Cadre
Cette page a été créée par Vincent Nivoliers, doctorant en informatique au LORIA (Nancy) à l'époque. Elle a été utilisée dans le cadre d'un atelier MAth.en.JEANS avec des élèves de la sixième à la quatrième du Collège George Chepfer encadrés par Louisette Hiriart et Christelle Kunc pendant l'année scolaire 2011-2012. Elle a ensuite été mise à jour depuis le LIRIS et l'université de Lyon en 2016 et dotée d'outils de programmation pour un second atelier au Lycée Lamartinière Diderot à Lyon encadré par Éric Koubi. Le but de ces ateliers consiste à faire découvrir les mathématiques (et l'informatique) différemment, en mettant les élèves en situation de recherche. Le sujet que j'ai proposé aux élèves est fourni sur la page d'accueil. Les élèves et leurs enseignantes ont rédigé leurs travaux, qui sont publiés sur le site de l'association. La liste des élèves impliqués dans le projet est fournie dans l'article. Je tiens à les remercier, ainsi que leurs enseignant.e.s, pour m'avoir invité dans leur classe, et pour leur motivation sans faille tout au long de l'année.
Objectifs
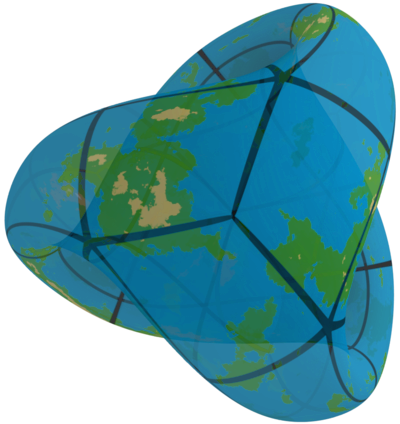
Le but de cette page consiste à faire découvrir aux enfants des algorithmes de parcours de graphe, et certaines notions topologiques sur les surfaces. Chaque planète proposée à l'exploration peut être vue du point de vue théorique comme un graphe : les cases sont les sommets, et les voisinages entre les cases sont les arêtes du graphe. Par dessus la simple vision en terme de graphe, les cases sont carrées et sont connectées bord à bord. Les informations disponibles pour une arête du graphe deviennent alors :
- une première case ;
- quel bord de la première case ;
- une seconde case ;
- quel bord de la seconde case ;
- orientation de la connexion.
Conception
Tous les programmes écrits dans le cadre de ce projet sont regroupés dans une archive, téléchargeable en suivant ce lien. Vous y trouverez en particuliers les fichiers mentionnés dans les sections qui suivent.
Architecture du site
En dehors de la page d'accueil, chaque planète correspond à un dossier dans l'arborescence du site. Chaque dossier contient un fichier au format XML décrivant la planète, et un ensemble d'images utilisées pour représenter les cases de la planète. À ces fichier est ajouté un fichier php. Ce fichier est le même pour toutes les planètes. Il utilise le nom du dossier pour définir le nom de la planète, et trouve le fichier XML à utiliser pour la description de la planète correspondante. Ce fichier est nommé « explorer.php » dans l'archive fournie. Dans le dossier de la planète, un fichier « extra.php » peut être ajouté pour rajouter une information supplémentaire en dessous du bloc de navigation de la planète. C'est par ce biais que la mission sur la planète Dédale a été ajoutée.
Pour ne pas avoir à gérer de base de données, de comptes utilisateur, et pour pouvoir laisser sans risque le site ouvert à tous, les données d'utilisation (notes, programme) sont entièrement gérées côté client via du javascript et le stockage local. Il est également possible de sauvegardes ses données dans un fichier pour les transférer d'un poste à un autre. Ces choix signifient également que le fichier XML décrivant la planète est lisible par l'utilisateur et qu'il peut y accéder directement plutôt que de parcourir la planète « à pieds ». Il est également possible de sauter à la case voulue en exécutant du code javascript supplémentaire. Ces deux derniers défauts n'en sont cependant pas réellement à mon sens, car je serais ravi de voir les enfants acquérir les connaissances nécessaires à leur exploitation. Le code réalisé est séparé en quatre fichiers :
-
explorer.jspour la gestion des planètes et la navigation -
notes.jspour la gestion des notes et des variables du programme -
pgm_construction.jspour l'interface de programmation -
pgm_compile.jspour l'interprétation des programmes et leur exécution
La conception du site a bénéficié d'outils ouverts pour la mise en page et la gestion de certains aspects compliqués :
- bootstrap pour la mise en page
- bootstrap-native également pour la mise en page
- sortable pour la gestion du glisser / déposer dans le programme
Description XML des planètes
La structure globale du fichier xml est la suivante :
La planète est délimitée par la baliseplanet. Une planète
contient autant de cases que désiré, et chaque case est délimitée par la
balise tile. Une case est identifiée par l'attribut
id, obligatoire. Les cases sont carrées, et dotées de
quatre arêtes, numérotées dans le sens inverse des aiguilles d'une
montre, en partant du bas. Les arêtes décrivent les connexions entre les
cases. Elles peuvent être dotées de quatre attributs différents :
-
origin_index: le numéro de l'arête dans la case (obligatoire) ; -
neighbour: l'identifiant de la case voisine (optionnel, l'arête est un bord si l'attribut n'est pas fourni) ; -
opposite_index: le numéro de l'arête dans la case voisine (obligatoire sineighbourest fourni) ; -
orientation: "direct" si les deux cases ont la même orientation, "switch" sinon (obligatoire sineighbourest fourni).
En plus de la description des arêtes, chaque case décrit l'image qui est
utilisée pour la dessiner, via la balise image. Le nom de
base de l'image est fourni via l'attribut name. Sur le
site, en réalité, huit images sont fournies pour chaque case. La prochaine
partie décrit ces images. Un exemple de fichier XML complet décrivant une planète
« cubique » peut être consulté ici.
Génération des planètes en XML
L'écriture manuelle des fichiers xml décrivant les planètes s'avère fastidieuse, et il est très facile de se tromper. Pour faciliter cette tâche, le logiciel Blender peut être utilisé pour modéliser les panètes en trois dimensions. Le script python « topo2xml.py » fourni dans l'archive peut être ensuite utilisé pour créer automatiquement le fichier xml à partir de la planète modélisée, si toutes les faces sont quadrangulaires. Ce script contient un certain nombre d'outils, et permet par exemple également de charger les images créées pour chaque face, et ainsi de pouvoir faire un « rendu » comme celui réalisé pour la surface de Boy sur cette page. La dernière version de Blender pour laquelle le script a été testé est la version 2.69. Une fois le script exécuté, de nouveaux opérateurs sont disponibles, et une fois un maillage quadrangulaire sélectionné, l'opérateur « Topology to XML » permet de créer le fichier xml correspondant. Le nom du fichier est choisi dans la boîte de paramètres de l'opérateur, et est "/tmp/mesh.xml" par défaut.
Images utilisées pour les cases

Chaque case est dessinée via une image. Au niveau du site, huit images
sont fournies, correspondant à toutes les possibilités de rotation et
d'orientation de la case. Le nom de base de l'image est fourni via le
nœud image dans la description xml de la case, décrite
précédemment. Les huit images fournies pour la case sont ensuite nommée
à partir de ce nom de base. Si le nom de base fourni est
map.png, les noms des huit images seront construits sur le
modèle
map_r[rotation]_[orientation].png.
La partie
[rotation] est à remplacer par le nombre de rotations (de 90 degrés)
appliquées à l'image : un entier entre 0 et 3. La rotation est réalisée
dans le sens des aiguilles d'une montre. La partie [orientation] peut
être soit vide, soit flip, et indique si l'image a subi
une symétrie. La symétrie est appliquée après la rotation, et revient à
retourner l'image comme une crèpe le long de l'axe horizontal : les
pixels de droite se retrouvent à gauche. Il est probable qu'il soit
possible d'utiliser du CSS pour retourner les images au moment de
l'affichage, et ne pas avoir à les dupliquer huit fois, mais je ne suis
pas allé chercher jusque là. Pour générer automatiquement les huit
images à partir d'une image de base, le script bash
« generate_transformed_images.sh », présent dans l'archive et fondé sur imagemagick,
peut être utilisé. L'image ci-contre
donne un exemple des huit images correspondant à une même case.
Lors du parcours de la planète, pour chaque case, la rotation et
l'orientation sont évaluées, afin de sélectionner la bonne image et de
représenter chaque case dans le bon sens. Par exemple, si la case
case0 à dessiner au centre utilise l'image de base
map0.png, a subi une rotation de 2, et n'a pas subi de
changement d'orientation, elle sera dessinée en utilisant l'image
map0_r2.png. La case ayant subi deux rotations dans le sens
des aiguilles d'une montre, l'arête décrivant la case à dessiner en
dessous est l'arête numéro 2. Imaginons que la case d'en dessous soit la
case case1, qu'elle utilise l'image map1.png,
et que dans la description de l'arête 2 de case0, l'arête
de la case voisine soit l'arête 1 et l'orientation soit "direct". Nous
savons donc que case1 doit être dessinée en dessous de
case0, avec l'arête 1 vers le haut. Si l'arête 1 est en
haut, l'arête 3 est en bas, et la rotation de la case est donc 3.
L'orientation étant directe, nous utiliserons donc le fichier
map1_r3.png pour dessiner cette case. Les choses peuvent
devenir un peu plus compliquées lorsque l'orientation change, mais nous
en resterons là pour l'exemple. Sur chaque case dessinée, la boussole
est placée pour indiquer la rotation et l'orientation de la case.
Génération des images à partir de la planète en XML
L'archive contient également le petit programme "heightmap", écrit en
C++ et utilisé pour générer les images utilisées pour dessiner les
cases, et surtout pour s'assurer qu'elles se recollent correctement de
case en case. Le programme est composé de deux fichiers, heightmap.h et
heightmap.cpp fournis dans l'archive. Il utilise la bibliothèque
png++ pour générer des
images au format png, et la bibliothèque xerces-c pour
lire le ficher xml correspondant à la planète à laquelle les images sont
destinées. Pour compiler ce programme, utilisez par exemple
g++ -lpng -lxerces-c heightmap.cpp -o heightmap
Si le fichier xml décrivant la planète est planete.xml, le
programme s'utilise simplement en exécutant
heightmap planete.xml
Vous obtiendrez alors pour chaque case une image ayant le nom spécifié
dans le fichier xml. Deux options sont également possible. L'option
--iterations contrôle grossièrement la résolution des
images produites. Il vaut 8 par défaut, et les images produites ont 256
pixels de côté. En passant ce paramètre à 9, les images ont 512 pixels
de côté. L'option --roughness contrôle grossièrement le
caractère accidenté du paysage produit. En diminuant sa valeur, le
paysage devient plus accidenté, et en l'augmentant, il devient plus
régulier.
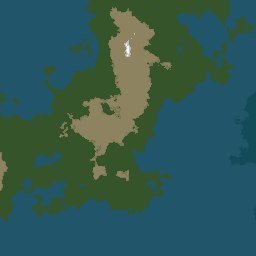
Le programme utilise l'algorithme Diamond-square pour générer une carte de hauteur. Il est probable qu'il soit possible de générer des cartes de hauteur de meilleure qualité en utilisant du bruit de perlin, mais cet algorithme simple permet facilement de s'assurer du recollement des différentes cases entre elles, même en cas d'orientations différentes. Une fois la carte de hauteur générée, une couleur est appliquée en fonction de la hauteur. Ici, cinq couleurs sont utilisées pour l'eau profonde, l'eau peu profonde, l'herbe, la terre et la neige. Ces cinq couleurs sont illustrées sur l'exemple ci-contre.