ONTOLOGIES : introduction générale
Vous avez appris comment il était possible pour un système informatique
de mettre en place des mécanismes de "raisonnement" fondés
sur l'exploitation de "connaissances" déclaratives et plus
particulièrement de connaissances déclarées sous une forme
logique. Tous les guillemets sont là pour rappeler à quel point
il s'agit de métaphores pour les termes "raisonnement" et "connaissances"
alors que la forme logique n'est pas métaphorique mais correspond à
un modèle mathématique précis autorisant le calcul.
De ce fait, la déclaration des connaissances suppose la capacité ŕ formaliser
sous forme de rčgles et de fait tout « ce que l’on sait comme étant
VRAI » sur le domaine d'expertise de façon à établir
la forme logique autorisant le calcul. C'est ce qui va différencier fondamentalement
une base de connaissances d'une base de données par exemple. Cette formalisation,
bien que simple dans son principe, « atomise » les connaissances en
une liste de déclarations indépendantes syntaxiquement
mais fortement dépendantes sémantiquement
les unes des autres. La structure de ces dépendances, c’est-ŕ-dire les
relations existantes entre chaque déclaration, sont définies également par des
déclarations. Cette déclaration des dépendances n'est pas évidente
ŕ la simple lecture des déclarations et surtout ne peut pas servir facilement
de support ŕ l’expression de ces connaissances. Bien que le texte des
déclarations soit théoriquement lisible par l'utilisateur (après
tout, c'est du texte!), il n'offre qu'une aide trčs limitée ŕ sa compréhension
par manque d'une
structure syntaxique interprétable par l'homme selon
la sémantique
exprimée dans les déclarations. Autrement dit, on aimerait que
quand une personne "lit" les déclarations des connaissances,
l'interprétation qu'elle en fait est cohérente avec ce que l'auteur
des déclarations exprime de manière formelle. Par exemple, il
est bien évident que la déclaration d'une liste de personnes avec leurs relations
hiérarchiques est beaucoup moins rapide à interpréter qu’un
organigramme.
Activité
1
Le développement d'un système informatique "à base
de connaissances" nécessite donc un va-et-vient incessant entre
une représentation adaptée à la logique du premier ordre
telle que vous la connaissez et des représentations "équivalentes"
à destination des utilisateurs. Les "ingénieurs de la connaissance"
sont ces développeurs chargés de trouver les méthodes permettant
de réaliser cette acquisition de connaissances à partir des expertises
disponibles pour les traduire plus ou moins efficacement dans un système
d'inférence logique. Ces méthodes existent et sont instrumentées
par des outils informatiques accompagnant l'acquisition des connaissances (visiter
le site du GRACQ pour
en savoir plus). On peut faire le rapprochement entre cette évolution
et le génie logiciel
qui a développé des méthodes et des outils (voir la liste
impressionnante des outils
disponibles sur le web et/ou un cours proposé sur le web sur une
méthode OBJECTORY représentative du génie logiciel objet)
permettant de passer plus facilement des spécifications d'un système
informatique par les utilisateurs à la réalisation de système
par les informaticiens. La tâche d'acquisition des connaissances est en
effet très lourde et se rapproche de la tâche d'analyse qui conduit
au développement d'applications informatiques. Dans le cas du génie
logiciel, un code informatique "exécutable" est généré
à partir des modèles issus de l'analyse. Ce code intègre
sans distinction données et procédures de traitement. Dans le
cas du "génie cognitif", les connaissances sont générées
en tant que telles et restent distinctes des procédures de traitement
(que l'on appelle le moteur d'inférence). Ces connaissances sont représentées
sous une forme symbolique : chaque concept est "nommé" par
un symbole différent pour être manipulé en tant que tel.
Pour des raisons évidentes, les noms donnés à ces concepts
doivent être ceux qui correspondent aux usages des utilisateurs. Ce qui
n'est qu'un dictionnaire de données en génie logiciel devient
essentiel puisque le même concept doit porter bien entendu obligatoirement
le même nom mais surtout posséder les mêmes caractéristiques
sémantiques (provoquer les mêmes inférences) à chaque
usage dans une déclaration de connaissance.
On peut imaginer l'effort fait pour réaliser un système à
base de connaissances dans ces conditions. Cet effort consenti, on comprend
que l'on souhaite réutiliser au maximum le résultat quand il s'agit
de réaliser un nouveau système à base de connaissances.
En pratique, l'idée s'impose d'essayer de définir un corpus de
connaissances sur la sémantique des quelles un maximum d'utilisateurs
soient d'accord ; en clair, on va essayer de réutiliser tout ce qui a
pu être interprété comme vrai dans le domaine : l'effort
de développement d'une nouvelle application en sera largement diminué.
Ce n'est pas la première fois que les hommes imaginent de décrire
"ce qui existe" de manière formelle (et invariante si possible)
pour faciliter la communication entre eux et plus loin le partage des connaissances.
Au fond, si chacun utilise le même référenciel (un gros
mot pour dire que pour chacun, chaque chose est interprétée de
manière identique), alors il est beaucoup plus facile d'exprimer de nouvelles
connaissances qui s'appuieront pour cela sur les connaissances partagées
sans ambiguïté par tout le groupe. C'est en effet Aristote
qui (le premier?) proposa d'étudier comment on pouvait décrire
le monde sans ambiguïté et permettre ainsi au raisonnement de suivre
des chemins parfaitement contrôlés. Une telle étude de ce
"qui existe" ou plus précisément de "ce qui est"
s'appelle une ontologie.
Ce fut (et c'est toujours!) un concept philosophique que nous (les informaticiens)
avons repris à notre compte pour représenter cette description
d'un domaine (voir par exemple ce projet dans le domaine de l'agriculture) à des fins d'efficacité
de mise en place de systèmes à base de connaissances. Nous verrons
d'ailleurs que la conception d'ontologies dans les entreprises offre des perspectives
d'usage plus larges que la simple récupération technique de bases
de connaissances réutilisables : c'est souvent l'occasion d'une réflexion
intense sur les savoirs et les savoir-faire de l'entreprise. Mais ça,
c'est une autre histoire objet d'autres modules de cette formation!
ILLUSTRATION
: représenter
sous forme graphique des connaissances.
Ainsi donc, lorsqu'on aborde un domaine nouveau, on bute sur le vocabulaire
: d'une part sur les mots qu'on ne connait pas, d'autre part sur les mots qu'on
connait mais qui n'ont pas ici le męme sens. Dans le premier cas, on va regarder
dans le dictionnaire ; dans le deuxičme cas, dčs qu'on a pris conscience qu'il
y avait un problčme, on va regarder dans le glossaire. Mais, dans les deux cas,
on va trouver, dans la définition, des mots sur lesquels on butera : le dictionnaire
est circulaire!
En fait, ce nouveau domaine ne consiste pas simplement en "mots" ; il comporte
une "structure", et c'est cela que nous cherchons ŕ "comprendre".
On appelle donc "ontologie" d'un domaine l'ensemble des mots et structures
qui le constituent. Les langues ne sont pas trčs appropriées pour transmettre
les ontologies. Et si la cible est une machine, elles sont hors de question,
pour de longues années encore. On préfčre donc avoir recours ŕ des langages,
comme par exemple les langages "orientés objet". En représentation externe,
on privilégiera une représentation sous forme de graphes, plus lisible que la
représentation interne sous forme de listes (attributs - valeurs).
Voici un autre exemple, graphique cette fois, d'ontologie pour des véhicules,
mais avec une volonté de représenter les principes de fonctionnement
à la différence de l'exercice précédent
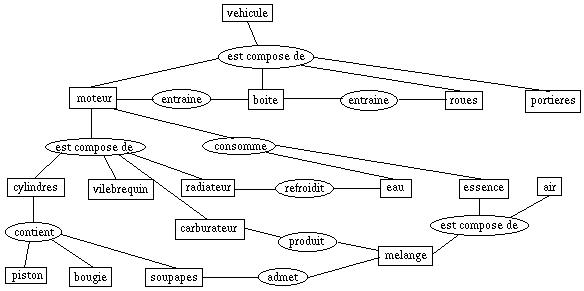
On peut distinguer deux méthodes pour construire une ontologie : top-down et
bottom-up. Dans tous les cas, dans l'état actuel, il faut procéder incrémentalement,
c'est-ŕ-dire par améliorations successives. Une partie des recherches est axée
sur la construction ŕ partir de textes, et pose donc les problčmes de compréhension
automatique de textes et de schémas.
Le graphe ci-dessus laisse entrevoir la complexité de la tâche. Un outil extrčmement
utile consiste ŕ extraire des sous-graphes, si possible des arbres, en ne visualisant
que certaines relations. Cela permet, souvent de "faire sauter aux yeux" des
relations manquantes (regardez l'air, ci-dessus) ou des relations surprenantes.
Une autre question qui se pose est celle du "point de vue" : pour un véhicule,
par exemple, le carrossier, le motoriste, l'acousticien... sont tous intéressés
par le moteur, mais ŕ des titres trčs divers. Sans parler du fabricant, du vendeur
et du réparateur.
TEST