L'exemple provient du livre de Richard Bird : Thinking Functionally with Haskell.
> import System.Environment (getArgs) > import Control.Monad.ParOn définit une grille comme étant une matrice de caractères.
> type Matrix a = [Row a] > type Row a = [a] > type Grid = Matrix Digit > type Digit = Char > > digits :: [Char] > digits = ['1' .. '9'] > > blank :: Digit -> Bool > blank = (== '0')
Comme pour la résolution du Countdown, on commence par développer une spécification exécutable sous forme d'une solution combinatoirement coûteuse.
Dans un second temps, on essaie de transformer cette spécification en un programme efficace.
Ainsi, à partir d'une grille incomplète initiale, il s'agit de générer toutes les grilles possibles puis de filtrer les grilles qui sont solution.
> solve :: Grid -> [Grid] > solve = filter valid . completions > > completions :: Grid -> [Grid] > valid :: Grid -> Bool
Pour
completions, on propose
d'utiliser une stratégie assez classique :- D'abord remplacer le contenu de chaque case inconnue par l'ensemble des valeurs que la case pourrait prendre (résister pour le moment à tout effort d'optimisation...)
- Puis exploser cette matrice de choix en un choix de matrices
> completions = expand . choices > > choices :: Grid -> Matrix [Digit] > expand :: Matrix [Digit] -> [Grid]
Une version naïve de la fonction
choices
est simple à proposer :
> choices = map (map choice) > choice d = if blank d then digits else [d]
La fonction expand est un cas particulier du produit cartésien généralisé sur les listes :
cp [[1,2,3],[2],[1,3]] === [[1,2,1],[1,2,3],[2,2,1],[2,2,3], [3,2,1],[3,2,3]] cp [[2],[1,3]] === [[2,1],[2,3]]
> cp :: [[a]] -> [[a]] > cp [] = [[]] > cp (xs:xss) = [x:ys|x<-xs, ys<-yss] > where yss = cp xssPourquoi
cp [] = [] ne serait pas
correct ?
Comme définir
expand en fonction
de cp ?
> expand = cp . map cp
Une matrice est valide si
- aucune ligne ne contient de doublons
- aucune colonne ne contient de doublons
- aucune boîte 3x3 ne contient de doublons
> --valid :: Grid -> Bool > valid g = all nodups (rows g) && > all nodups (cols g) && > all nodups (boxs g) > > nodups :: (Eq a) => [a] -> Bool > nodups [] = True > nodups (x:xs) = all (/=x) xs && nodups xsQuelle est la complexité de nodups ?
Comment pourrait-on réduire cette complexité ?
Est-ce intéressant de le faire ?
Définir les fonctions
rows et
cols.
Essayer de définir
cols sans
utiliser la fonction transpose
(i.e. re-définir transpose est un
bon exercice).
> rows :: Matrix a -> Matrix a > rows = id > > cols :: Matrix a -> Matrix a > cols [xs] = [[x] | x<-xs] > cols (xs:xss) = zipWith (:) xs (cols xss)
Pour la définition de
boxs, vous
pouvez commencer par définir group n
qui découpe une liste en listes de taille n, et son inverse
ungroup.
> group :: Int -> [a] -> [[a]] > group _ [] = [] > group n xs = take n xs : group n (drop n xs) > > group3 = group 3 > > ungroup :: [[a]] -> [a] > ungroup = concat
Définir
boxs en fonction de group.
/ \
/ \ |/ \|
|a b c d| group . map group ||ab cd||
|e f g h|------------------->||ef gh||
|i j k l| |\ /|
|m n o p| |/ \|
\ / ||ij kl||
||mn op||
|\ /|
\ /
| map cols
v
/ \
/ \ map ungroup . |/ \|
|a b e f| ungroup ||ab ef||
|c d g h|<-------------------||cd gh||
|i j m n| |\ /|
|k l o p| |/ \|
\ / ||ij mn||
||kl op||
|\ /|
\ /
> boxs :: Matrix a -> Matrix a > boxs = map ungroup . ungroup . > map cols . > group3 . map group3
En utilisant, entre autres, les deux lois fonctorielles (LFONC) :
map id = id map f . map g = map (f . g)montrer que :
boxs . boxs = idOn a de même :
rows . rows = id cols . cols = idSolution :
boxs . boxs
= {par définition de boxs}
map ungroup . ungroup . map cols . group . map group .
map ungroup . ungroup . map cols . group . map group
= { map group . map ungroup = id
car group . ungroup = id et par application de
la première loi fonctorielle }
map ungroup . ungroup . map cols . group .
ungroup . map cols . group . map group
= { group . ungroup = id }
map ungroup . ungroup . map cols .
map cols . group . map group
= { map cols . map cols = map (cols . cols) =
map id = id }
map ungroup . ungroup .
group . map group
= { ungroup . group = id }
map ungroup .
map group
= { ungroup . group = id et seconde loi fonctorielle }
id
On se donne également les lois (LNAT) :
map rows . expand = expand . rows map cols . expand = expand . cols map boxs . expand = expand . boxs map (map f) . cp = cp . map (map f)Ces lois appartiennent à la classe des lois dites de "naturalité". C'est-à-dire par exemple que
cp est une fonction "naturelle" qui
s'applique à un conteneur de type
[[a]] et ne modifie ni la forme
du conteneur ni les données contenues, mais réordonne, duplique, etc.
(c'est pourquoi son type est polymorphique).
On pourra aussi utiliser (LFILCP) :
filter (all p) . cp = cp . map (filter p)Que signifie cette dernière loi ?
La première proposition d'optimisation consiste pour chaque boîte, ligne ou colonne d'une matrice de choix à supprimer les choix qui apparaissent aussi comme singletons :
> prune :: Matrix [Digit] -> Matrix [Digit]Tel que :
filter valid . expand = filter valid . expand . pruneIl s'agit maintenant de définir
prune. Comment feriez-vous ?
Nous allons essayer de calculer cette fonction !
Assez clairement,
prune travaille
ligne par ligne (ou colonne par colonne, ou boîte par boîte) :
> pruneRow :: Row [Digit] -> Row [Digit]Définir
pruneRow.
> pruneRow r = map (remove singles) r > where singles = [d | [d] <- r] > > remove :: [Digit] -> [Digit] -> [Digit] > remove ds [x] = [x] > remove ds xs = filter (`notElem` ds) xs
pruneRow respecte la propriété
suivante :
filter nodups . cp = filter nodups . cp . pruneRow (LPRUNE)
Nous utiliserons également la propriété suivante valable pour toute fonction involutive (i.e.
f . f = id) :
filter (p . f) = map f . filter p . map f (LFILINV)Prouvons le :
map f . filter p . map f
= {filter p . map f = map f . filter (p . f)}
map f . map f . filter (p . f)
= {LFONC et involutivité de f}
filter (p . f)
Prouvons la loi utilisée dans le premier indice de la preuve
précédente. Nous avons besoin d'une définition de filter :
> -- filter p = concat . map (test p) > -- test p x = if p x then [x] else []
filter p . map f
= {déf. filter}
concat . map (test p) . map f
= {LFONC}
concat . map (test p . f)
= {test p . f = map f . test (p . f)}
concat . map (map f . test (p . f))
= {LFONC}
concat . map (map f) . map (test (p . f))
= {naturalité de concat}
map f . concat . map (test (p . f))
= {déf. filter}
map f . filter (p . f)
On a aussi facilement (par involutivité de f et LFONC) :
filter (p . f) . map f = map f . filter p
Rappelons que la stratégie de résolution (voir la fonction
solve) est basée sur l'expression
filter valid . expand que l'on
réécrit comme ci-dessous en utilisant la définition de
valid :
filter valid . expand = filter (all nodups . boxs) . filter (all nodups . cols) . filter (all nodups . rows) . expandL'idée est de faire apparaître l'expression
filter nodups . cp afin de pouvoir
utiliser la propriété (LPRUNE) de
pruneRow.
Le problème est clairement symétrique pour
boxs,
cols et
rows. La propriété commune utile de
ces fonctions étant leur involutivité. On peut donc se concentrer
par exemple sur le cas de rows.
On utilisera les lois LFILINV, LNAT, LFILCP, LFONC et LPRUNE.
filter (all nodups . rows) . expand
= {LFILINV}
map rows . filter (all nodups) . map rows . expand
= {LNAT}
map rows . filter (all nodups) . expand . rows
= {Déf. expand}
map rows . filter (all nodups) . cp . map cp . rows
= {LFILCP}
map rows . cp . map (filter nodups) . map cp . rows
= {LFONC}
map rows . cp . map (filter nodups . cp) . rows
= {LPRUNE}
map rows . cp . map (filter nodups . cp . pruneRow) . rows
Maintenant que nous sommes parvenus à introduire
pruneRow, il suffit de parcourir le
chemin inverse pour retrouver une forme qui utilise
expand (peu d'intelligence ici...) :
map rows . cp . map (filter nodups . cp . pruneRow) . rows
= {LFONC}
map rows . cp . map (filter nodups) .
map (cp . pruneRow) . rows
= {LFILCP}
map rows . filter (all nodups) . cp .
map (cp . pruneRow) . rows
= {LFONC}
map rows . filter (all nodups) .
cp . map cp . map pruneRow . rows
= {Déf. expand}
map rows . filter (all nodups) .
expand . map pruneRow . rows
= {LFILINV}
filter (all nodups . rows) . map rows .
expand . map pruneRow . rows
= {LNAT}
filter (all nodups . rows) . expand .
rows . map pruneRow . rows
= {introduction de pruneBy}
filter (all nodups . rows) . expand . pruneBy rows
Avec pruneBy définit par :
> pruneBy f = f . map pruneRow . f > > prune = pruneBy rows . pruneBy cols . pruneBy boxsEn utilisant la propriété (vraie lorsque les prédicats sont des fonctions totales) :
filter p . filter q = filter q . filter pOn prouve la propriété recherchée :
filter valid . expand = filter valid . expand . prune
On peut maintenant écrire une nouvelle version plus optimisée du solveur :
> solve' = filter valid . expand . prune . choices
On peut encore améliorer le solveur en répétant l'application de
prune tant que le problème continue
à se simplifier. Pour cela, écrire la fonction :many :: (Eq a) => (a -> a) -> a -> a
> solve'' = filter valid . expand . many prune . choices > > many :: (Eq a) => (a -> a) -> a -> a > many f x = if x == y then x else many f y > where y = f x
Après l'application de
many prune . choices :
- soit la matrice de choix de contient que des singletons et le problème est résolu ;
- soit la matrice de choix contient une liste vide, et il n'y a alors pas de
solutions (quel sera alors le résultat de l'application de
expand?) ;- soit la matrice ne contient pas de liste vide, et contient également au moins une entrée composée de deux choix ou plus.
> expand1 :: Matrix [Digit] -> [Matrix [Digit]]
expand1 doit respecter la propriété
suivante :
expand = concat . map expand . expand1
Nous avons besoin d'une fonction pour déterminer si une liste est un singleton :
> single :: [a] -> Bool > single [_] = True > single _ = False
Quelle cellule pivot choisir lors de l'application de
expand1 ? Il faut une cellule qui
ait plus d'un choix. Il semble pertinent de choisir une cellule avec le moins
de choix possible.
> counts :: Matrix [Digit] -> [Int] > counts = filter (/= 1) . map length . concat > > -- minimum :: Ord a => [a] -> a > -- minimum [x] = x > -- minimum (x:xs) = x `min` minimum xs > > -- expand1 :: Matrix [Digit] -> [Matrix [Digit]] > expand1 rows = > [rows1 ++ [row1 ++ [c]:row2] ++ rows2 | c <- cs] > where > (rows1,row:rows2) = break (any smallest) rows > (row1,cs:row2) = break smallest row > smallest cs = length cs == n > n = minimum (counts rows)
- (Q1) Que retourne
expand1lorsque la matrice de choix contient un choix vide ?- (Q2) Que retourne
expand1lorsque la matrice de choix ne contient que des singletons ? - (Q2) Que retourne
- (R1) Une liste vide.
- (R2) Une erreur (car
minimum []retourne une erreur).
Il faut donc pouvoir tester si une matrice de choix ne contient que des singletons (on dira qu'elle est complète) :
> complete :: Matrix [Digit] -> Bool > complete = all (all single)
Par ailleurs, on dira qu'une matrice de choix est sûre si le choix de matrices qu'elle implique peut contenir une matrice valide :
> safe :: Matrix [Digit] -> Bool > safe m = all ok (rows m) && > all ok (cols m) && > all ok (boxs m) > > ok row = nodups [x | [x] <- row]Ainsi, une matrice de choix complète et sûre correspond à un choix d'exactement une matrice qui est solution du problème :
> extract :: Matrix [Digit] -> Grid > extract = map (map head)Pour une matrice complète et sûre, on a la propriété :
filter valid (expand m) = [extract m]Pour une matrice incomplète et sûre, on a la propriété :
filter valid . expand
= {Propriété de expand1}
filter valid . concat . map expand . expand1
= {filter p . concat = concat . map (filter p)}
concat . map (filter valid) . map expand . expand1
= {LFONC}
concat . map (filter valid . expand) . expand1
= {loi prouvée plus haut}
concat . map (filter valid . expand . prune) . expand1
Ainsi, pour une matrice incomplète et sûre, en posant
search = filter valid . expand . prune,
on obtient :
search = concat . map search . expand1Ce qui nous permet de proposer une nouvelle version du solveur :
> solve''' = search . choices > > search m > | not (safe pm) = [] > | complete pm = [extract pm] > | otherwise = concat $ map search $ expand1 pm > where pm = prune m
Afin de tester notre solveur, nous allons utiliser un jeu de données de plus de 49000 grilles de sudoku chacune ayant exactement 17 indices (ce qui semble être le plus petit nombre d'indices nécessaire pour qu'une grille puisse être résolue d'une manière unique).
Voici pour exemple la première ligne du fichier 'sudoku17' (copie locale) :
000000010400000000020000000000050407008000300001090000300400200050100000000806000La fonction
s2g convertit une telle
ligne en grille :
> s2g :: String -> Grid > s2g = group 9Pourquoi le programme suivant semble-t-il résoudre les >49000 grilles de sudoku en moins de 1s (même avec
solve''') ?!
(compilé avec :
$ ghc -o sudoku -O sudoku.lhset exécuté avec :
$ ./sudoku dataset/sudoku17 +RTS -s)
> --main :: IO () > --main = do > -- [f] <- getArgs > -- gs <- fmap lines $ readFile f > -- print $ (length $ map (solve''' . s2g) gs) == (length gs)A cause de l'évaluation paresseuse (lazy evaluation) !
Ajouter par exemple un filtre forcera l'évaluation :
> --main :: IO () > --main = do > -- [f] <- getArgs > -- gs <- fmap lines $ readFile f > -- print $ (length $ filter single $ map (solve''' . s2g) $ take 20 gs) == 20
A2PF_2014/sudoku $ ./sudoku dataset/sudoku17 +RTS -s
True
37,960,268,984 bytes allocated in the heap
1,728,353,264 bytes copied during GC
293,648 bytes maximum residency (484 sample(s))
47,912 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 72477 colls, 0 par 1.89s 1.88s 0.0000s 0.0001s
Gen 1 484 colls, 0 par 0.08s 0.08s 0.0002s 0.0003s
INIT time 0.00s ( 0.00s elapsed)
MUT time 11.02s ( 11.01s elapsed)
GC time 1.96s ( 1.96s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 12.98s ( 12.97s elapsed)
%GC time 15.1% (15.1% elapsed)
Alloc rate 3,445,356,437 bytes per MUT second
Productivity 84.9% of total user, 84.9% of total elapsed
J'ai 4 coeurs sur ma machine (
cat /proc/cpuinfo | grep processor | wc -l).
Comment en profiter ? Par exemple grâce à la monade
Par !$ cabal install monad-par$ cabal install threadscopeVoir le livre du créateur de cette monade Simon Marlow : Parallel and Concurrent Programming in Haskell
data Par a instance Monad Par runPar :: Par a -> a fork :: Par () -> Par () data IVar a new :: Par (IVar a) get :: IVar a -> Par a put :: NFData a => IVar a -> a -> Par () main = do v1 <- new v2 <- new fork $ put v1 (f x) fork $ put v2 (g x) get v1 get v2 return (h v1 v2)
_____ _____
| | | |
| f x | | g x |
|_____| |_____|
\ /
\ /
v1\ /v2
___v_v___
| |
| h v1 v2 |
|_________|
> main :: IO () > main = do > [f] <- getArgs > gs <- fmap lines $ readFile f > > let nbg = 20 > let gs' = take nbg gs > let (as,bs) = splitAt (length gs' `div` 2) gs' > > print $ (==nbg) $ length $ filter single $ runPar $ do > i1 <- new > i2 <- new > fork $ put i1 (map (solve''' . s2g) as) > fork $ put i2 (map (solve''' . s2g) bs) > as' <- get i1 > bs' <- get i2 > return (as' ++ bs')Pour bénéficier du parallélisme il faut compiler le programme ainsi :
$ ghc -o sudoku -O -threaded sudoku.lhs
Et l'exécuter ainsi :
$ ./sudoku dataset/sudoku17 +RTS -s -N2
Total time 14.88s ( 7.57s elapsed)
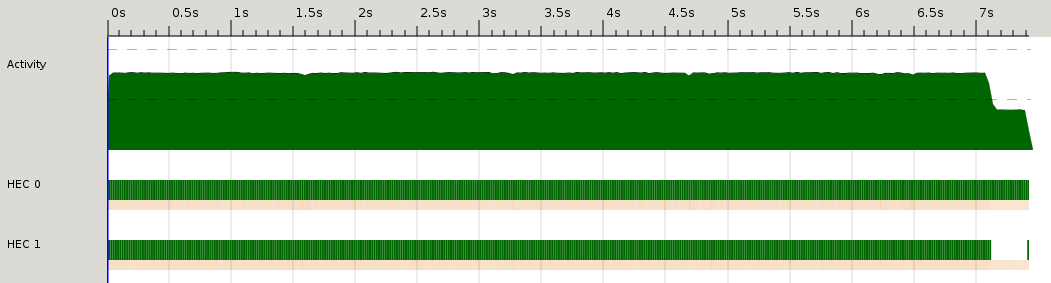
Pour mieux se rendre compte de l'occupation des processeurs nous allons utiliser
threadscope :
$ ghc -o sudoku -O -threaded -eventlog sudoku.lhs $ ./sudoku dataset/sudoku17 +RTS -N2 -l $ threadscope sudoku.eventlog