Images¶
Perception¶
Images aim at storing what our eyes see. We therefore need a better comprehension of what we see to understand how we can store it. Vision is the process through which our eyes collect the electromagnetic radiation circulating in our environment and interpret it to get a representation of our surroundings. What we call visible light is the set of electromagnetic radiations that our eyes can perceive.
To perceive light, our eyes are equipped with several types of photosentive cells, mainly rod cells and cone cells. Rod cells are mostly responsible for low light vision, while cone cells allow us to perceive colors. Cone cells can be divided in three groups depending on the set of wavelengths they react to. S cells are activated by small wavelengths (around blue), M cells for medium wavelengths (around green) and L cells for long wavelengths (around red). The following image (courtesy of Wikipedia) details the reaction of these cells as a function of the wavelength.
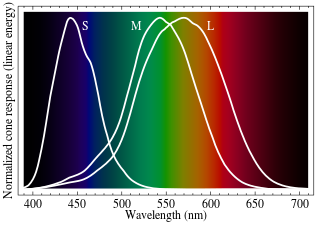
The distribution of these cells vary between individuals, but we are mostly equipped with M and L cells. Some classical diseases impact this distribution, such as color blindness usually due to some type of cone cells missing.
The perceived color of an object corresponds to the light we receive from the object. Unless the object is itself a light source, this light usually commes from the reflection of the light emitted from other sources. The material of the object absorbs some parts of the spectrum and reflects some others. Determining the color of an object therefore amounts to determining this absorbtion function. We however usually perceive the object under specific light conditions. Our brain is therefore responsible for estimating the lighting conditions, and deducing the color of the object. This process however varies between individuals, and when dealing with pictures taken with a camera and displayed on some other medium, people may interpret color in different ways. A classical example is the following picture (source unknown, taken from the Times of India), which received a bit of fame on social media

Depending on your brain reaction, you can perceive this shoe as grey with green laces, or pink with white laces. If you look at it for a longer time, you might end up enterpreting it in the right way, which is pink and white. The reason for this is that the picture was taken with a green ambient light. Looking at this picture out of context makes it more difficult to guess the ambient lighting conditions, and therefore the actual color of the shoe. In terms of the stored data, without interpretation, the color is grey.
Color reproduction and representation¶
Storing images is pointless without means to reproduce them. To reproduce an image, a device has to recreate an excitation of the eye cells in order to mimic the excitation perceived at the moment the image was taken. Two main families of methods exist for this purpose. Additive synthesis uses light emitters specifically designed to trigger the groups of cone cells individually. This type of synthesis is typically used in screens. Subtractive synthesis filters an input white light source with filters specifically designed to reduce the excitation of each family of cone cells. This is especially used in printing devices.
RGB colors¶
When dealing with additive synthesis, as seen on the excitation curves of the cone cells, we know the wavelengths triggering each family of cone cells. Roughly, the S family is excited by blue light, the M family by green light and the L family by red light. The display device therefore exhibits a distribution of tiny light emitters : red, green and blue ones. To pilot such a device, one has to provide the intensity with which each of these emitters should function. The naïve RGB model therefore stores these three intensities as numbers, ending up with a three dimensional color space.























































