4. Web and Semantic Web¶
Since the Web was invented some 25 years ago, its pervasiveness has grown to the point of becoming trite. The Web has become a primary means of communication between colleagues, family members and friends; it is being used for work, leisure, shopping, paying taxes, finding a restaurant, a job, or a date… It connects our computers, our phones, our TV-sets, and a growing number of other (and sometimes unexpected) items, such as fridges, cars, electricity-meters or flowerpots.
Not only has it changed the amount of information available to us, it has changed dramatically how we acquire, handle and use this information, and turn it into knowledge. Therefore, it brings both a challenge and an opportunity, to better understand and to assist these new practices (Berners-Lee et al. 2006, chap.5). Since these are computer-mediated, using digital traces seems a natural way to achieve those goals. And since the Web is so pervasive, the available information is bound to be interpreted differently by different agents, or even by the same agent in different contexts, hence a need to take ambivalence into account.
This chapter gathers a variety of works that we have done in a research context, but also in the context of standardization groups, more precisely groups in the W3C, of which Université de Lyon is a member since 2012. Those works are presented along three dimensions: the use of activity traces on the Web, the acknowledgment of ambivalence in Web technologies and Web standards, and how those aspects may lead to new paradigms to design Web applications.
4.1. Putting Web traces to good use¶
As stated above, our activity on the web accounts so much for our lives that the traces of that activity can provide a huge amount of knowledge about us. Indeed Web companies such as Facebook (Kramer 2012) or Google (Bonneau et al. 2015) have a long history of tapping the traces of their users to provide better targetted services (and advertisements). Some of them, as Netflix1 or Yahoo2, have even opened some of their data to a wider research community, in order to find better ways to capture the collective knowledge of a large number of users.
However, as stated in Section 2.2, our approach is more focused on capturing the individual experience of each traced user. In her presentation of the “small data” approach, Estrin (2014) explains how health problems could be detected earlier through changes in individual behavioral patterns. While of primary importance for the users themselves, those changes may be less relevant for the companies currently holding and exploiting the users’ traces. Furthermore, many users would have concerns about those companies monitoring their health status.
Another effect of our traces being exploited out of our control is what Pariser (2011) calls the “filter bubble”: the fact that the content provided to us by search engines and social networks are tailored to meet our preferences, as computed from our activity traces. Of course it can be seen as a benefit, helping us find what we are looking for in an overwhelming amount of information. But on the other hand, those social tools paradoxically isolate us from whole parts of the Web, and this is all the more pernicious that they keep an aura of exhaustivity and objectivity (after all, they have access to the whole Web).
Querying the Web¶
Pariser advocates a way to disable the personalization mechanisms, in order to be able to access the Web more objectively. This has been supported by some search engines such as DuckDuckGo3 or Qwant4. An alternative, and a way to compensate the lack of that feature in other systems, is to provide users with access to their traces and tools to analyze them. While this would not suppress the filter bubble, at least it would allow users to know what bubble they are in, and how their behavior alters that bubble.
The work about Heystaks presented in Chapter 2 provides such an alternative: by choosing a given stak as the context of their Web searches, users consciously select their filter bubble. Furthermore, they can register to as many staks as they like, allowing them to chose the bias on each of their search results5. Finally, the stak curation tools give users access to the full history of searches performed in a given stak, providing insight on which parts of one’s behavior participates to stak recommendations.
In the PhD work of Rakebul Hasan (2014b), we focused on analyzing and synthesizing the information of traces, to help users understand and predict the outcome of querying linked data on the Web. First, machine learning techniques have been used on a set of SPARQL query evaluations, in order to identify which features of a query are predictive of its execution time. This differs from other approaches, which rather rely on the structure of the queried data. Second, by tracing the execution of the query engine itself, explanations in the form of why-provenance are generated and provided to users, in order to help them understand the query results, especially when inferences are involved (see Fig. 4.1-a). Such explanations can in turn be published as linked data, using RQ4 (Hasan 2014a), an extension of the PROV-O vocabulary (Lebo, Satya Sahoo, and McGuinness 2013). Finally, as those explanations can become quite verbose for complex queries, a summarization process for explanation (illustrated in Fig. 4.1-b) has been proposed and evaluated.

Fig. 4.1 Examples of a full explanation and a summarized explanation (Hasan 2014b)¶
Traces for learning on the Web¶
We have also proposed a number of innovative uses of Web traces in the context of COAT6, an exploratory project aimed at studying the research opportunities of e-learning, more specifically of Massive Open Online Courses (MOOCs). In those systems, learners are so many and so heterogeneous that standard indicators and monitoring tools can not be used (Buffat, Mille, and Picasso 2015); more flexible and scalable ones must be proposed. Furthermore, with MOOCs, the learning activity is no more confined to the hosting platform, as the learners are often pointed to external contents. Meaningful indicators can therefore only be computed by monitoring the learners’ activity inside and outside the MOOC platform.
TraceMe7 is a browser extension designed to trace the whole browsing activity of a user. Since it runs on the client-side, it is not restricted to tracing the activity on a given server. In addition, it can trace interactions that would be otherwise invisible to the server (such as navigation through internal links inside a page, interactions with an embedded video or audio player, etc.). But most importantly, TraceMe has to be installed voluntarily by the user, who may enable or disable the tracing at any moment. TraceMe can also be configured with several MTMSs, and the user can choose on which of them the traces should be collected. For example, a user may collect her traces on the MTMS provided by the MOOC when she is browsing content in relation with the course, and on a personal MTMS when she is browsing for other purposes. This kind of practice is actually encouraged in the emerging standard Tin Can (also known as the Experience API8), in which the notion of Learning Record Store (LRS) closely resembles our notion of MTMS. We are currently working on making TraceMe and kTBS (our MTMS reference implementation) interoperable with Tin Can9.
SamoTraceMe10 is a Web application aimed as a companion application to TraceMe. As illustrated by Fig. 4.2, it provides various ways to visualize one’s trace, as well as tools to customize those visualizations. In order to help learners and teachers to analyze traces, SamoTraceMe also provides tools to build, execute and share indicators, i.e. synthetic representation of the information conveyed by the trace. More precisely, the “Indicator Back-Office” provides user-friendly tools to transform traces (as described in Chapter 2), and query them using the natural-language interface proposed by Kong Win Chang et al. (2015). That way, users can explore and design new indicators, better suited to MOOCs than those available in the litterature, as emphasized above. For the same reason, SamoTraceMe not only encourages the building of new indicators, but also their sharing with others (in the last tab “Indicator Store”). In that sense, it is a tool for learners and teachers as much as for researchers in education sciences, making all of them actors of that research.
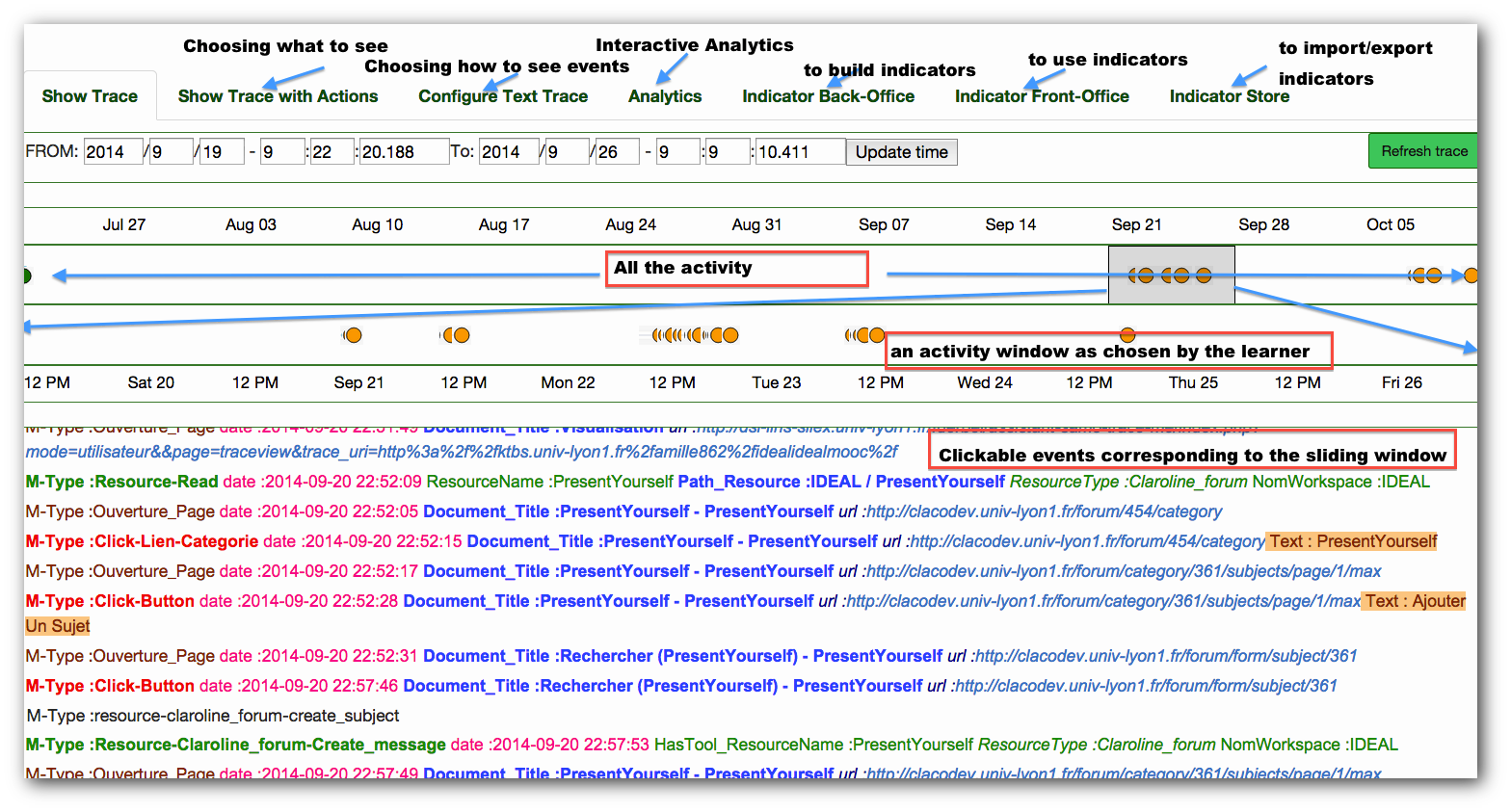
Fig. 4.2 The main screen of SamoTraceMe (Buffat, Mille, and Picasso 2015)¶
It contains (from top to bottom): tabs providing access to the various functionalities; a graphical timeline representing the whole trace; a graphical timeline zooming on the time-window selected in the above timeline; a hyper-textual representation of the selected time window, as a list of events (obsels).
Recently, we have started working on Taaabs11, a set of reusable components for visualizing and interacting with traces, aimed at capitalizing on the experience acquired with SamoTraceMe and other works (Barazzutti, Cordier, and Fuchs 2015; Kong Win Chang et al. 2015). Taaabs relies on Web Components, a coming W3C standard (Glazkov 2016), so that each component is available as a custom HTML element. The goal is to make it as easy as possible for developers to add trace-based functionalities to their applications. A longer term goal is to allow end-users to interactively build their customized dashboard by drag-and-dropping visual components.
Interoperability¶

Fig. 4.3 PROV Core Structure (Lebo, Satya Sahoo, and McGuinness 2013)¶
We also aim to improve the integration of our trace meta-model (as described in Chapter 2) with other models gaining momentum on the Web. One of them is PROV (Moreau and Missier 2013; Lebo, Satya Sahoo, and McGuinness 2013), a standard data-model for representing provenance information on the Web, hence concerned with traceability. A central element of this data-model (depicted in Fig. 4.3) is the notion of Activity, during which the object of the provenance information (the Entity) was produced or altered. This notion of Activity has an obvious kinship with our notion of obsel. PROV also defines interesting relations between entities. An entity specializes another entity “if it shares all aspects of the latter, and additionally presents more specific aspects”; for example, the second edition of a book is a specialization of that book (as a work); P-A. Champin as a researcher is a specialization of P-A. Champin as a person; P-A. Champin as mentioned in this document is a specialization of P-A. Champin as a researcher. While the specialized entity inherits the properties of the general one, the opposite is not true. This allows to make assertions with a limited scope, hence to have different interpretations coexist in the same knowledge base. PROV has its own data model, but defines a mapping with RDF.
Another model for representing traces on the Web is Activity Streams, an independent format (J. M. Snell et al. 2011) recently endorsed by the W3C Social Web Working Group (J. Snell and Prodromou 2016). This format is intended to represent actions performed by a user, typically in the context of a social network application. It is extensible, and the most recent version is based on JSON-LD (Sporny, Kellogg, and Lanthaler 2014), making it interoperable with RDF and other Semantic Web technologies.
As mentioned above, Tin Can8 is another format for capturing traces, focused on the domain of e-learning. Originally based on Activity Streams, it has then slightly diverged from it. In particular it is not based on the RDF data model, but De Nies et al. (2015) have proposed an approach to bridge this gap, by mapping it to PROV. Tin Can is currently being considered in the Hubble project12 as an interoperability layer between the different platforms of the partners (including our own).
In his master’s thesis, Cazenave-Lévêque (2016) has compared those emerging standards (and others) to our meta-model. While the latter focuses exclusively on time-anchored elements (obsels), the others allow to describe a number of objects that are not (or at least not explicitly) related to time. We have therefore proposed an extension of our meta-model, where additional information can be attached to a trace, or to an obsel. The first case is useful for representing background knowledge, that is assumed to hold for the whole duration of the trace (such as names and addresses of the persons involved in the activity). The second case is useful for representing contextual information captured at the same time as the obsel, and that is only assumed to hold for the duration of that obsel (such as the heart rate or mood of the person performing an observed action). We have shown that those extensions allow us to capture the semantics of PROV and Tin Can in our meta-model, and hence to integrate existing Web traces in an MTBS.
4.2. Ambivalence on the Web¶
Ambivalent documents¶
The distinction, in a document, between its physical structure and its logical structure, has long been identified and theorized. This is, in particular, why the original HTML (mixing concerns about both structures) was later split into CSS (addressing the physical structure, i.e. presentation) and the cleaner HTML 4 (restricted to the logical structure). But this dichotomy, however useful, is not always sufficient to capture the different overlapping structures of more complex documents, such as acrostics13, multimedia or hypermedia documents. In such cases, the multiple structures can lead to multiple interpretations.
In 2003, a working group funded by the Rhône-Alpes region was formed in Lyon to investigate that topic. We proposed a formal model and an XML-based syntax for representing documents with an arbitrary number of structures (Abascal et al. 2003; 2004). This model allowed us to represent not only a multi-structured document, but also a curated corpus of such documents, where the corpus is considered itself as a document, with its own additional structures spanning the documents it contains (for example, a thematic index). It was also a way to capture altogether the original structures of a document, and the annotations added afterwards by a community of reader. This last point was further explored in the works described in the next chapter.
But the evolution of the Web has also forced ambivalence into HTML itself. The growing importance of the mobile Web, and the diversity of the devices used to display HTML content, have made responsiveness an unavoidable part of web design (Marcotte 2010). The goal is to design HTML contents such that they can be equally easy to read and use on devices with different screen sizes, but also with different interaction modalities (mouse and keyboard, touchscreen, remote control…). One could argue that, in responsive design, only presentation (managed by CSS) and interactions (managed by Javascript) are changed, but the logical structure conveyed by HTML is the same, and therefore there is no ambivalence here. However, responsive design can not be reduced to adding clever CSS and Javascript to any HTML document; the document structure has to be designed accordingly: unresponsive HTML is strongly coupled to one particular presentation, responsive HTML is abstract enough to be presented, hence interpreted 14, in various ways, so we argue that it has a form of ambivalence.
Weaving documents and data¶
HTML has also been used in various ways to convey other information that the document structures it was initially meant for. This provides another nice example of the need to support ambivalence in an open context as the Web, and how this has actually been achieved.
SHOE (Heflin, Hendler, and Luke 1999), the Simple HTML Ontology Extensions, is an early attempt at realizing the Semantic Web by embedding machine-readable knowledge into human-targetted HTML documents. It allows any Web page to define its own ontology (as a set concepts and relations) or reuse an existing one, then to describe its content using this ontology (see the example in Listing 4.1). The formal semantics of SHOE is purposefully lightweight, to ensure the scalability of the corresponding reasoning algorithms.
Let us note that, although SHOE uses HTML to “host” machine-readable data, this data is still quite separate from the human-readable content (it is enclosed in specialized HTML tags). Extending HTML in that case is mostly a way to ease the publication of ontologies, and to keep a link between human-readable and machine-readable information, although at a relatively coarse granularity (that of the page).
RDFa (Adida and Birbeck 2008), on the other hand, proposes to use HTML attributes to represent fine-grained annotation of the human-readable content, which can in turn be interpreted as RDF data (see the example in Listing 4.2). This strongly reduces redundancy compared to SHOE (or other approaches where RDF is published in a completely separate file), making it more space-efficient and, more importantly, easier to author and maintain. Styles, Shabir, and Tennison (2009) have even proposed a system where, through editing an RDFa-annotated document with a WYSIWYG interface, users not only update the visible human-readable content, but also the underlying machine-readable data, even without being aware of the latter.
In parallel to RDFa, the Microformats community15 has been pursuing a similar goal (fine-grain annotations of HTML content to provide machine-readable information) but without willing to commit to RDF for their data model. Later, Schema.org16 was announced by a consortium of search engines (Goel and Gupta 2011), confirming the trend to use HTML to address both machines and humans, by weaving two complementary kinds of information.
<P> Hi, this is my web page.
I am a graduate student and a research assistant.
<P> Also, I'm 52 years old.
<P> My name is George Stephanopolous.
<INSTANCE KEY="http://www.cs.umd.edu/users/george/">
<USE-ONTOLOGY
ID="cs-dept-ontology"
URL="http://www.cs.umd.edu/projects/plus/SHOE/onts/cs.html"
VERSION="1.0"
PREFIX="cs">
<CATEGORY NAME="cs.GraduateStudent">
<CATEGORY NAME="cs.ResearchAssistant">
<RELATION NAME="cs.name">
<ARG POS=TO VALUE="George Stephanopolous">
</RELATION>
<RELATION NAME="cs.age">
<ARG POS=TO VALUE="52">
</RELATION>
</INSTANCE>
<div prefix="cs: http://www.cs.umd.edu/projects/plus/SHOE/onts/cs.html#"
about="http://www.cs.umd.edu/users/george/">
<p> Hi, this is my web page.
I am a
<span rel="rdf:type" resource="cs:GraduateStudent">
graduate student</span>
and a
<span rel="rdf:type" resource="cs:ResearchAssistant">
research assistant</span>.
<p> Also, I'm <span property="cs:age">52</span> years old.
<p> My name is <span property="cs:name">George Stephanopolous</span>.
</div>
Ambivalent data¶
Of course, data on the Web is not only embedded in HTML, but also available under many other formats, and working with heterogeneous data often requires to reinterpret them. For example, in order to ease the composition of heterogeneous data-providing services, we have proposed to interpret their output as the result of SPARQL queries (Barhamgi et al. 2007). More precisely, we considered all the available data as a virtual global RDF graph; then we attached to each service the parameterized SPARQL query on that graph that would return the same data as the service. Our system was able to solve a SPARQL query by decomposing it into sub-queries corresponding to the available services, effectively computing the appropriate service composition.
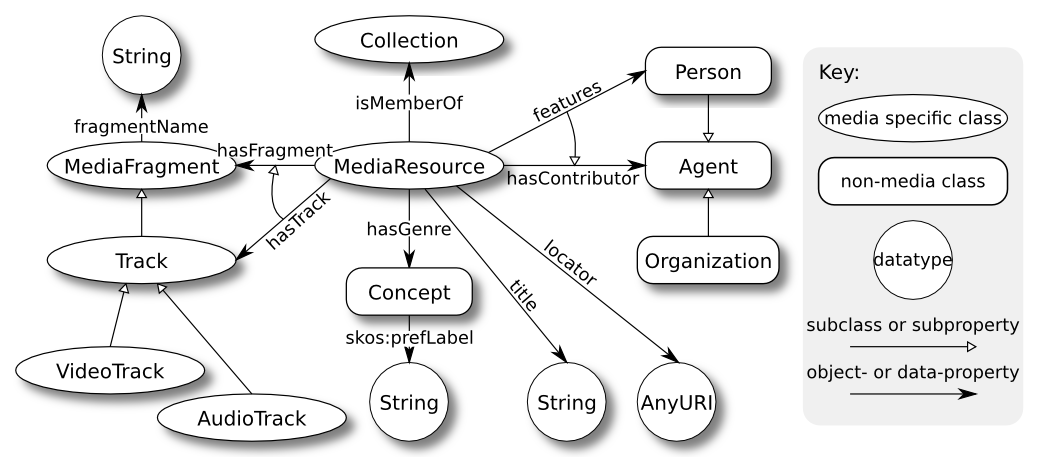
Fig. 4.4 Class model excerpt of the Ontology for Media Resource 1.0 (Stegmaier et al. 2013)¶
Data heterogeneity is also a critical problem in the field of multimedia documents. While this obviously applies to the multimedia data itself, this causes even more acute problems with the meta-data describing the media object (title, author, date of creation, etc.). Indeed, meta-data formats are not differing in their syntax only, but also in their terminologies, the granularity of the represented information, and more generally, the underlying concepts.
The W3C Multimedia Annotation Working Group (MAWG) was created to address the problem of meta-data heterogeneity, among a list of widespread formats. We proposed an ontology (Lee et al. 2012) capturing the core meta-data concepts identified in those formats (illustrated in Fig. 4.4), as well as mappings from each format to this ontology. This mapping allows to re-interpret legacy meta-data into the common frame of reference provided by the MAWG ontology.
I was also a member of the RDF 1.1 Working Group, who was chartered in 2011 to update the 2004 version of that standard, based on feedback from the community. An important action of that group was to endorse JSON-LD (Sporny, Kellogg, and Lanthaler 2014) as a concrete syntax for RDF based on the popular format JSON. JSON-LD allows to attach a context to any JSON data, either in the data itself, or via out-of-band information. The role of a JSON-LD context is to disambiguate and elicit the semantics of the data, by allowing to convert it to an RDF dataset. Legacy JSON can therefore be kept as is, and still be processed by ad hoc programs ignoring the context; however it can also be processed by more generic programs, with no prior knowledge of the data structure, but able discover it and possibly make inferences with the corresponding RDF data. As such, JSON-LD is more than just another RDF serialization: it makes RDF data easier to consume for the average Web developer, and it makes legacy JSON data easily (and often quite directly) interoperable with the rest of the Web of data. In fact, JSON-LD is an ambivalent data format, designed to be equally suiting two communities with different expectations.
In another work (Steiner et al. 2014), we have proposed to apply a similar approach to another format, WebVTT (Pieters 2016). WebVTT is the proposed standard to represent text tracks for HTML5 videos. The most common use of those text tracks is to encode subtitles or captions, but they allow other uses, such as describing chapters or time-anchored other meta-data. To make that information usable outside Web browsers, we therefore suggest that WebVTT should and can be interpretable as Linked Data. We have proposed an RDF vocabulary capturing the concepts of WebVTT, and implemented a prototype converting any WebVTT into a standard RDF concrete syntax. This was made possible by leveraging Media Fragment URIs (Troncy et al. 2012), a standard way to identify fragments of a multimedia resource with a URI. A future development of this work would be map our vocabulary to the emerging Web Annotation Data Model (Sanderson, Ciccarese, and Young 2016).
4.3. Rethinking Web application design¶
The efforts described above to make the Web a machine-friendly data space, in addition to being a human-friendly document space, have mostly focused on helping machines read and understand those data. But the Web is not “read-only”, users are not merely consuming information. They are as well producing it, either directly through posting, commenting, rating (using HTML forms or Javascript applications) or indirectly in the interaction traces they leave on the sites they visit.
The Web Services community has striven to enable machines to interact with Web applications, in a way similar to what human users do. There is indeed an ever-growing number of Web APIs17, but the semantics of each API has to be hard-coded into software clients, making them unable, unlike humans, to adapt to changes or discover and use similar services. So while the Web was initially designed as a unified and loosely coupled environment, where any client could connect to any server, the Web of services has become a siloed and strongly coupled environment, where an ad hoc client is required for every new service. Although this problem should be mitigated by following the REST architectural style (Fielding 2000), Baker (2008) notices that many self-proclaimed RESTful services are lacking an important feature of that style: Hypermedia controls. Fielding defines Hypermedia as “the presence of application control information embedded within (…) the presentation of information”. In other terms, in order to interact with a service, a client should require almost no out-of-band static knowledge about that service, and mostly rely on the information dynamically retrieved from it.
In order to solve that problem, the W3C Linked Data Platform (LDP) working group was chartered to propose a standard RESTful way to interact with linked data. I was part of that group, who published the LDP recommendation (Speicher, Arwe, and Malhotra 2015). That recommendation specifies the operations that a compliant service must support, and how such a service can advertise to clients that it complies with LDP. It also defines a notion of container, allowing clients to dynamically discover or create new resources. As such, LDP meets the Hypermedia requirements stated above: any LDP-aware client can readily interact with any LDP-compliant server, using only the information provided by that server. However, those interactions are somehow limited. For example, LDP provides no standard way for the server to declare the types of resources it may contain, what properties are allowed or required, etc.

Fig. 4.5 The SOLID platform compared to the “silo” model¶
That limitation is not a problem if LDP servers are only expected to passively store resource representations, leaving client applications to deal with specific resource semantics (i.e. application logic). This is the approach chosen by Mansour et al. (2016) for the SOLID platform. In this platform, applications do not host user’s data on their own server (as is currently the case in most Web applications); instead, data storage is delegated to an LDP server owned and controlled by the user (see Fig. 4.5). Beyond the obvious benefit in terms of privacy, this provides users with more control over their data: they can chose which part of those data each application will be authorized to use. They can even chose to grant an application with access the data produced by another one, while currently, this choice is ultimately made by the application providers18. On the other hand, while applications can communicate asynchronously through the data they store in the personal LDP server, this approach leaves entirely open the question of a more direct composition of services.
In parallel to LDP, the W3C community group Hydra has chosen to tackle that problem differently (Lanthaler and Gütl 2013). Like LDP, Hydra advocates the RDF data-model, by encouraging the use of JSON-LD. Unlike LDP, Hydra does not aim to define a unique interaction model with resources, but instead provides an RDF vocabulary for describing the particular Hypermedia controls of each service. More precisely, a Hydra service publishes an API documentation describing (1) the types of resources that compose the service, with their properties, and (2) which operations are available on different resources and property values, and how they can be performed in terms of HTTP requests. Hydra provides abstraction for the most common operations (resource creation, modification and deletion, search, pagination). More specific semantics can either be interpreted by the end-user (for interactive Hydra clients), built-in into specialized clients, or discovered dynamically using Linked Data principles (dereferencing unknown terms to retrieve their definition). One success story of Hydra is the Triple Pattern Fragment (TPF) interface, a scalable protocol for accessing and querying RDF data on the Web (Verborgh et al. 2016). The flexibility of Hydra makes it possible for servers to implement and/or extend that interface in many various ways, without breaking existing clients. What’s more, Verborgh (2016) demonstrated that, to some extent, some server extensions can even benefit old clients that are not aware of these extensions.
Our MTMS kTBS is designed as a RESTful service using RDF as its internal data-model, so we had to deal with problems very similar to those that would later be addressed by LDP and Hydra (which then encouraged me to join both groups). To address those problems, we proposed the RDF-REST framework (Champin 2013; Médini et al. 2014). In RDF-REST, all resources (local or remote) are handled the same way, through a uniform interface (which translates seamlessly to HTTP verbs in the case of remote resources). Resource representations are mapped to RDF graphs, regardless of their original format, thanks to an extensible library of parsers and serializers; this feature allows RDF-REST applications to inter-operate with third-party services. Note that RDF-REST takes into account ambivalence, as different RDF-REST applications could have different interpretations of the data published by third-party services. This would only require them use a different set of parsers/serializers.
This framework could easily be used to implement LDP servers, even if it does not enforce LDP compliance (it allows to implement different interaction models). It would even more easily inter-operate with other LDP servers, as they already provide RDF representations. It is equally easy to publish a Hydra API documentation for an RDF-REST service, although currently this documentation has to be manually edited, independently from the code. In a future version of RDF-REST, we plan to reverse this workflow, by requiring service developers to write an API documentation, and using it to drive the behavior the service (at least the part captured by the Hydra vocabulary – for more specific behaviors, the developer will still have to code). This will prevent duplication of code and guarantee the compliance of the API documentation with the actual implementation of the service.
Throughout the works (ours and others) presented in this chapter, it can be seen how support for ambivalence and multiple interpretations is a recurring concern in Web based applications. It can not be otherwise given the large scale and the inherent openness of the Web. Moreover, this challenge is constantly renewed by the fast evolution of Web technologies, as much as that of the uses of the Web.
Notes
- 1
- 2
http://webscope.sandbox.yahoo.com/catalog.php?datatype=r&did=75
- 3
- 4
- 5
To choose, quoting Pariser’s metaphor, between “information vegetable” and “information dessert”.
- 6
- 7
- 8(1,2)
- 9
In fact, the RESTful protocol defined by the Tin Can API is very similar to the one used by kTBS, so we are confident that this integration should not be too hard to achieve.
- 10
- 11
- 12
- 13
An acrostic is a poem (or other form of writing) in which the first letter (or syllabe or word) of each line (or paragraph, or other recurring feature in the text) spells out a word or a message. (from Wikipedia)
- 14
This kinship between presentation and interpretation will be further discusses in Chapter 6.
- 15
- 16
- 17
- 18
It is true that, in many cases, the user is asked for permission before an application shares their data with another one. However, users can only have this choice if both application providers have a prior agreement, and furthermore, nothing prevents them (technically, at least) to share this information without the user’s consent.
Chapter bibliography
Abascal, Rocio, Michel Beigbeder, Aurélien Bénel, Sylvie Calabretto, Bertrand Chabbat, Pierre-Antoine Champin, Noureddine Chatti, et al. 2003. “Modéliser La Structuration Multiple Des Documents.” In Créer Du Sens à l’ère Numérique (H2PTM’03), 253–57. Hermes. http://liris.cnrs.fr/publis/?id=993.
Abascal, Rocio, Aurélien Bénel, Michel Beigbeder, Sylvie Calabretto, Bertrand Chabbat, Pierre-Antoine Champin, Noureddine Chatti, et al. 2004. “Un Modèle de Document à Structures Multiples.” In Sciences of Electronic, Technology of Information and Telecommunications (SETIT2004), 00. http://liris.cnrs.fr/publis/?id=1254.
Adida, Ben, and Mark Birbeck. 2008. “RDFa Primer.” W3C Working Group Note. W3C. http://www.w3.org/TR/xhtml-rdfa-primer/.
Baker, Mark. 2008. “Hypermedia in RESTful Applications.” InfoQ (blog). January 28, 2008. https://www.infoq.com/articles/mark-baker-hypermedia.
Barazzutti, Pierre-Loup, Amélie Cordier, and Béatrice Fuchs. 2015. “Transmute: An Interactive Tool for Assisting Knowledge Discovery in Interaction Traces.” Research Report. Universite Claude Bernard Lyon 1 ; Universite Jean Moulin Lyon 3. https://hal.archives-ouvertes.fr/hal-01172013.
Barhamgi, Mahmoud, Pierre-Antoine Champin, Djamal Benslimane, and Aris M. Ouksel. 2007. “Composing Data-Providing Web Services in P2P-Based Collaboration Environments.” In Advanced Information Systems Engineering, 19th International Conference, CAiSE 2007, Trondheim, Norway, June 11-15, 2007, Proceedings, edited by John Krogstie, Andreas L. Opdahl, and Guttorm Sindre, 4495:531–545. Lecture Notes in Computer Science. Springer. https://doi.org/10.1007/978-3-540-72988-4_37.
Berners-Lee, Tim, Wendy Hall, James A. Hendler, Kieron O’Hara, Nigel Shadbolt, and Daniel J. Weitzner. 2006. “A Framework for Web Science.” Found. Trends Web Sci. 1 (1): 1–130. https://doi.org/10.1561/1800000001.
Bonneau, Joseph, Elie Bursztein, Ilan Caron, Rob Jackson, and Mike Williamson. 2015. “Secrets, Lies, and Account Recovery: Lessons from the Use of Personal Knowledge Questions at Google.” In 24th International Conference on World Wide Web, 141–150. Florence, Italy: ACM. http://dl.acm.org/citation.cfm?id=2736277.2741691.
Buffat, Marc, Alain Mille, and Marco Picasso. 2015. “Feedbacks on MOOCS.” In CANUM 2014, edited by Franck Boyer, Thierry Gallouet, Raphaèle Herbin, and Florence Hubert, 50:66–80. Carry-le-Rouet, FR: ESAIM: Proceedings and Surveys. https://doi.org/10.1051/proc/201550004.
Cazenave-Lévêque, Raphaël. 2016. “Interoperability among Trace Formalisms.” Master’s Thesis, Université Lyon 1.
Champin, Pierre-Antoine. 2013. “RDF-REST: A Unifying Framework for Web APIs and Linked Data.” In Services and Applications over Linked APIs and Data (SALAD), Workshop at ESWC, 1056:10–19. CEUR. Montpellier, France: CEUR Workshop Proceedings. https://hal.archives-ouvertes.fr/hal-00921662.
De Nies, Tom, Frank Salliau, Ruben Verborgh, Erik Mannens, and Rik Van de Walle. 2015. “TinCan2PROV: Exposing Interoperable Provenance of Learning Processes through Experience API Logs.” In Proceedings of the 24th International Conference on World Wide Web Companion, 689–94. ACM Press. https://doi.org/10.1145/2740908.2741744.
Estrin, Deborah. 2014. “Small Data, Where n = Me.” Commun. ACM 57 (4): 32–34. https://doi.org/10.1145/2580944.
Fielding, Roy Thomas. 2000. “Architectural Styles and the Design of Network-Based Software Architectures.” Doctoral dissertation, University of California, Irvine. http://www.ics.uci.edu/%7Efielding/pubs/dissertation/top.htm.
Glazkov, Dimitri. 2016. “Custom Elements.” W3C Working Draft. W3C. https://www.w3.org/TR/custom-elements/.
Goel, Kavi, and Pravir Gupta. 2011. “Introducing Schema.Org: Search Engines Come Together for a Richer Web.” Official Google Webmaster Central Blog (blog). June 2, 2011. https://webmasters.googleblog.com/2011/06/introducing-schemaorg-search-engines.html.
Hasan, Rakebul. 2014a. “Generating and Summarizing Explanations for Linked Data.” In The Semantic Web: Trends and Challenges (Proceedings of ESWC 2014), 473–487. Springer. https://doi.org/10.1007/978-3-319-07443-6_32.
———. 2014b. “Predicting Query Performance and Explaining Results to Assist Linked Data Consumption.” Phd Thesis, Université de Nice-Sophia Antipolis.
Heflin, Jeff, James Hendler, and Sean Luke. 1999. “SHOE: A Knowledge Representation Language for Internet Applications.” http://drum.lib.umd.edu/handle/1903/1044.
Kong Win Chang, Bryan, Marie Lefevre, Nathalie Guin, and Pierre-Antoine Champin. 2015. “SPARE-LNC : Un Langage Naturel Contrôlé Pour l’interrogation de Traces d’interactions Stockées Dans Une Base RDF.” In Journées Francophones d’Ingénierie Des Connaissances. Rennes, France: AFIA. https://hal.archives-ouvertes.fr/hal-01164383.
Kramer, Adam D.I. 2012. “The Spread of Emotion via Facebook.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 767–770. CHI ’12. New York, NY, USA: ACM. https://doi.org/10.1145/2207676.2207787.
Lanthaler, Markus, and Christian Gütl. 2013. “Model Your Application Domain, Not Your JSON Structures.” In Proceedings of the 22Nd International Conference on World Wide Web, 1415–1420. WWW ’13 Companion. New York, NY, USA: ACM. https://doi.org/10.1145/2487788.2488184.
Lebo, Timothy, Satya Sahoo, and Deborah McGuinness. 2013. “PROV-O: The PROV Ontology.” W3C Recommendation. W3C. https://www.w3.org/TR/prov-o/.
Lee, WonSuk, Werner Bailer, Tobias Bürger, Pierre-Antoine Champin, Jean-Pierre Evain, Véronique Malaisé, Thierry Michel, et al. 2012. “Ontology for Media Resources 1.0.” W3C Recommendation. W3C. http://www.w3.org/TR/mediaont-10/.
Mansour, Essam, Andrei Vlad Sambra, Sandro Hawke, Maged Zereba, Sarven Capadisli, Abdurrahman Ghanem, Ashraf Aboulnaga, and Tim Berners-Lee. 2016. “A Demonstration of the Solid Platform for Social Web Applications.” In Proceedings of the 25th International Conference Companion on World Wide Web, 223–226. International World Wide Web Conferences Steering Committee. http://dl.acm.org/citation.cfm?id=2890529.
Marcotte, Ethan. 2010. “Responsive Web Design.” A List Apart (blog). May 25, 2010. http://alistapart.com/article/responsive-web-design.
Médini, Lionel, Pierre-Antoine Champin, Michaël Mrissa, and Amélie Cordier. 2014. “Towards Semantic Resource Mashups.” In Services and Applications over Linked APIs and Data (SALAD), Workshop at ESWC, 6–9. CEUR Workshop Proceedings. http://liris.cnrs.fr/publis/?id=6685.
Moreau, Luc, and Paolo Missier. 2013. “PROV-DM: The PROV Data Model.” W3C Recommendation. W3C. http://www.w3.org/TR/prov-dm/.
Pariser, Eli. 2011. Beware Online “Filter Bubbles.” TED Talk. https://www.ted.com/talks/eli_pariser_beware_online_filter_bubbles.
Pieters, Simon. 2016. “WebVTT: The Web Video Text Tracks Format.” Draft Community Group Report. W3C. https://w3c.github.io/webvtt/.
Sanderson, Robert, Paolo Ciccarese, and Benjamin Young. 2016. “Web Annotation Data Model.” W3C Candidate Recommendation. W3C. https://www.w3.org/TR/annotation-model/.
Snell, J. M., M. Atkins, W. Norris, C. Messina, M. Wilkinson, and R. Dolin. 2011. “Activity Streams 1.0.” Activity Streams working group. http://activitystrea.ms/specs/json/1.0/.
Snell, James, and Evan Prodromou. 2016. “Activity Streams 2.0.” W3C Candidate Recommendation. W3C. http://www.w3.org/TR/activitystreams-core/.
Speicher, Steve, John Arwe, and Ashok Malhotra. 2015. “Linked Data Platform 1.0.” W3C Recommendation. W3C. http://www.w3.org/TR/ldp/.
Sporny, Manu, Gregg Kellogg, and Markus Lanthaler. 2014. “JSON-LD 1.0 – A JSON-Based Serialization for Linked Data.” W3C Recommendation. W3C. http://www.w3.org/TR/json-ld-syntax/.
Stegmaier, Florian, Werner Bailer, Tobias Bürger, Mari Carmen Suárez-Figueroa, Erik Mannens, Martin Höffernig, Pierre-Antoine Champin, Jean-Pierre Evain, Mario Döller, and Harald Kosch. 2013. “Unified Access to Media Metadata on the Web: TowardsInteroperability Using a Core Vocabulary.” IEEE MultiMedia 20 (2): 22–29. https://doi.org/10.1109/MMUL.2012.55.
Steiner, Thomas, Hannes Mühleisen, Ruben Verborgh, Pierre-Antoine Champin, Benoît Encelle, and Yannick Prié. 2014. “Weaving the Web(VTT) of Data.” In Linked Data on the Web (LDOW2014), edited by Tim Berners-Lee Christian Bizer Tom Heath, Sören Auer, 1–10. http://liris.cnrs.fr/publis/?id=6501.
Styles, Rob, Nadeem Shabir, and Jeni Tennison. 2009. “A Pattern for Domain Specific Editing Interfaces Using Embedded RDFa and HTML Manipulation Tools.” In . Heraklion, Crete, Greece. https://confluence.ontotext.com/download/attachments/9504111/Talis+Aspire-+Pattern+for+Domain+Specific+Editing+Interfaces+Using+Embedded+RDFa+and+HTML+Manipulation+Tools+(SFSW+2009).pdf.
Troncy, Raphaël, Erik Mannens, Silvia Pfeiffer, and Davy Van Deursen. 2012. “Media Fragments URI 1.0 (Basic).” W3C Recommendation. W3C. http://www.w3.org/TR/media-frags/.
Verborgh, Ruben. 2016. “Querying History with Linked Data.” Ruben Verborgh’s Blog (blog). June 22, 2016. http://ruben.verborgh.org/blog/2016/06/22/querying-history-with-linked-data/.
Verborgh, Ruben, Miel Vander Sande, Olaf Hartig, Joachim Van Herwegen, Laurens De Vocht, Ben De Meester, Gerald Haesendonck, and Pieter Colpaert. 2016. “Triple Pattern Fragments: A Low-Cost Knowledge Graph Interface for the Web.” Journal of Web Semantics 37–38 (March): 184–206. https://doi.org/doi:10.1016/j.websem.2016.03.003.