ARBI : Accès Rapide aux Bases d'Images, pour la recherche d'images par le contenu
|
Un des problèmes fondamentaux
dans le domaine des bases de données multimédias, réside dans la
recherche de similarité, c.à.d, le besoin de chercher un petit ensemble
d’objets qui soient similaires où très peu rapproché d’un objet requête
donné.
La plupart des méthodes de recherche d’images par le contenu sont
constituée des phases suivantes:
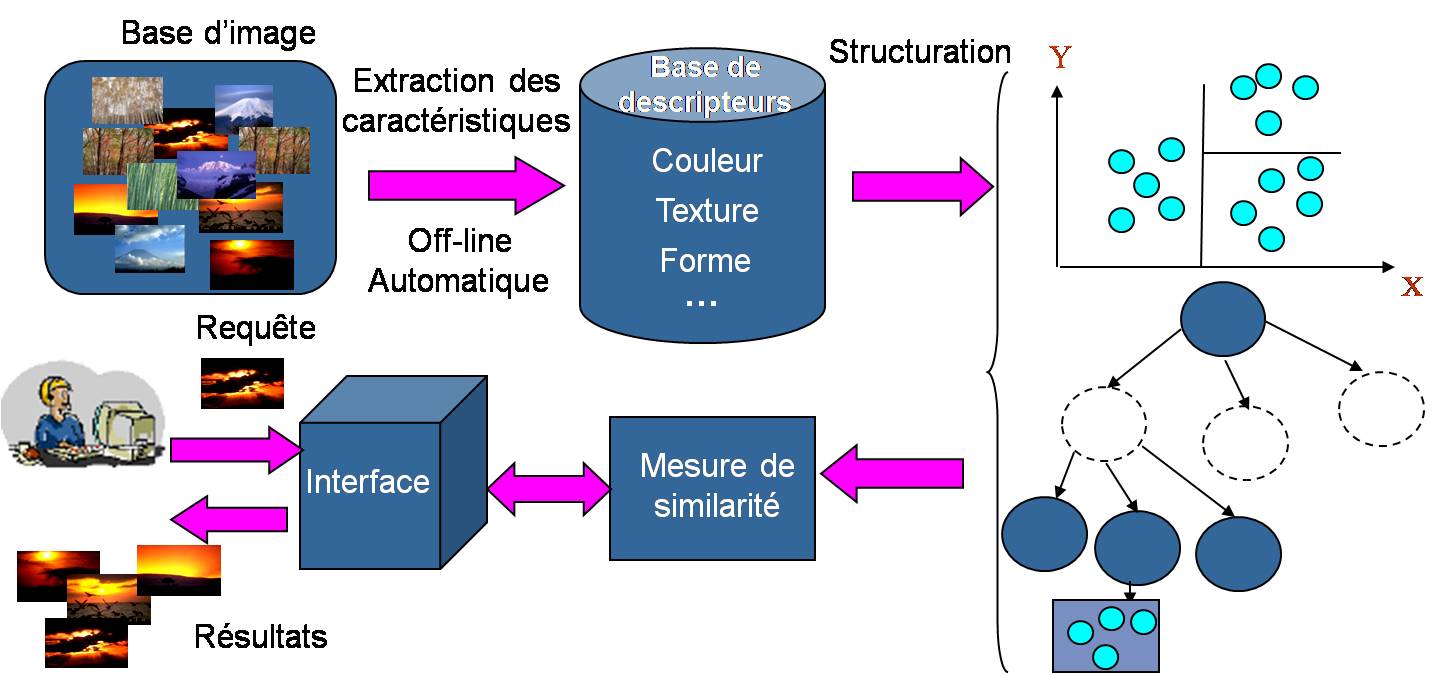
1. Une étape d’indexation d’image : consiste à extraire des signatures compactes de leurs contenu visuel. Ces signatures se présentent sous la forme de vecteurs multidimensionnels appelés descripteurs. 2. Une étape de structuration de l’espace de description : il s’agit dans cette étape de mettre en place une structure d’index multidimensionnels permettent une recherche efficace des dizaines voir des centaines de milliers d’images. 3. Une recherche de similarité : dans la plupart des méthodes, une distance est associée à chaque descripteur et une recherche des k plus proches voisins est effectuée. Nous nous sommes focalisés dans le cadre de ce projet principalement sur les points 2 et 3 pour pouvoir répondre efficacement aux problématiques liées à la recherche des grandes bases d’images. Les travaux ont consisté, d’une part à améliorer la performance des méthodes d’indexations basées sur l’approximation en tenant compte des différentes descriptions des images afin d’apporter des réponses au problème du passage à l’échelle, et d’autre part, d’intégrer dans IMALBUM, moteur de recherche développé au sein de l’équipe, les améliorations obtenues concernant l’accès aux grandes bases d’images. Problématique des systèmes de
recherche
Tout d'abord, une
nouvelle méthode (RA+-Block) a
été proposée, et qui repose sur un
nouvel algorithme de partitionnement qui permet d’améliorer notablement
les
performances de la structure d’index du RA-Blocks en terme de capacité
de
stockage et de temps de recherche en générant des régions compactes et
disjointes. Ce travail a été réalisé durant la Thèse de Imane Daoudi |
"A semi supervised metric learning for content-based image retrieval", I. Daoudi, K. Idrissi, S. EL Alaoui Ouatik. . in Int. Conf. on Signal-Image Technology & Internet-Based Systems. Marrakech 2009.
"Vector Approximation based Indexing for High-Dimensional Multimedia Databases", I. Daoudi, S. Ouatik, A. El Kharraz, K. Idrissi, D. Aboutajdine, in Engineering Letters 16(2):210-218, 2008.
"Kernel Region Approximation Blocks For Indexing Heterogonous Databases". I. Daoudi, K. Idrissi, S. EL Alaoui Ouatik, in IEEE International Conference on Multimedia & Expo, Hannover - Germany. pp. 1237-1240. 2008.
"Kernel Based Approach for High Dimensional Heterogeneous Image Features Management", I. Daoudi, K. Idrissi, S. EL Alaoui Ouatik, in CBIR Context. In Advanced Concepts for intelligent Vision Systems (ACIVS). Juan les Pins, France, . 2008.