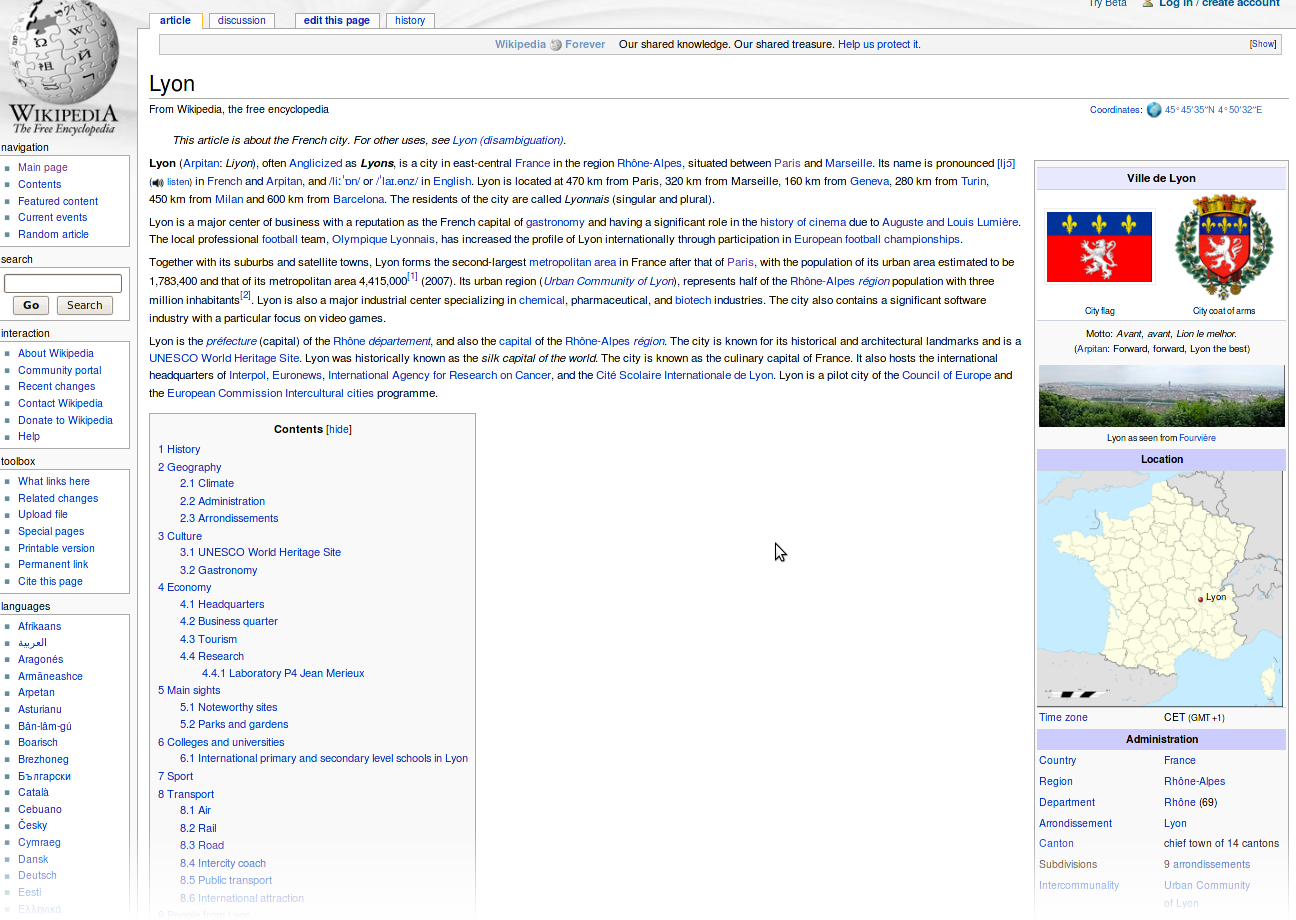
source : http://en.wikipedia.org/wiki/Lyon
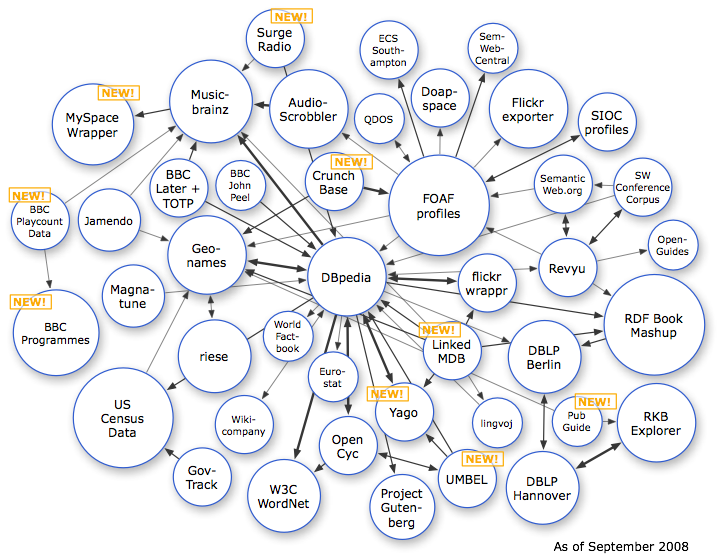
Le « LOD cloud »¶§
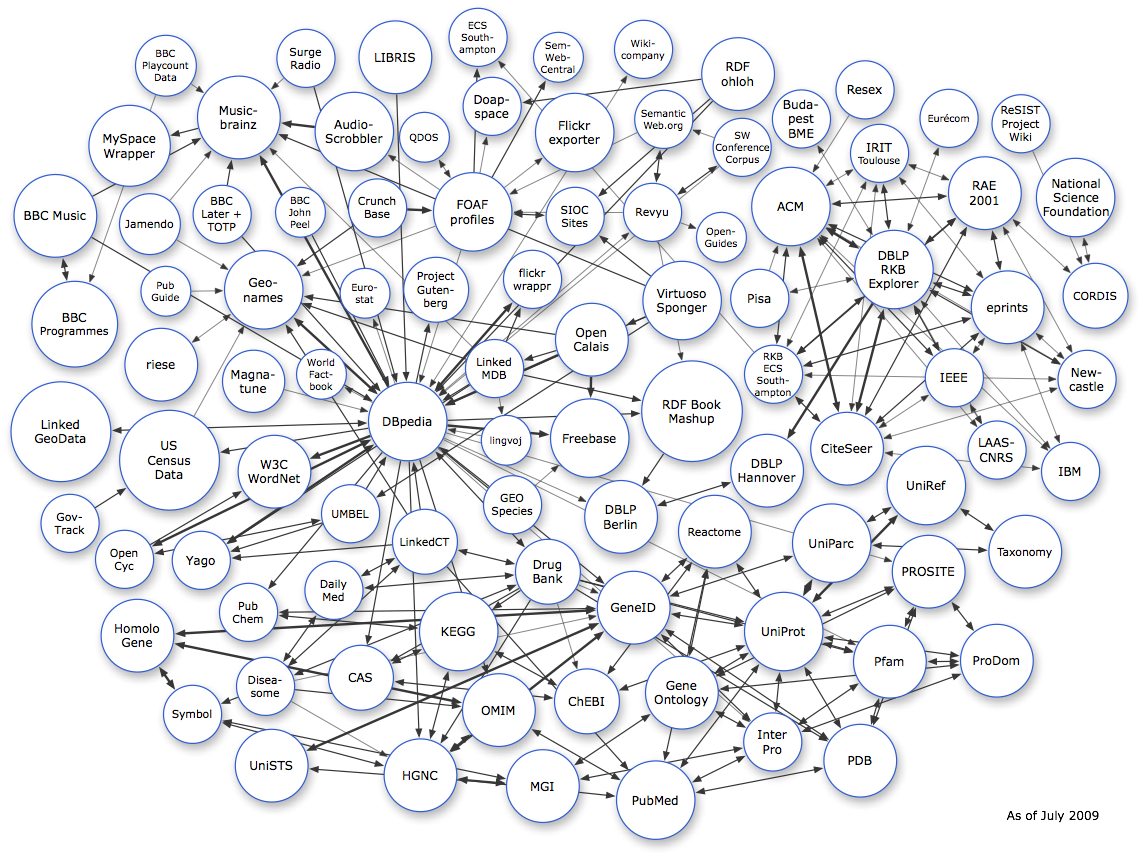
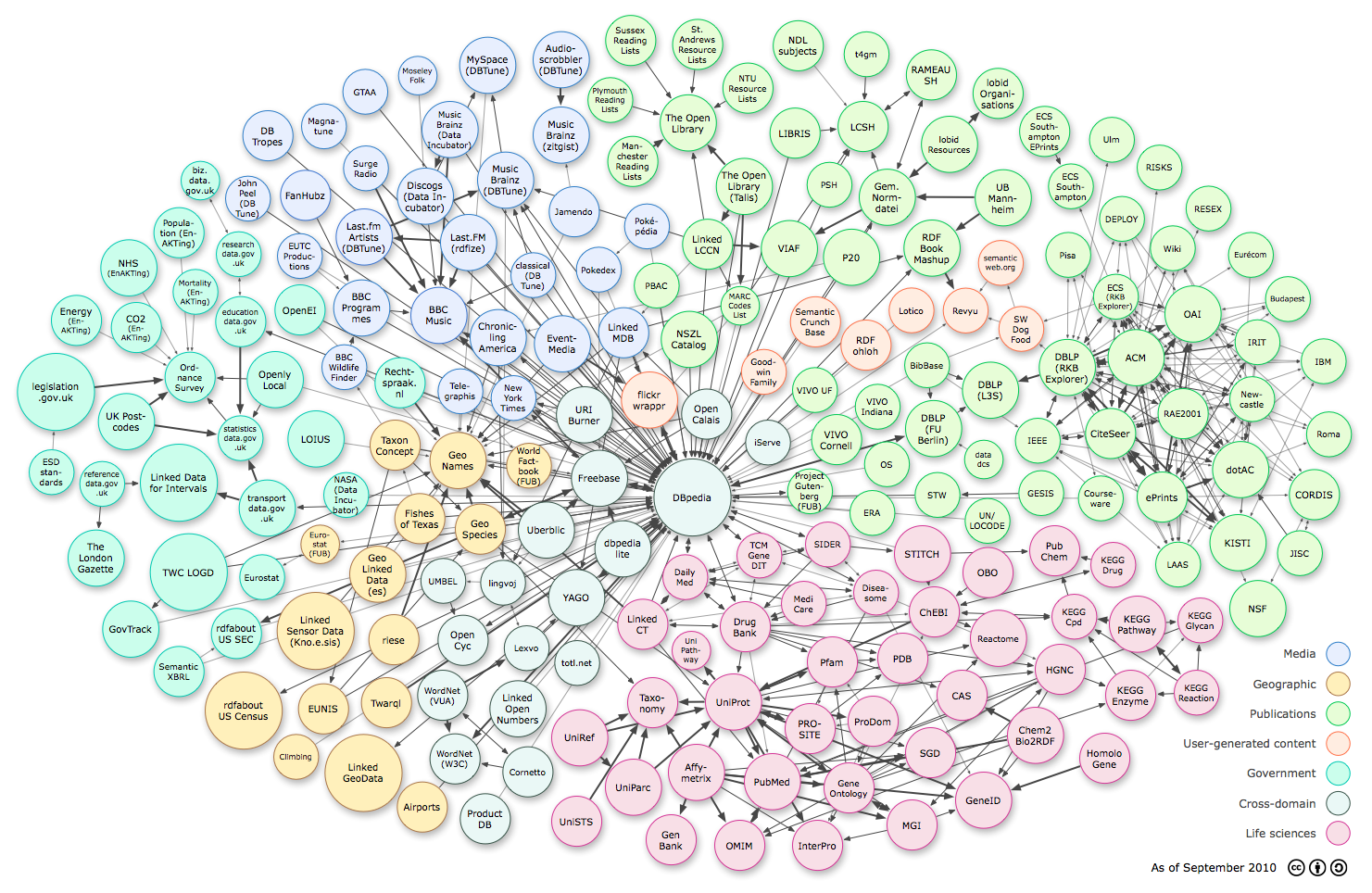
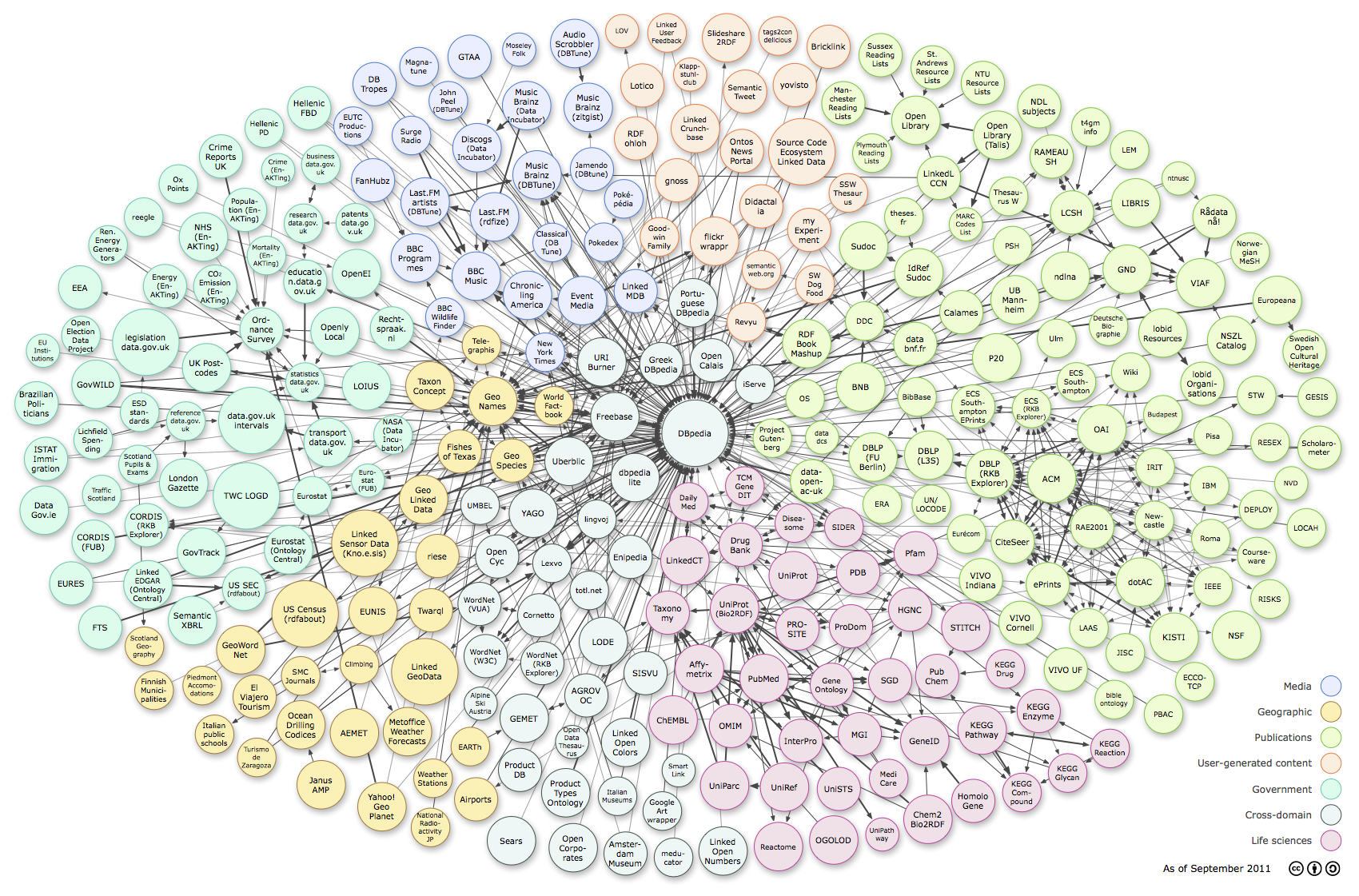
{kind=link}
{kind=link}
Rechercher et explotation des données¶§
- Annuaire des sources de données :
- Moteur de recherche :
- Navigateurs de données :
- http://graphite.ecs.soton.ac.uk/browser/ (navigateur simple)
- http://sig.ma/ (navigateur multi-source)
- http://www.visualdataweb.org/relfinder.php