UE8: notebook séance 6
Notebook UE8 séance 6
Initialisation, chargement des données
import pandas
df = pandas.read_excel("Donnees_M2_RD.xlsx")
dist_i_m = pandas.DataFrame(
{ "Dist_I_m": [ 0.2, 0.3, 0.4, 0.6, 0.8 ] },
index = [1,2,3,4,5]
)
dist_e_m = pandas.DataFrame(
{ "Dist_E_m": [ 2, 3, 4, 6, 8 ] },
index = [1,2,3,4,5]
)
df_i = df[df["Space"] == "I"]
dfa = pandas.merge(df_i, dist_i_m, left_on='Dist_A', right_index=True)
dfa2 = dfa.rename(columns={ 'Dist_I_m': 'Dist_A_m' })
dfab = pandas.merge(dfa2, dist_i_m, left_on='Dist_B', right_index=True)
df_i_m = dfab.rename(columns={ 'Dist_I_m': 'Dist_B_m' })
df_e = df[df["Space"] == "E"]
dfa = pandas.merge(df_e, dist_e_m, left_on='Dist_A', right_index=True)
dfa2 = dfa.rename(columns={ 'Dist_E_m': 'Dist_A_m' })
dfab = pandas.merge(dfa2, dist_e_m, left_on='Dist_B', right_index=True)
df_e_m = dfab.rename(columns={ 'Dist_E_m': 'Dist_B_m' })
df_m = pandas.concat([df_i_m, df_e_m])
expes = []
for i in range(8):
filename = "expe/subject-"+str(i)+".csv"
print("Loading "+filename)
df = pandas.read_csv(filename)
df['Subject'] = i
expes.append(df)
dfm1 = pandas.concat(expes)
dfm1 = dfm1.reset_index()
dfm1['Sourire'] = dfm1['image'].str.get(0) == 'S'
dfm1['Genre'] = dfm1['image'].str.get(1)
Loading expe/subject-0.csv
Loading expe/subject-1.csv
Loading expe/subject-2.csv
Loading expe/subject-3.csv
Loading expe/subject-4.csv
Loading expe/subject-5.csv
Loading expe/subject-6.csv
Loading expe/subject-7.csv
Exemples sur des merges
On commence par créer des dataframes df1 et df2
df1 = pandas.DataFrame(
{ "A": [ "a1", "a1", "a2", "a2", "a3" ],
"B": [ "b1", "b2", "b3", "b4", "b5" ],
"C": [ "c1", "c2", "c2", "c2", "c3" ]
}
)
df1
| A | B | C | |
|---|---|---|---|
| 0 | a1 | b1 | c1 |
| 1 | a1 | b2 | c2 |
| 2 | a2 | b3 | c2 |
| 3 | a2 | b4 | c2 |
| 4 | a3 | b5 | c3 |
df2 = pandas.DataFrame(
{ "D": [ "a1", "a2", "a2"],
"E": [ "c1", "c2", "c3"],
"F": [ "f1", "f2", "f3"]
}
)
df2
| D | E | F | |
|---|---|---|---|
| 0 | a1 | c1 | f1 |
| 1 | a2 | c2 | f2 |
| 2 | a2 | c3 | f3 |
pandas.merge(df1, df2, left_on="A", right_on = "D")
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | a1 | b1 | c1 | a1 | c1 | f1 |
| 1 | a1 | b2 | c2 | a1 | c1 | f1 |
| 2 | a2 | b3 | c2 | a2 | c2 | f2 |
| 3 | a2 | b3 | c2 | a2 | c3 | f3 |
| 4 | a2 | b4 | c2 | a2 | c2 | f2 |
| 5 | a2 | b4 | c2 | a2 | c3 | f3 |
pandas.merge(df1, df2, left_on="C", right_on = "E")
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | a1 | b1 | c1 | a1 | c1 | f1 |
| 1 | a1 | b2 | c2 | a2 | c2 | f2 |
| 2 | a2 | b3 | c2 | a2 | c2 | f2 |
| 3 | a2 | b4 | c2 | a2 | c2 | f2 |
| 4 | a3 | b5 | c3 | a2 | c3 | f3 |
pandas.merge(df1, df2, left_on=["A","C"], right_on = ["D","E"])
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | a1 | b1 | c1 | a1 | c1 | f1 |
| 1 | a2 | b3 | c2 | a2 | c2 | f2 |
| 2 | a2 | b4 | c2 | a2 | c2 | f2 |
dfx = pandas.read_excel("Donnees_M2_RD.xlsx")
df_i = dfx[dfx["Space"] == "I"]
df_i
| Subject | Name_A | Name_B | Dist_A | Dist_B | Mode | Space | Side | Response | RT | |
|---|---|---|---|---|---|---|---|---|---|---|
| 150 | P_ADI_331 | 2 | 3 | 3 | 4 | Dic | I | D | 2 | 14608 |
| 151 | P_ADI_331 | 0 | 1 | 1 | 3 | Dic | I | D | 1 | 12665 |
| 152 | P_ADI_331 | 0 | 1 | 1 | 5 | Dic | I | D | 1 | 11074 |
| 153 | P_ADI_331 | 0 | 1 | 5 | 3 | Dic | I | D | 2 | 7727 |
| 154 | P_ADI_331 | 3 | 1 | 5 | 3 | Dic | I | D | 2 | 9366 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9589 | P_VAR_330 | 0 | 1 | 3 | 5 | Dio | I | D | 1 | 7626 |
| 9590 | P_VAR_330 | 3 | 2 | 5 | 1 | Dio | I | D | 2 | 6349 |
| 9591 | P_VAR_330 | 2 | 0 | 4 | 2 | Dio | I | D | 2 | 9031 |
| 9592 | P_VAR_330 | 0 | 2 | 2 | 1 | Dio | I | D | 2 | 16323 |
| 9593 | P_VAR_330 | 0 | 3 | 5 | 1 | Dio | I | D | 2 | 10139 |
4797 rows × 10 columns
dist_i_m
| Dist_I_m | |
|---|---|
| 1 | 0.2 |
| 2 | 0.3 |
| 3 | 0.4 |
| 4 | 0.6 |
| 5 | 0.8 |
dfa = pandas.merge(df_i, dist_i_m, left_on='Dist_A', right_index=True)
dfa
| Subject | Name_A | Name_B | Dist_A | Dist_B | Mode | Space | Side | Response | RT | Dist_I_m | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 150 | P_ADI_331 | 2 | 3 | 3 | 4 | Dic | I | D | 2 | 14608 | 0.4 |
| 162 | P_ADI_331 | 3 | 1 | 3 | 2 | Dic | I | D | 2 | 9820 | 0.4 |
| 164 | P_ADI_331 | 1 | 4 | 3 | 1 | Dic | I | D | 2 | 6505 | 0.4 |
| 168 | P_ADI_331 | 2 | 1 | 3 | 1 | Dic | I | D | 2 | 6121 | 0.4 |
| 174 | P_ADI_331 | 1 | 3 | 3 | 2 | Dic | I | D | 2 | 11024 | 0.4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9571 | P_VAR_330 | 2 | 4 | 4 | 1 | Dio | I | D | 2 | 6557 | 0.6 |
| 9580 | P_VAR_330 | 3 | 1 | 4 | 2 | Dio | I | D | 2 | 19979 | 0.6 |
| 9583 | P_VAR_330 | 0 | 4 | 4 | 5 | Dio | I | D | 2 | 45627 | 0.6 |
| 9587 | P_VAR_330 | 2 | 3 | 4 | 1 | Dio | I | D | 2 | 7823 | 0.6 |
| 9591 | P_VAR_330 | 2 | 0 | 4 | 2 | Dio | I | D | 2 | 9031 | 0.6 |
4797 rows × 11 columns
Visualisation
import matplotlib.pyplot as plt
import matplotlib as mpl
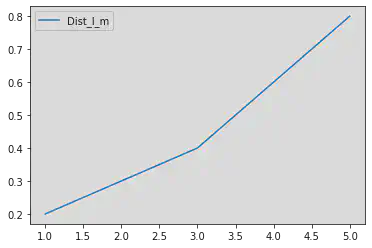
Un premier exemple de courbe avec une série
dist_i_m
| Dist_I_m | |
|---|---|
| 1 | 0.2 |
| 2 | 0.3 |
| 3 | 0.4 |
| 4 | 0.6 |
| 5 | 0.8 |
# Tracer la courbe pour une série
dist_i_m.plot()
<AxesSubplot:>
df_m
| Subject | Name_A | Name_B | Dist_A | Dist_B | Mode | Space | Side | Response | RT | Dist_A_m | Dist_B_m | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 150 | P_ADI_331 | 2 | 3 | 3 | 4 | Dic | I | D | 2 | 14608 | 0.4 | 0.6 |
| 180 | P_ADI_331 | 4 | 3 | 3 | 4 | Dic | I | D | 1 | 9086 | 0.4 | 0.6 |
| 207 | P_ADI_331 | 4 | 2 | 3 | 4 | Dic | I | G | 1 | 7251 | 0.4 | 0.6 |
| 213 | P_ADI_331 | 0 | 4 | 3 | 4 | Dic | I | G | 1 | 9298 | 0.4 | 0.6 |
| 250 | P_ADI_331 | 1 | 0 | 3 | 4 | Dio | I | D | 1 | 11246 | 0.4 | 0.6 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9364 | P_VAR_330 | 1 | 0 | 5 | 2 | Dic | E | D | 2 | 8296 | 8.0 | 3.0 |
| 9374 | P_VAR_330 | 2 | 1 | 5 | 2 | Dic | E | D | 2 | 12260 | 8.0 | 3.0 |
| 9412 | P_VAR_330 | 4 | 3 | 5 | 2 | Dio | E | D | 2 | 9414 | 8.0 | 3.0 |
| 9433 | P_VAR_330 | 3 | 1 | 5 | 2 | Dio | E | D | 2 | 16334 | 8.0 | 3.0 |
| 9437 | P_VAR_330 | 1 | 2 | 5 | 2 | Dio | E | D | 1 | 8802 | 8.0 | 3.0 |
9594 rows × 12 columns
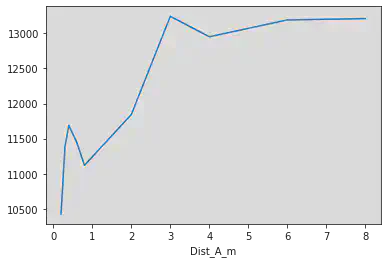
df_m.groupby("Dist_A_m")["RT"].mean().plot()
<AxesSubplot:xlabel='Dist_A_m'>
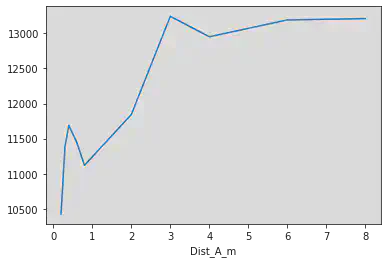
groupes_par_dist_A_m = df_m.groupby("Dist_A_m")
groupes_seulement_avec_RT = groupes_par_dist_A_m["RT"]
aggregation_en_calculant_la_moyenne = groupes_seulement_avec_RT.mean()
aggregation_en_calculant_la_moyenne.plot()
<AxesSubplot:xlabel='Dist_A_m'>
df_m.groupby("Dist_B_m")["RT"].mean().plot()
<AxesSubplot:xlabel='Dist_B_m'>
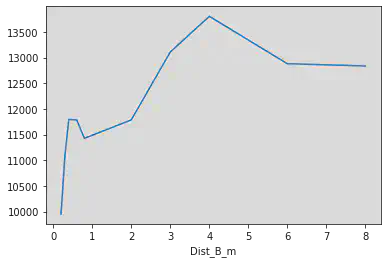
df_m.plot.scatter("Dist_A_m", "Dist_B_m")
<AxesSubplot:xlabel='Dist_A_m', ylabel='Dist_B_m'>
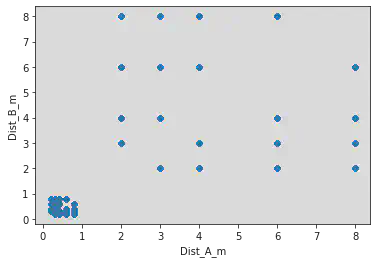
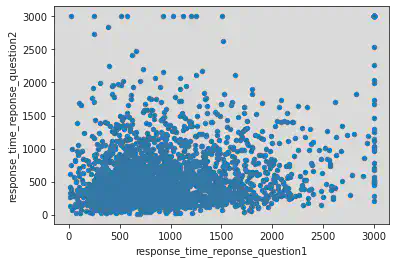
dfm1.plot.scatter("response_time_reponse_question1", "response_time_reponse_question2")
<AxesSubplot:xlabel='response_time_reponse_question1', ylabel='response_time_reponse_question2'>
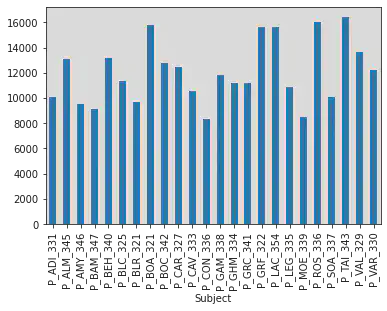
df_m.groupby("Subject")["RT"].mean()
Subject
P_ADI_331 10042.732500
P_ALM_345 13103.350000
P_AMY_346 9561.292500
P_BAM_347 9096.540000
P_BEH_340 13187.195000
P_BLC_325 11366.338346
P_BLR_321 9657.929825
P_BOA_321 15787.130326
P_BOC_342 12779.680000
P_CAR_327 12457.844221
P_CAV_333 10551.257500
P_CON_336 8352.742500
P_GAM_338 11805.215000
P_GHM_334 11220.800000
P_GRC_341 11213.115000
P_GRF_322 15652.556391
P_LAC_354 15617.710000
P_LEG_335 10904.325000
P_MOE_339 8470.447500
P_ROS_336 16019.425000
P_SOA_337 10051.175000
P_TAI_343 16413.327500
P_VAL_329 13661.730000
P_VAR_330 12240.965000
Name: RT, dtype: float64
df_m.groupby("Subject")["RT"].mean().plot.bar()
<AxesSubplot:xlabel='Subject'>
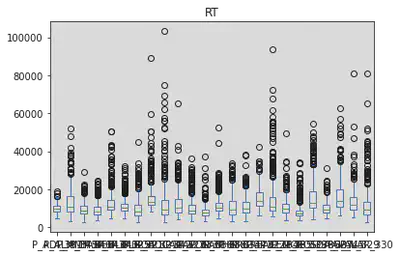
df_m.plot.box(by='Subject', column='RT')
RT AxesSubplot(0.125,0.125;0.775x0.755)
dtype: object
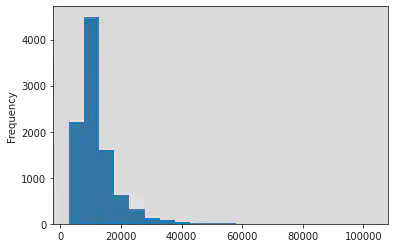
df_m["RT"].plot.hist(bins=20)
<AxesSubplot:ylabel='Frequency'>