Document integrity check
to make administrative documents confident

Due to accessibility and cheapness of production devices such as printers, scanners and photocopiers the number of counterfeited documents increases. The administrations and companies face a huge amount of forged electricity and phone bills, birth certificates and administrative invoices. These documents can be presented either in hardcopy or in softcopy formats. Therefore, the protection techniques differ depending on document format.
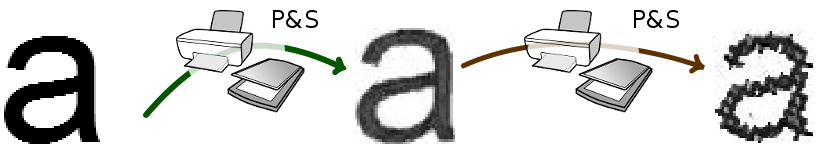
The softcopy documents are protected by signature algorithms that are very efficient tools to ensure the electronic document authenticity. The hardcopy documents are often protected by watermarks, fingerprints or copy-sensitive graphical codes. Nevertheless, all these protection techniques authenticate the document support and cannot ensure the document integrity check.
In daily life we use the both formats of the same document. This type of document that can be represented by hardcopy or softcopy format is called hybrid documents. When we talk about hybrid documents we can imagine two types of counterfeiting processes. During the first one, the digital document is changed and then either used in digital or hardcopy format. The second type consists of a hardcopy document change, for this an opponent needs to scan the document, to change the content and to reprint it. This type of counterfeiting implies a double Print-and-Scan (P&S) process applied to documents.
The studies of OCR capabilities show that the Tesseract algorithm's (which is an open-source OCR) precision depends on the printer and scanner resolutions and varies from 91.58% to 99.45% for document printed-and-scanned once. This precision brings the collision probability (when two different characters are recognized as the same) up to 0.002. The character recognition of double printed documents is more difficult due to the double impact of the P&S process. Thus, the document hash construction is also a difficult task.
In this research, we are interested on:
- document pre-processing to eliminate the impact of P&S processes;
- charcater feature extraction based on the skeleton;
- text hash construction.