3. Trace based user assistance¶
This chapter focuses on the use of digital traces such as the ones formalized in the previous chapter, with an emphasis on uses that aim at assisting users in their task. I will present on the works described in three papers (Yahiaoui et al. 2011; Champin et al. 2010; Ginon et al. 2014). While they address the question in different fields and with various degrees of automation, they all demonstrate how traces can support the interpretation (and re-interpretation) of the user’s activity.
3.1. Trace based redocumentation¶
In the work of Yahiaoui et al. (2011), the user’s task is the documentation of a given activity, i.e. the production of a document reporting on that activity. The user may or may not be the same person who performed that activity (for example, a teacher can report on their student’s activity). The target audience of the document might be the user themselves (in order to keep track of their analysis of the activity), a limited community (e.g. someone can document their use of an application to serve as a tutorial for colleagues or peers), or it can be publicly published.

Fig. 3.1 The redocumentation process (Yahiaoui et al. 2011)¶
In the case of computer-mediated activity, digital traces are usually available and can be considered as a form of documentation, although at a very low level of abstraction. We therefore proposed a redocumentation process illustrated in Fig. 3.1, and a tool named ActRedoc supporting that process. The available trace of the activity is assumed to comply with our meta-model (Section 2.3) and is modeled in RDF. The “automated redocumentation” phase produces a transcription in English of all the information in trace, using NaturalOWL (Ganalis and Androutsopoulos 2007). While this new document is easier to read that the raw data from the m-trace, it is still verbose and mostly factual. Through the “interactive redocumentation” phase, the user can manually improve the produced document, removing or rephrasing existing segments, and adding new ones to enrich the document with analysis and opinions. This phase is repeated iteratively until the user is satisfied with the state of the document, and exports it to a standard format. Fig. 3.2 shows a screenshot of ActRedoc, displaying (from right to left) the available operations on the document, the individual segments constituting the structure of the document, and a preview of the resulting document.
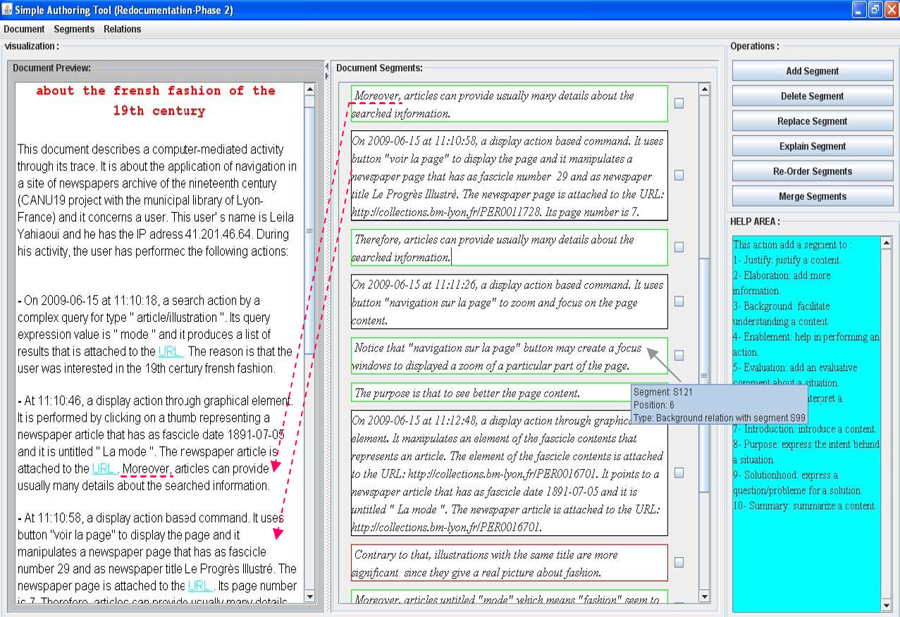
Fig. 3.2 The ActRedoc tool allows to redocument an activity by reorganizing segments generated from the m-trace (Yahiaoui et al. 2011).¶
The underlying structure of the document is strongly inspired by the Rhetorical Structure Theory (RST) by Taboada and Mann (2006), which describes the different kinds of relations that can link documents segments. The benefit of RST is twofold. First, it provides users with guidelines in the redocumentation process, by eliciting the roles of the new segments they may want to add, and encouraging them to create a narrative above the factual sequence of events represented in the m-trace1. Second, those structural relations are kept in the final (HTML) form of the document, using RDFa (Adida and Birbeck 2008) for embedding semantic data, and the OntoReST ontology (Naja-Jazzar et al. 2009) to represent RST relations. Note that RDFa also allows us to link the segments of the final document to the related elements of the m-trace (which is represented by the dotted arrow on Fig. 3.1). The final document is therefore an improvement over the initial trace, not only for human users but also for machines (a perfect example of co-construction of knowledge as described in Section 2.4). Indeed, the rhetorical structure creates relations between obsels that could not be inferred without help from the user, all the more that it represents only one of many possible subjective interpretations of the activity (and so different users, or the same user in different contexts, would end up with different final documents).
This work has investigated a use of m-traces where most of the “processing” is performed by the human, except for the initial step of “automatic redocumentation”. Still, even that very basic step was perceived by ActRedoc users as an improvement over a basic spreadsheet-like presentation of the m-trace. As we have discussed in the previous chapter the importance of efficient user interfaces for supporting reflexivity and more generally TBR, this makes natural language a good candidate for designing such interfaces (see our work with Kong Win Chang et al. (2015) for more recent investigations on that topic). Another interesting insight offered by this work is on the notion of transformation. The redocumentation process, although it does not produce m-traces stricto sensu, can be thought of as a manual transformation, rephrasing the initial m-trace into a more abstract form. In fact, the document structure used by ActRedoc could easily have fit the trace meta-model, obsels playing the role of document segments, and ordered according to the document sequence rather than the original chronology. While in the current process, only the first step is automated, then at every step the user could choose between interactively altering the document/m-trace, or applying a pre-defined automated transformation (e.g. for filtering out all obsels meeting a given criterion, deemed irrelevant for the redocumentation task at hand). Of course, building a toolbox of useful transformations for redocumentation is an open challenge. But this could be done iteratively by tracing the activity of ActRedoc users, and learning from how they proceed interactively. For example, a user manually deleting several similar obsels could ask the system to try and generalize that task, and save it as a reusable transformation. This approach of building transformations by example has been studied in Mehdi Saydi’s master’s thesis (supervised by Amélie Cordier) and implemented in a prototype named Transmute2 (Fuchs and Cordier 2016).
3.2. Curating noisy experience¶
The work presented by Champin et al. (2010) focused on Heystaks3, a social bookmarking system integrating with search engines. Heystaks users rate the most relevant results they get for a given search, so that those results would later be promoted (moved up or even added) in the result list for similar searches. Relevance however depends on the context: a user searching for “Dublin” will not be interested in the same results if they are planning their vacations or if they are interested in studying there. Heystaks allows users to store their ratings in different containers, named staks, in order to distinguish between different search contexts. Staks can also be shared between like-minded users, so that the ratings of one of them can benefit all the subscribers of a given stak.
Heystaks is designed to accommodate user’s practices as smoothly as possible; this is why it has been integrated in the result pages of main search engines, rather than providing a separate search interface. For the same reason, Heystaks does not force users to explicitly rate search results (although such an explicit rating is possible), but will also consider that visiting a link from the result page is a positive assessment of that result (although not as strong as an explicit rating). While this implicit rating is important to quickly populate staks, and hence perform better recommendations, it may cause a problem when users forget to select the appropriate stak when searching the web. In that case, the results visited by the user are wrongly recorded as relevant to the current stak, which will have a negative impact on future recommendations made by this stak.
Preventing this kind of mistake was not a solution, as there are more subtle ways irrelevant pages can be added to a stak: people may change their mind, and a page that did seem relevant once could be deemed irrelevant later. This is all the more true in social applications, where stak users may have divergent opinions. Instead, we wanted to provide stak owners with a tool for curating staks, by removing irrelevant ratings and possibly transferring them to a more appropriate stak, in order to fix mistakes and arbitrate disagreements, thus keeping the staks consistent and their recommendations efficient. To achieve this, we have proposed a meta-recommender system4, recommending the three best staks for a every rated page. The main challenge was to build this system with the data we had, which already contained the kind of noise that we wanted to eliminate; in particular, we had no gold standard against which to evaluate our proposal.

Fig. 3.3 The accuracy of J48 and Naive Bayes increases non linearly (Champin et al. 2010).¶
This plot shows how the weighted accuracy of our classifiers (trained with non-weighted instances) varies when classifying only pages above a certain popularity. This is not a bias in the data, as the majority classifier does not share this property.
We have first proposed a popularity measure to try and predict the relevance of a page to a stak. Intuitively, the popularity of a page \(p\) in a stak \(s\) increases with (1) the number of times \(p\) was rated in \(s\), and (2) the frequency in \(s\) of every term used to search \(p\) (i.e. the number of other pages in \(s\) described with the same term). A preliminary user study has shown that pages with a high popularity are very likely to be relevant, while nothing can be told of pages with a low popularity (roughly 50% of them are relevant). So this popularity measure could be used to weight the evaluated accuracy of our meta-recommender system: “correct” recommendations (i.e. in accordance with the training data) should be sought for popular pages, but not necessarily for unpopular ones (as the training data is more likely to be wrong).
A natural idea was therefore to weight training instances based on their popularity, as we trust popular pages more. Surprisingly, classifiers trained that way did not improve significantly on classifiers trained with no popularity-weighting. This suggests that the relevance of popular pages could be learned from the raw data, which in a sense was encouraging. Furthermore, we noticed that weighted accuracy is better for popular pages, and that it does not vary linearly, as described in Fig. 3.3. It suggests that there are phases in the popularity spectrum, and that the upper third of that spectrum represents a stable subset of relevant pages. We call this subset the stak kernel. Pursuing our idea that popularity could be used to reduce the noise in training data, and thus improving meta-recommendation, we have trained classifiers with only pages from the kernel, and have shown that it improves the accuracy of the Naive Bayes classifiers.
The standard way to build and evaluate a recommender systems is to use a gold standard, i.e. a set of data known to be exact, or at least reasonably good. It is very often built by having a small set of experts annotate the data. a long and costly process. That can be somehow alleviated by resorting on crowdsourcing platforms such as Amazon Mechanical Turk5. Still, in Web applications such as social bookmarking, it remains very hard to build a gold standard that covers the diversity of the actual data. The work presented in this subsection demonstrates the feasibility of an alternative approach: using the full amount of available data, even if it is known to be noisy. While the presented study is quite specific to Heystaks, we are confident the lessons learned and the proposed notion of kernel could apply to other contexts.
Although this work did not rely on our meta-model, it is based on the same premises that digital traces (in the broadest sense) can be harnessed to produce knowledge and help assist users in their task. The traces available in Heystaks are however very synthetic, every page being described by a term vector, a compression of every individual rating of that page. This can be seen as a transformed trace of a possible primary trace where each rating would be stored as an obsel. Should we have access to that primary trace, we could examine alternative perspectives on staks. We could obviously filter out old ratings (or lower their weight) in order to forget all pages that were once relevant but are not anymore. But maybe more subtle temporal patterns could be used instead, that would represent more accurately opinion drift: for example, some pages are used only once in a while but remain relevant over time, while others “buzz” very intensely for a while, and are quickly forgotten. More generally, that primary trace would give access to the past evolution of a stak, possibly allowing to measure its stability (in terms of topic) or agreement (among its different users), some potentially useful indicators for the stak owners. Furthermore, that primary trace would provide the ability to trace back a page (or even an individual rating) to the user(s) who contributed it. This could help detect sub-communities in the users of a stak, a particular case being a malicious users trying to promote irrelevant pages for their own benefit.
3.3. Pro-active user assistance¶
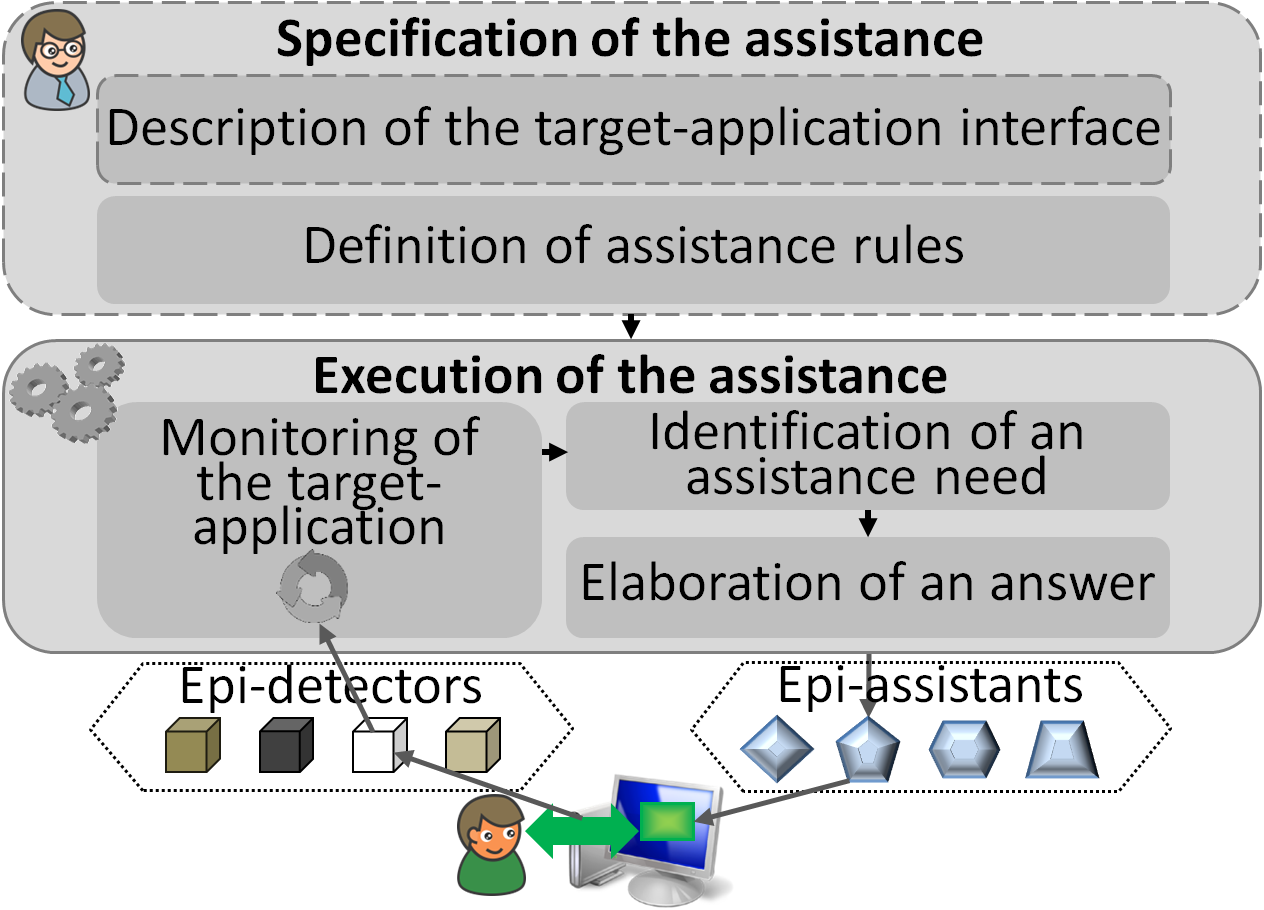
Fig. 3.4 The generic architecture implemented in SEPIA (Ginon et al. 2014)¶
In her PhD, Blandine Ginon (2014) proposed a generic architecture for setting up epiphytic assistance systems, and implemented it in a suite of tools called SEPIA. A biological metaphor, “epiphytic” means that such systems are added to a target application, without requiring any alteration of this application. Epiphytic assistance systems are motivated by the observation that, very often, the users of an application require assistance that the application itself does not provide. This can be due to their lack of practice, to the application being inherently complex, or simply to a bad design of its user interface. Still, modifying the application to include that assistance is not always feasible or practical.
In the first step of our approach (upper part of Fig. 3.4), the assistance system is first defined by the assistance designer, an expert user of the application, who needs not have access to the application source code, nor any advanced programming skill. Their task is mostly to state a number of rules of the form “whenever X happens, provide assistance Y”.
In the second step (lower part of Fig. 3.4), epiphytic detectors (or epi-detectors) are monitoring the user’s interactions with the target application, in order to trigger any assistance rule matching those interactions. Since rules can be more or less specific in describing the assistance to be provided, the assistance effectively enacted can be adapted and personalized, based on contextual information (state of the application, user profile, traces of previous interactions).
As observing the user’s activity is key to our approach, we have built a number of epi-detectors able to observe a large class of applications (Ginon, Champin, and Jean-Daubias 2013). Those epi-detectors gain access to the targer application thanks to accessibility APIs6. They communicate with the SEPIA assistance engine in the same protocol as used by kTBS, our reference MTMS implementation, which makes them reusable to build other trace-based applications. In fact, SEPIA uses kTBS to store the traces collected by the epi-detectors, as past interactions are one of the many parameters of personalization.
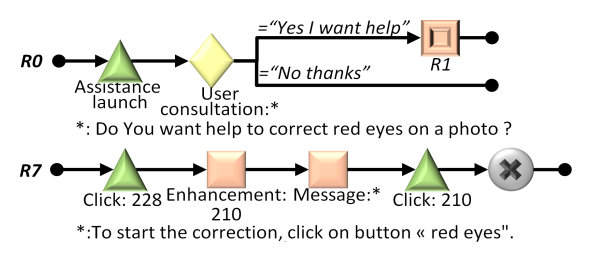
Fig. 3.5 Two assistance rules illustrating the use of aLDEAS (Ginon et al. 2014)¶
Green triangles represent events (observed by epi-detectors).
Yellow diamonds represent active information seeking by the assistance engine.
Orange squares represent assistance actions.
In order for assistance designers to easily define assistance rules, we have proposed aLDEAS (Ginon et al. 2014), a graphical language for expressing those rules. Fig. 3.5 shows two examples of rules described in aLDEAS (it is merely provided as an illustration here, the reader interested in a full description of the language should refer to the original paper). In addition to the language itself, we have provided a number of patterns, guiding the assistance designer in the definition of rules for the most common types of assistance. For example, we have a pattern for “guided tours” (a common assistance typically launched on the first execution of an application) and for step-by-step wizards (to assist the user in a complex task).
We have performed a number of experiments and user studies in order to assess the good properties of SEPIA and its generic architecture.
First the aLDEAS language is expressive enough to represent a large variety of assistance systems encountered in existing applications. It fails to represent a few specific assistance systems, such as recommender systems (as used in e-commerce or social applications). This can be seen as an inevitable drawback of our epiphytic approach, as those systems are intimately linked to the data handled by the application. We also had potential assistance designers use aLDEAS to specify assistance systems of their own, and they have been satisfied with its expressive power (Ginon et al. 2014).
We have also shown that assistance systems operated by SEPIA are generally well accepted by users, and that they are actually helpful. In particular, we conducted an experiment in the context of an advanced programming course (Ginon, Champin, and Jean-Daubias 2013). All students had a background in programming, but some of them were not familiar with the Netbeans IDE7, used in this course. SEPIA was used to assist them getting their bearings, leaving the teacher more time to answer questions related to the content of the course. After the course, the students answered a questionnaire, demonstrating an overall satisfaction with the assistance. Furthermore, the students passed a short test before and after the experiment, which showed that the assistance did indeed improve their knowledge of Netbeans. The teachers did also appreciate the assistance provided to their students, and express an interest in using the assistance again in the following semesters.
SEPIA provides a nice example of effective TBR (as presented in Section 2.4): with aLDEAS, assistance designers elaborate episode signatures that are further retrieved in real-time by the assistance engine, in order to trigger the epi-assistants. Furthermore, its epiphytic design allows several assistance systems to be defined for the same application. Each of them can address different kinds of users, different kinds of tasks, or simply provide a different perspectives of how to use the application.
SEPIA’s main limitation with respect to TBR is that it does not use transformations: the only events currently taken into account in assistance rules are those of the primary trace, the raw events collected by the epi-detectors (e.g. mouse click on interface components, individual keystrokes). This limitation could easily be lifted, though, as aLDEAS is generic enough to support more abstract kinds of events, which could be sought in transformed traces rather than directly from the epi-detectors. In fact, aLDEAS itself could be used to specify transformation rules8; while assistance rules result in assistance actions, transformation rules would result in the creation of new (more abstract) obsels (e.g. copy-paste, send an e-mail to a colleague) which could in turn participate in triggering other rules. This would make the task of assistance designers more modular, decoupling the interpretation of low-level activity from the decision of performing an assistance action.
The works presented above demonstrate how interaction traces (in various forms) can be tapped as knowledge about the user’s activity. They also emphasize the value of combining deterministic automated processings with subjective human interpretations, in a virtuous cycle that reveals the richness of those traces.
Notes
- 1
Similar approaches have been use by Kim et al. (2002) and Mulholland, Wolff, and Collins (2012) in the context of digital heritage.
- 2
- 3
http://heystaks.com/. Note that Heystaks has evolved a lot since this work was published, and that description may not match exactly the current state of the system.
- 4
It is a meta-recommender system in the sense that it recommends a stak, which is itself a recommender system (Schafer, Konstan, and Riedl 2002).
- 5
- 6
Those APIs are originally aimed at people with disabilities. They allow tools such as screen readers or Braille displays to access (and even interact with) other applications. Note that such tools are epiphytic systems, according to our definition above, hence our interest for accessibility technologies. Nevertheless, those APIs are not largely standardized (they vary with operating systems, graphical toolkits, etc.), so we had to use several of them to cover a wide range of applications.
- 7
- 8
Champalle et al. (2011) have already proposed to express a transformation as a set of rules, each rule being responsible of producing obsels of a given type. In that work, though, rules were expressed in SPARQL (Harris and Seaborne 2013).
Chapter bibliography
Adida, Ben, and Mark Birbeck. 2008. “RDFa Primer.” W3C Working Group Note. W3C. http://www.w3.org/TR/xhtml-rdfa-primer/.
Champalle, O., K. Sehaba, A. Mille, and Y. Prie. 2011. “A Framework for Observation and Analysis of Learners’ Behavior in a Full-Scope Simulator of a Nuclear Power Plant - Approach Based on Modelled Traces.” In 2011 11th IEEE International Conference on Advanced Learning Technologies (ICALT), 30–31. https://doi.org/10.1109/ICALT.2011.17.
Champin, Pierre-Antoine, Peter Briggs, Maurice Coyle, and Barry Smyth. 2010. “Coping with Noisy Search Experiences.” Knowledge-Based Systems, Artificial Intelligence 2009AI-2009The 29th SGAI International Conference on Artificial Intelligence, 23 (4): 287–94. https://doi.org/10.1016/j.knosys.2009.11.011.
Fuchs, Béatrice, and Amélie Cordier. 2016. “Interprétation Interactive de Connaissances à Partir de Traces.” In Ingénierie Des Connaissances 2016, edited by Nathalie Pernelle, 167. Actes Des 27es Journees Francophones d’Ingenierie Des Connaissances - IC 2016. Montpellier, France: Sandra Bringay. https://hal.archives-ouvertes.fr/hal-01343518.
Ganalis, Dimitrios, and Ion Androutsopoulos. 2007. “Generating Multilingual Descriptions from Linguistically Annotated OWL Ontologies: The NaturalOWL System.” In 11th European Workshop on Natural Language Generation (ENLG 2007), 1–4. Schloss Dagstuhl, Germany.
Ginon, Blandine. 2014. “Modèles et outils génériques pour mettre en place des systèmes d’assistance épiphytes.” Thèse de Doctorat en Informatique, INSA de Lyon, Université de Lyon. http://liris.cnrs.fr/publis/?id=6885.
Ginon, Blandine, Pierre-Antoine Champin, and Stéphanie Jean-Daubias. 2013. “Collecting Fine-Grained Use Traces in Any Application without Modifying It.” In Workshop EXPPORT from the Conference ICCBR. http://liris.cnrs.fr/publis/?id=6141.
Ginon, Blandine, Stéphanie Jean-Daubias, Pierre-Antoine Champin, and Marie Lefevre. 2014. “ALDEAS: A Language to Define Epiphytic Assistance Systems.” In Knowledge Engineering and Knowledge Management (EKAW’14), edited by Krzysztof Janowicz, Stefan Schlobach, Patrick Lambrix, and Eero Hyvönen, 8876:153–64. LNCS. Linköping, Sweden: Springer. https://doi.org/10.1007/978-3-319-13704-9_12.
Harris, Steve, and Andy Seaborne. 2013. “SPARQL 1.1 Query Language.” W3C Recommendation. W3C. http://www.w3.org/TR/sparql11-query/.
Kim, Sanghee, Harith Alani, Wendy Hall, Paul Lewis, David Millard, Nigel Shadbolt, and Mark Weal. 2002. “Artequakt: Generating Tailored Biographies from Automatically Annotated Fragments from the Web.” http://eprints.ecs.soton.ac.uk/6913.
Kong Win Chang, Bryan, Marie Lefevre, Nathalie Guin, and Pierre-Antoine Champin. 2015. “SPARE-LNC : Un Langage Naturel Contrôlé Pour l’interrogation de Traces d’interactions Stockées Dans Une Base RDF.” In Journées Francophones d’Ingénierie Des Connaissances. Rennes, France: AFIA. https://hal.archives-ouvertes.fr/hal-01164383.
Mulholland, Paul, Annika Wolff, and Trevor Collins. 2012. “Curate and Storyspace: An Ontology and Web-Based Environment for Describing Curatorial Narratives.” In The Semantic Web: Research and Applications (ESWC’12), edited by Elena Simperl, Philipp Cimiano, Axel Polleres, Oscar Corcho, and Valentina Presutti, 7295:748–62. LNCS. Springer. https://doi.org/10.1007/978-3-642-30284-8_57.
Naja-Jazzar, Hala, Nishadi de Silva, Hala Skaf-Molli, Charbel Rahhal, and Pascal Molli. 2009. “OntoReST: A RST-Based Ontology for Enhancing Documents Content Quality in Collaborative Writing.” INFOCOMP Journal of Computer Science 8 (3): 1–10.
Schafer, J. B., J. A. Konstan, and J. Riedl. 2002. “Meta-Recommendation Systems: User-Controlled Integration of Diverse Recommendations.” In Proceedings of the Eleventh International Conference on Information and Knowledge Management, 43–51. ACM New York, NY, USA.
Taboada, Maite, and William C. Mann. 2006. “Rhetorical Structure Theory: Looking Back and Moving Ahead.” Discourse Studies 8 (3): 423–59. https://doi.org/10.1177/1461445606061881.
Yahiaoui, Leila, Yannick Prié, Zizette Boufaïda, and Pierre-Antoine Champin. 2011. “Redocumenting Computer Mediated Activity from Its Traces: A Model-Based Approach for Narrative Construction.” Journal of Digital Information (JoDI) 12 (3). https://journals.tdl.org/jodi/index.php/jodi/article/view/2088.