Allocation de mémoire aux processus¶
Problématique¶
Protection / partage¶
On souhaite que deux processus indépendants ne puissent pas, par accident, utiliser la même zone mémoire (Arbitrage, Autorisation),
- mais on souhaite autoriser le partage à la demande (cf. chapitre 4).
- On ne souhaite pas que cela soit de la responsabilité du programmeur ou du compilateur (Aide, Arbitrage).
Translation (relocation)¶
Le même programme doit pouvoir s’exécuter à différent endroits de la mémoire.
- sans être ré-écrit ni re-compilé (Abstraction).
- NB : l’emplacement mémoire peut même varier au cours de l’exécution (swap).
Allocation / réallocation¶
Un programme doit pouvoir recevoir la zone mémoire dont il a besoin si la mémoire est disponible, et modifier ses besoins pendant sont exécution.
- problème de fragmentation: lorsque la mémoire disponible est inutilisable car non contiguë

Augmentation¶
L’utilisation « optimale » du système peut requérir plus de processus qu’il n’en tient à un instant donné dans la mémoire
- Idée : étendre la mémoire vive en utilisant une mémoire de stockage, plus volumineuse, mais plus lente.
- Problème : transférer toute la zone mémoire utilisée par un processus peut être coûteux.
Solution générale¶
Principe¶
On va distinguer deux « vues »
- adresses logiques vues par le programme / le compilateur
- adresse physique vues par le système et le matériel
La traduction peut, en théorie, être implémentée soit
- au niveau logiciel: compliqué et coûteux en temps
- au niveau matériel
Solution matérielle¶
En mode utilisateur, les instructions manipulent des adresses logiques.
C’est un composant matériel, le MMU (Memory Management Unit), qui assure la traduction en adresses physiques.
→ peu coûteux
→ transparent pour les programmes
En mode superviseur, les instructions manipulent directement les adresses physiques.
→ le système d’exploitation a une vue « globale » de la mémoire
Remarque¶
int i;
int main (int argc, char** argv) {
i = argc;
printf("adresse: %p - valeur: %d\n", &i, i);
return 0;
}
Ce programme affiche-t-il une adresse physique ou une adresse logique ?
Que se passe-t-il si on l’exécute ainsi :
./prog a & ./prog a b
Pagination¶
Principe¶
- Principe: on divise la mémoire physique en blocs ou cadres (frames) de taille fixe.
- La zone mémoire (adresses logiques) de chaque processus est divisée en pages de la même taille que les blocs.
- Le processeur possède un registre dédié contenant l’adresse (physique) d’une table de correspondance.
Illustration¶
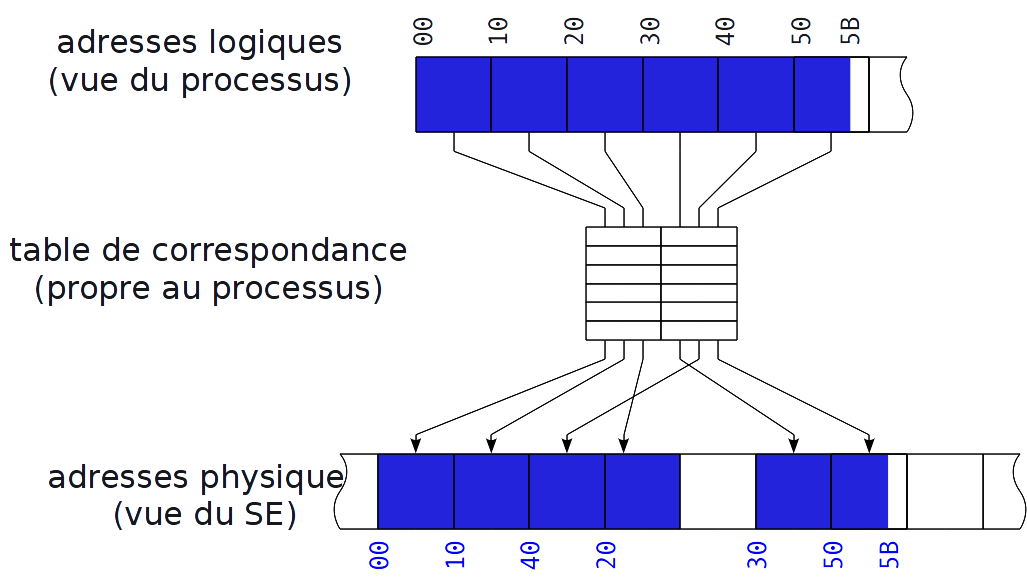
Pagination et SE¶
- C’est le SE qui construit et fait évoluer la table de correspondance de chaque processus.
- Ainsi, il reste maître de l’organisation de la mémoire physique.
- Les processus ne « voient » que ce que le SE leur laisse voir à travers leur table de correspondance.
Pagination et SE (2)¶
Translation :
- les adresses logiques manipulées par le programme sont toujours les mêmes (fixées à la compilation);
- les adresses physiques correspondantes dépendent de la table de correspondance associée au processus
Protection :
- par défaut, chaque bloc est alloué à un seul processus (c’est un choix du SE, pas une contrainte matérielle)
Pagination et SE (3)¶
Allocation – ré-allocation :
- la fragmentation est assumée, et transparente pour les processus,
- les blocs alloués à un processus n’ont plus besoin d’être physiquement contigus,
- des pages peuvent être ajoutées après coup à la zone de mémoire logique.
Partage :
- le SE peut allouer les mêmes blocs à plusieurs processus s’ils le demandent.
Mémoire partagée : illustration¶

Pagination et SE (4)¶
Augmentation de la mémoire physique :
- La table de correspondance peut faire correspondre des blocs de l’espace d’échange (swap) plutôt que des blocs de la RAM.
- Il n’est pas nécessaire de passer la totalité de la mémoire d’un processus sur le disque.
NB: C’est pour répondre spécifiquement à cette fonction que la pagination a été inventée
Rappel: calcul d’adresses¶
| al: | adresse logique |
|---|---|
| ap: | adresse physique |
| tp: | taille d’une page |
| tc[]: | table de correspondance (numéro de page → numéro de cadre) |
- calcul:
no_page = al div tp
décalage = al mod tp // en anglais: offset
ap = tc[ no_page ]*tp + décalage
Rappel: calcul d’adresses (2)¶
ap = tc[ al div tp ]*tp + ( al mod tp )
supposons tp = 10 et tc =
|00|01|02|03|04|05|06|07|08|09|10|11|12|13|14|15|
|21|22|23|24|02|03|04|36|34|35|43|44|45|46|10|xx|
traduisons d’adresse logique 123 :
Rappel: calcul d’adresses (3)¶
ap = tc[ al div tp ]*tp + ( al mod tp )
supposons tp = 10 et tc =
|00|01|02|03|04|05|06|07|08|09|10|11|12|13|14|15|
|21|22|23|24|02|03|04|36|34|35|43|44|45|46|10|xx|
traduisons d’adresse logique 123 :
- on est dans la page 12 (120→129)
- on est au décalage 3 dans cette page
- supposons que tc[12] = 45 (450→459)
- ap = 45*10 + 3 = 453
Rappel : calcul d’adresses (4)¶
La taille des pages est une puissance de 2
→ les opérations div et mod se ramènent à « couper » en deux l’adresse
On peut donc séparer le codage d’une adresse en deux parties :
numéro de page/bloc et décalage (offset)
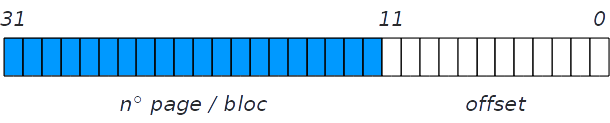
Exemple de bus d’adresse sur 32 bits
Table des pages¶
Présentation¶
La table des pages est un tableau : le numéro du bloc correspondant à la page n est à la n-ième case du tableau.
Chaque case, ou PTE (Page Table Entry) ne contient donc pas explicitement le numéro de page ; uniquement le numéro de bloc plus des information de gestion.
Structure d’une PTE¶
Drapeaux (flags) renseignés par le SE / utilisés par le MMU
- R,W,X : indiquent si la page est accessible en lecture / écriture / exécution
- p (present) : indique si la page est présente en RAM ou sur l’espace d’échange (swap)
Drapeaux renseignés par le MMU / utilisés (et parfois modifiés) par le SE
- a (accessed) : indique si la page a été lue
- d (dirty) : indique si la page été modifiée

Drapeaux d’une PTE¶
- NB: Tous ces drapeaux sont respectivement pris en compte / mis à jour automatiquement par le MMU
- Les blocs accessibles en lecture seule peuvent être partagés sans risque entre différents processus
- utilisé notamment pour les pages en lecture+exécution, lorsque des processus exécutent le même programme
- utilisé par Linux lors d’un fork (cf. ci-après)
Drapeaux d’une PTE (2)¶
- Le bit dirty permet de savoir s’il est nécessaire de mettre à jour l’espace d’échange (swap).
- Certains bits ne sont pas utilisés par le matériel ; ils peuvent être utilisés par le système d’exploitation pour ses besoins propres
- Lorsque le bit present est à 0, le champ numéro de bloc peut notamment être utilisé par le système pour stocker l’adresse de la page dans l’espace d’échange
Application : optimisation de fork¶
Problème avec le code suivant :
int pid = fork();
if (pid == 0) exec("monprog", argv);
- la première ligne duplique toutes les pages mémoire du processus père pour le processus fils…
- … mais la deuxième ligne les « oublie » immédiatement pour démarrer l’exécution d’un autre programme.
COW: Copy On Write¶
- au moment du fork, le flag w (écriture) de toutes les pages du père est mis à 0 ;
- la table de page du fils est identique à celle du père ;
- à chaque tentative de modifier une page (par le père ou le fils), la page concernée est copiée (COW), et les deux tables des pages sont mises à jours (avec le flag w à 1).
NB: ce type de méthode est appelé « méthode paresseuse » (lazy)
Mémoire virtuelle¶
Introduction : principe de localité¶
- Selon le principe de localité, un programme informatique n’utilise pas ses ressources de manière aléatoire. Au contraire, les utilisations d’une même ressource sont regroupées dans le temps.
- On en déduit l”heuristique suivante : une ressource utilisée récemment à plus de chances qu’une autre d’être utilisé dans un futur proche.
- C’est ce principe qui justifie la technique du cache : stocker une partie d’une mémoire lente dans une mémoire rapide (mais plus petite).
Hiérarchie des mémoire¶

Principe de la mémoire virtuelle¶
Le principe de mémoire virtuelle est une application de la technique du cache.
- On stocke les pages dans un espace d’échange (en anglais swap), situé dans la mémoire de stockage.
- La mémoire vive est considérée comme un cache de l’espace d’échange,
elle contient les pages en cours d’utilisation
- ainsi que les fichiers alignés par
mmap.
- ainsi que les fichiers alignés par

Remplacement des pages¶
Problématique : comment décider des pages à retirer de la mémoire et de celles à recharger ?
Idéalement (principe de localité) :
- restaurer une page juste avant son utilisation,
- retirer la page qui dont la prochaine utilisation est la plus lointaine,
- nécessite de connaître l’avenir…
NB : ce problème ne le limite pas à la gestion de mémoire paginée, mais à tout type de cache (y compris au niveau applicatif).
Stratégies¶
En ce qui concerne la restauration, on fonctionne à la demande : une page est restaurée en mémoire au moment où on a besoin d’elle :
- solution pas idéale, car elle pénalise le premier accès (temps de chargement),
- mais évite au moins de se tromper (charger la mauvause page).
Reste le problème du retrait : quelle page va céder sa place à la page restaurée ?
Mise en œuvre¶
- Le processus tente d’accéder à une page absente de la mémoire (flag present de la PTE à 0).
- Le MMU émet une requête d’interruption (erreur).
- Le SE choisit une page à remplacer.
- Si cette page est marquée dirty, la page est « nettoyée » (écrite sur le disque).
- La page requise est chargée en mémoire à la place de la page remplacée.
- Le processus est relancé à l’instruction qui a causé l’erreur (NB : peut déclencher une autre erreur).
Stratégie de remplacement optimale¶
Toujours retirer la page qui sera ré-utilisée le plus tard.
Nécessite soit :
- d’avoir une connaissance a priori du comportement du programme
- d’avoir un bon outil statistique (pseudo-optimal)
Utile pour évaluer les autres approches a posteriori.
Stratégie : Not Recently Used¶
- On utilise le bit accessed pour savoir si une page a été utilisée
- Une tâche du système d’exploitation remet régulièrement le bit accessed à zéro
- On remplace en priorité les pages dont le bit accessed est à zéro car elles n’ont pas été utilisées récemment (i.e. depuis la dernière mise à zéro)
Stratégie : Not Recently Used (2)¶
En fait, on utilise également le bit dirty pour déterminer les pages utilisées récemment, en donnant le poids fort à accessed
- a=1, d=1 : utilisée récemment, modifiée
- a=1, d=0 : utilisée récemment, non modifiée
- a=0, d=1 : pas utilisée récemment, modifiée
- a=0, d=0 : pas utilisée récemment, non modifiée
Méthode relativement efficace (surcoût très faible), mais ayant un grain très grossier (4 catégories seulement).
Stratégies : FIFO¶
- La page retirée est la plus ancienne.
- Simple à implémenter.
- Défaut principal : ne tient pas compte du fait que la page la plus ancienne en mémoire peut aussi être la plus utilisée (et donc la plus susceptible d’être réutilisée à l’avenir).
- Autre défaut : anomalie de Belady (cf. transparents suivants)
Stratégie FIFO : Anomalie de Belady¶
- Intuition : plus la mémoire disponible est grande, moins il est nécessaire de remplacer des pages
- Belady a démontré en 1970 que l’algorithme de remplacement FIFO ne vérifie pas cette règle
Anomalie de Belady (exemple)¶
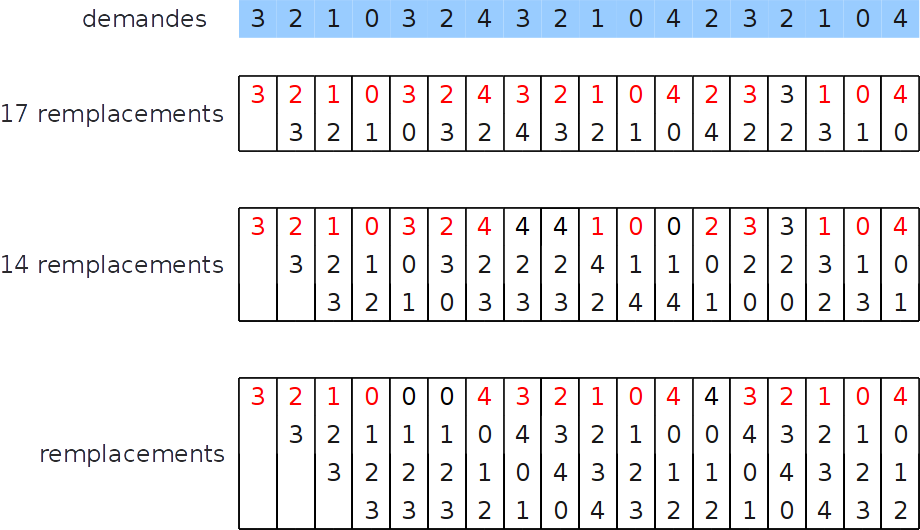
Stratégie : Seconde chance¶
- Comme FIFO, mais si la page à remplacer est marquée comme utilisée (bit accessed à 1), on la replace en queue de la file après avoir remis le bit accessed à 0.
- Plus fidèle au principe de localité, et surcoût encore faible.
- NB : peut parcourir toute la liste une fois si toutes les pages ont été utilisées.
Stratégie : Least Recently Used¶
- C’est toujours la page la plus anciennement utilisée qui est retirée de la mémoire.
- Application fidèle du principe de localité.
- Ne souffre pas de l’anomalie de Belady.
- Mais très coûteux à mettre en œuvre (mise à jour de l’ordre).
Stratégie : Not Frequently Used¶
- Le système d’exploitation conserve, dans la PTE, un compteur indiquant la « fréquence » d’utilisation de la page.
- Une tâche du système passe régulièrement en revue la table des pages, incrémente ce compteur si la page a été lue ou modifiée, puis remet le bit accessed à 0.
Stratégie : Not Frequently Used (2)¶
- Le système d’exploitation conserve, dans la PTE, un compteur indiquant la « fréquence » d’utilisation de la page.
- Une tâche du système passe régulièrement en revue la table des pages, incrémente ce compteur si la page a été lue ou modifiée, puis remet le bit accessed à 0.
- On remplace en priorité une page dont le compteur d’accès est faible (peu utilisée).
- Problème : cette méthode avantage les pages présentes depuis longtemps en mémoire, même si celles-ci n’ont pas été utilisées depuis longtemps.
Stratégie : NFU + vieillissement¶
- Le compteur d’accès à une page diminue avec le temps
- En pratique :
- pour diminuer, on décale les chiffres vers la droite (division par deux)
- pour augmenter, on met le bit de poids fort à 1
Stratégie : NFU + vieillissement (2)¶
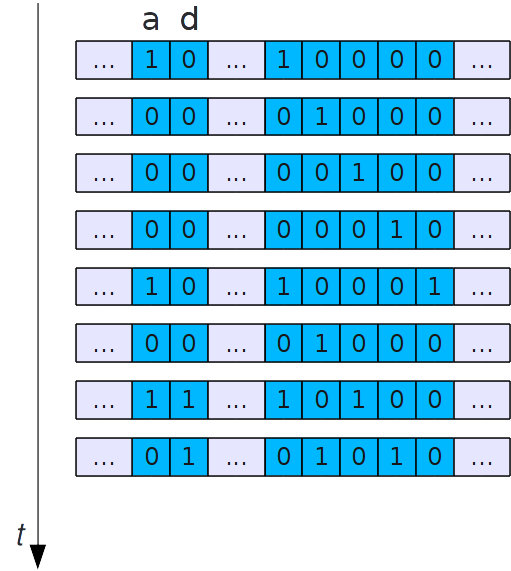
Remarques sur les stratégies¶
Remplacement local ou global¶
- Peut on remplacer une page d’un processus par une page d’un autre processus ?
- Remplacement global :
- plus souple
- Remplacement local :
- passe mieux à l’échelle (pas de structure globale)
- nécessite de bien choisir le nombre de bloc (en mémoire physique) alloué à chaque processus
Pré-nettoyage (pre-cleaning)¶
- Si la page a remplacer est marquée comme modifiée (dirty), il faut l’écrire sur le disque avant de la remplacer (cleaning).
- Pour minimiser le coût de ce « nettoyage » au moment du remplacement, une tâche du système peut rechercher les pages susceptibles d’être remplacées pour les nettoyer pendant une période d’inactivité.
- Risque de nettoyer une page pour rien, juste avant qu’elle soit à nouveau modifiée.
Évolutions¶
- La localité des programmes change :
- Programmation orientée objets (fonctions plus petites)
- Ramasse-miettes (garbage collector)
- La hiérarchie des mémoire change de structure :
- rapport de taille entre RAM et stockage
- rapport de vitesse entre RAM et stockage (SSD)
- Unification de la mémoire virtuelle et du cache des fichiers (
mmap).