UE8: notebook séance 7
Notebook séance 7
import pandas
import matplotlib.pyplot as plt
import matplotlib as mpl
df = pandas.read_excel("Donnees_M2_RD.xlsx")
dist_i_m = pandas.DataFrame(
{ "Dist_I_m": [ 0.2, 0.3, 0.4, 0.6, 0.8 ] },
index = [1,2,3,4,5]
)
dist_e_m = pandas.DataFrame(
{ "Dist_E_m": [ 2, 3, 4, 6, 8 ] },
index = [1,2,3,4,5]
)
df_i = df[df["Space"] == "I"]
dfa = pandas.merge(df_i, dist_i_m, left_on='Dist_A', right_index=True)
dfa2 = dfa.rename(columns={ 'Dist_I_m': 'Dist_A_m' })
dfab = pandas.merge(dfa2, dist_i_m, left_on='Dist_B', right_index=True)
df_i_m = dfab.rename(columns={ 'Dist_I_m': 'Dist_B_m' })
df_e = df[df["Space"] == "E"]
dfa = pandas.merge(df_e, dist_e_m, left_on='Dist_A', right_index=True)
dfa2 = dfa.rename(columns={ 'Dist_E_m': 'Dist_A_m' })
dfab = pandas.merge(dfa2, dist_e_m, left_on='Dist_B', right_index=True)
df_e_m = dfab.rename(columns={ 'Dist_E_m': 'Dist_B_m' })
df_m = pandas.concat([df_i_m, df_e_m])
expes = []
for i in range(8):
filename = "expe/subject-"+str(i)+".csv"
print("Loading "+filename)
df = pandas.read_csv(filename)
df['Subject'] = i
expes.append(df)
dfm1 = pandas.concat(expes)
dfm1 = dfm1.reset_index()
dfm1['Sourire'] = dfm1['image'].str.get(0) == 'S'
dfm1['Genre'] = dfm1['image'].str.get(1)
Loading expe/subject-0.csv
Loading expe/subject-1.csv
Loading expe/subject-2.csv
Loading expe/subject-3.csv
Loading expe/subject-4.csv
Loading expe/subject-5.csv
Loading expe/subject-6.csv
Loading expe/subject-7.csv
dfm1
| index | acc | accuracy | average_response_time | avg_rt | background | canvas_backend | clock_backend | color_backend | correct | ... | time_welcome | tirage | title | total_correct | total_response_time | total_responses | width | Subject | Sourire | Genre | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1012 | 1012 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1329 | 20 | Nouvelle expérience | 0 | 1012.0 | 1 | 1024 | 0 | True | F |
| 1 | 1 | 100 | 100 | 662 | 662 | #3d3846 | legacy | legacy | legacy | 1 | ... | 1329 | 20 | Nouvelle expérience | 1 | 662.0 | 1 | 1024 | 0 | False | F |
| 2 | 2 | 0 | 0 | 710 | 710 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1329 | 20 | Nouvelle expérience | 0 | 710.0 | 1 | 1024 | 0 | False | F |
| 3 | 3 | 0 | 0 | 742 | 742 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1329 | 20 | Nouvelle expérience | 0 | 742.0 | 1 | 1024 | 0 | False | F |
| 4 | 4 | 0 | 0 | 806 | 806 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1329 | 20 | Nouvelle expérience | 0 | 806.0 | 1 | 1024 | 0 | True | F |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3499 | 433 | 100 | 100 | 305 | 305 | #3d3846 | legacy | legacy | legacy | 1 | ... | 1443 | 5 | Nouvelle expérience | 1 | 305.0 | 1 | 1024 | 7 | False | F |
| 3500 | 434 | 0 | 0 | 290 | 290 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1443 | 5 | Nouvelle expérience | 0 | 290.0 | 1 | 1024 | 7 | True | M |
| 3501 | 435 | 0 | 0 | 260 | 260 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1443 | 5 | Nouvelle expérience | 0 | 260.0 | 1 | 1024 | 7 | True | F |
| 3502 | 436 | 0 | 0 | 554 | 554 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1443 | 5 | Nouvelle expérience | 0 | 554.0 | 1 | 1024 | 7 | True | F |
| 3503 | 437 | 0 | 0 | 605 | 605 | #3d3846 | legacy | legacy | legacy | 0 | ... | 1443 | 5 | Nouvelle expérience | 0 | 605.0 | 1 | 1024 | 7 | True | F |
3504 rows × 113 columns
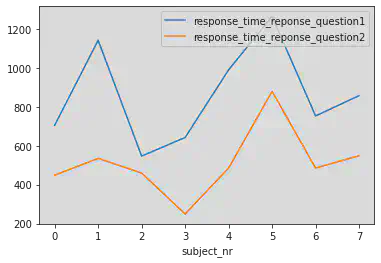
Deux courbes dans un même graphique avec des couleurs différentes:
- Le temps de réponse moyen à la question 1
- Le temps de réponse moyen à la question 2
en fonction du numéro de sujet.
figure, mon_ax = plt.subplots()
dfm1.groupby("subject_nr")["response_time_reponse_question1"].mean().plot(ax=mon_ax,c='#a98d19')
dfm1.groupby("subject_nr")["response_time_reponse_question2"].mean().plot(ax=mon_ax)
<AxesSubplot:xlabel='subject_nr'>
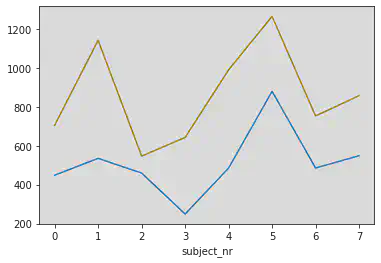
Avec les couleurs choisies automatiquement et en ajoutant une légende issue du nom de la colonne.
figure, mon_ax = plt.subplots()
dfm1.groupby("subject_nr")["response_time_reponse_question1"].mean().plot(ax=mon_ax,legend=True)
dfm1.groupby("subject_nr")["response_time_reponse_question2"].mean().plot(ax=mon_ax,legend=True)
<AxesSubplot:xlabel='subject_nr'>
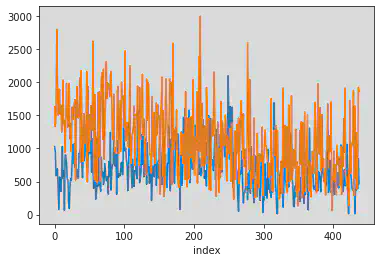
On essaie de tracer plusieurs courbes du temps de réponse en fonction du numéro d’image et ce par sujet.
Pour cela, on commence par filtrer sur le sujet, puis on change l’index pour récupérer l’ancien index (colonne index dans la dataframe dfm1), puis on trace.
On voit ici que, par défaut, pandas dessine toutes courbes dans le même graphique.
dfm1[dfm1["subject_nr"]==0].set_index("index")["response_time_reponse_question1"].plot()
dfm1[dfm1["subject_nr"]==1].set_index("index")["response_time_reponse_question1"].plot()
<AxesSubplot:xlabel='index'>
On peut faire une boucle for en Python pour faire une action sur chaque sujet:
les_sujets = dfm1["subject_nr"].drop_duplicates()
for num_sujet in les_sujets:
print("Ceci est le sujet n°"+str(num_sujet))
Ceci est le sujet n°0
Ceci est le sujet n°1
Ceci est le sujet n°2
Ceci est le sujet n°3
Ceci est le sujet n°4
Ceci est le sujet n°5
Ceci est le sujet n°6
Ceci est le sujet n°7
les_sujets = dfm1["subject_nr"].drop_duplicates()
for num_sujet in les_sujets:
# On trace pour le sujet sélectionné la courbe du temps de réponse
# en fonction de la progression dans l'expérience
dfm1[dfm1["subject_nr"]==num_sujet].set_index("index")["response_time_reponse_question1"].plot()
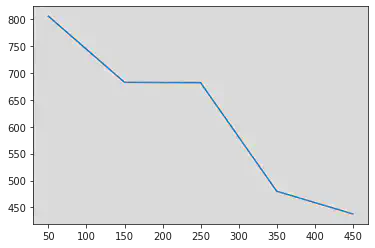
On fait des paquets de 100 photos en fonction du numéro de photo et on trace la moyenne du temps de réponse.
df_s1 = dfm1[dfm1["subject_nr"]==3]
df_s1_0_100 = df_s1[df_s1["index"] < 100]
rt1_0_100 = df_s1_0_100["response_time_reponse_question1"].mean()
df_s1_100_200 = df_s1[(df_s1["index"] >= 100) & (df_s1["index"] < 200)]
rt1_100_200 = df_s1_100_200["response_time_reponse_question1"].mean()
df_s1_200_300 = df_s1[(df_s1["index"] >= 200) & (df_s1["index"] < 300)]
rt1_200_300 = df_s1_200_300["response_time_reponse_question1"].mean()
df_s1_300_400 = df_s1[(df_s1["index"] >= 300) & (df_s1["index"] < 400)]
rt1_300_400 = df_s1_300_400["response_time_reponse_question1"].mean()
df_s1_400_500 = df_s1[(df_s1["index"] >= 400) & (df_s1["index"] < 500)]
rt1_400_500 = df_s1_400_500["response_time_reponse_question1"].mean()
rt1_serie = pandas.Series(data = [rt1_0_100, rt1_100_200, rt1_200_300, rt1_300_400, rt1_400_500],
index = [50, 150, 250, 350, 450])
rt1_serie.plot()
<AxesSubplot:>
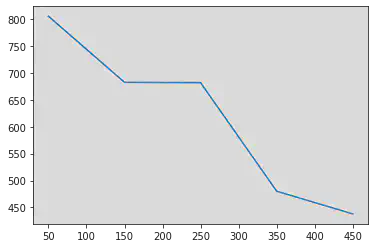
num_sujet=3
df_s = dfm1[dfm1["subject_nr"] == num_sujet]
taille_intervalle=100
valeurs = []
num_photos = []
derniere_photo = df_s["index"].max()
for i in range(0, derniere_photo // taille_intervalle + 1):
moy = df_s[ (df_s["index"] >= taille_intervalle * i )
& (df_s["index"] < taille_intervalle * (i+1) )
]["response_time_reponse_question1"].mean()
valeurs.append(moy)
num_photos.append(i*taille_intervalle+taille_intervalle//2)
pandas.Series(data = valeurs, index = num_photos).plot()
<AxesSubplot:>
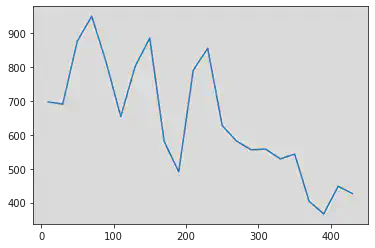
num_sujet=3
df_s = dfm1[dfm1["subject_nr"] == num_sujet]
taille_intervalle=20
valeurs = []
num_photos = []
derniere_photo = df_s["index"].max()
for i in range(0, derniere_photo // taille_intervalle + 1):
moy = df_s[ (df_s["index"] >= taille_intervalle * i )
& (df_s["index"] < taille_intervalle * (i+1) )
]["response_time_reponse_question1"].mean()
valeurs.append(moy)
num_photos.append(i*taille_intervalle+taille_intervalle//2)
pandas.Series(data = valeurs, index = num_photos).plot()
<AxesSubplot:>
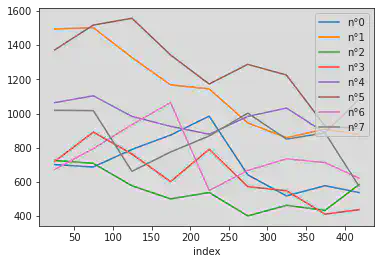
On reprend le code précédent, en le plaçant dans une boucle pour faire une courbe par nr_subject
for num_sujet in range(0,8):
df_s = dfm1[dfm1["subject_nr"] == num_sujet]
taille_intervalle=50
valeurs = []
num_photos = []
derniere_photo = df_s["index"].max()
for i in range(0, derniere_photo // taille_intervalle + 1):
moy = df_s[ (df_s["index"] >= taille_intervalle * i )
& (df_s["index"] < taille_intervalle * (i+1) )
]["response_time_reponse_question1"].mean()
valeurs.append(moy)
num_photos.append(i*taille_intervalle+taille_intervalle//2)
pandas.Series(data = valeurs, index = num_photos).rename("s. n°"+str(num_sujet)).plot(legend=True)
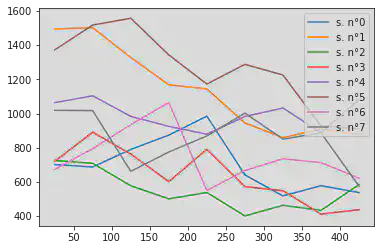
On essaie de faire le même calcul, mais en remplaçant la boucle interne par un groupby.
On commence juste avec le sujet n°2 pour mettre le code au point.
num_sujet=2
# pandas.DataFrame permet de faire une copie,
# ce qui est demandé par pandas au moment où on va ajouter une colonne plus bas
df_s = pandas.DataFrame(dfm1[dfm1["subject_nr"] == num_sujet])
taille_intervalle=50
df_s["idx_intervalle"] = df_s["index"] // taille_intervalle
d_moy = df_s.groupby("idx_intervalle")[["response_time_reponse_question1","index"]].mean()
d_moy.set_index("index").plot()
<AxesSubplot:xlabel='index'>
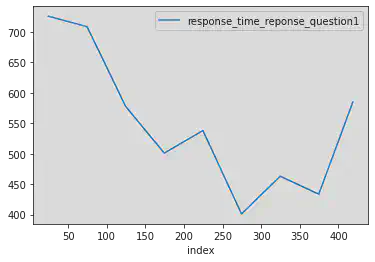
On reprend le principe de la boucle pour afficher une courbe par sujet:
for num_sujet in dfm1["subject_nr"].drop_duplicates():
df_s = pandas.DataFrame(dfm1[dfm1["subject_nr"] == num_sujet])
taille_intervalle=50
df_s["idx_intervalle"] = df_s["index"] // taille_intervalle
d_moy = df_s.groupby("idx_intervalle")[["response_time_reponse_question1","index"]].mean()
# df_moy est une dataframe, on change l'index puis on en fait une série en projetant sur la colonne response_time_reponse_question1
d_moy.set_index("index")["response_time_reponse_question1"].rename("n°"+str(num_sujet)).plot(legend=True)