Summary
Introduction
We present additional parameters about our test topologies. It includes parallelism degrees but also CPU and memory load settings used by the Resource Aware Scheduler.
We make a distinction between the star topology and the others. Indeed, the star topology contains multiple sources and multiple sinks. In our experiments, we choose to set three sources and three sinks.
We configure operators in order to have equivalent ratio between average capacity of sinks and input stream rate no matter the topology we test.
Experimental parameters are summarized in following tables:
|
|
|
Results
Linear topology: min configuration
 |  |  |
 | 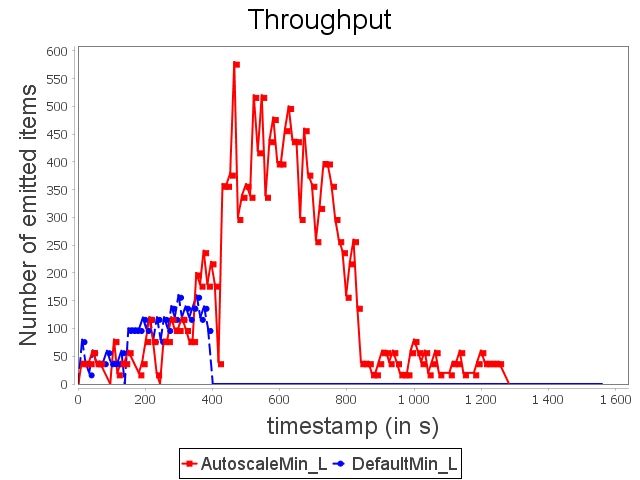 | 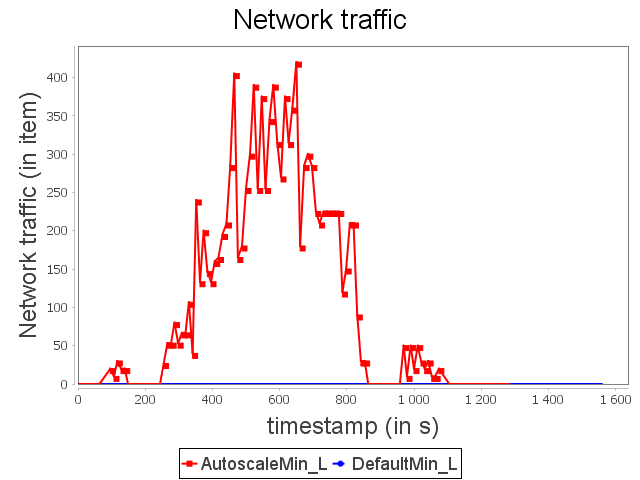 |
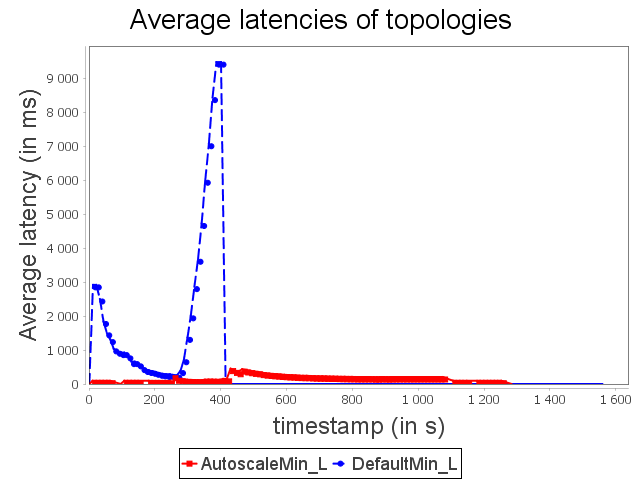
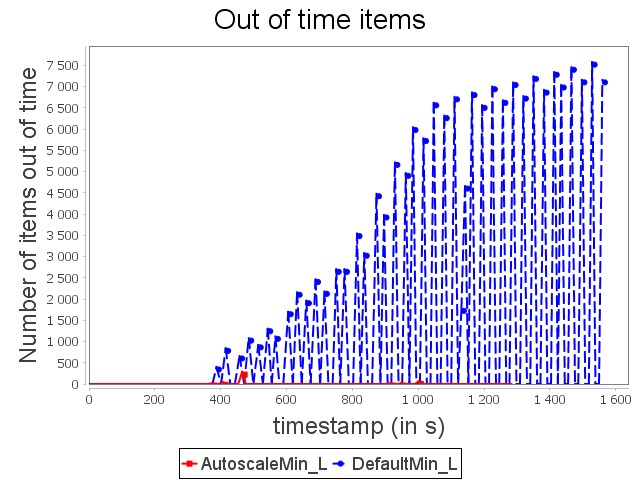
With min configuration, we observe that the incoming load cannot be handled, thus leading to the complete congestion of the topology. Indeed, the topology is not able to process items completely.
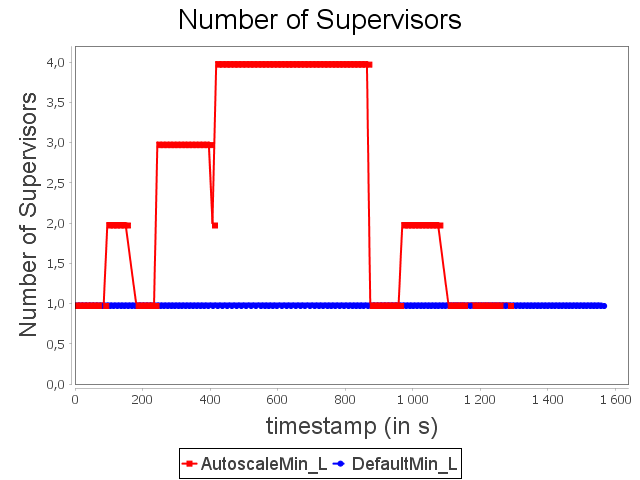
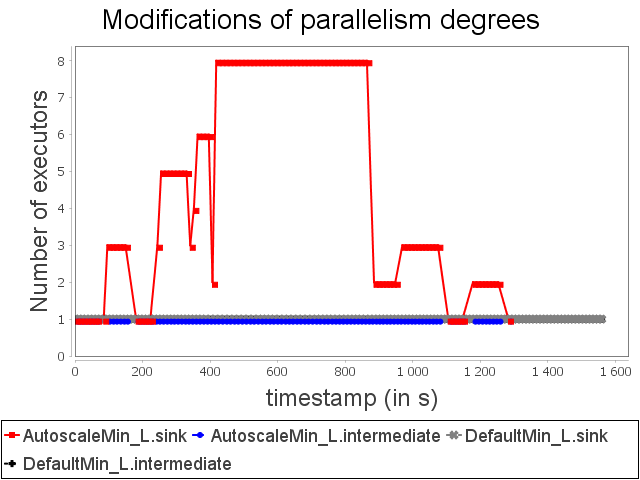
As soon as congestion occurs, new items emitted by the spout are dephased and replayed indefinitely until a user intervenes. On the contrary, our auto-parallelization strategy increases dynamically and automatically the parallelism degree of critical operators in order to adjust their capacities to future incoming loads.
When the stream rate decreases, the parallelism degree decreases accordingly. It also prevents overusing resources that are no longer necessary.
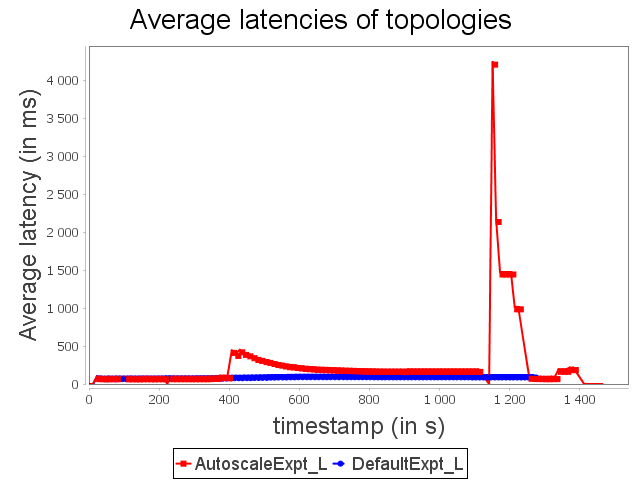
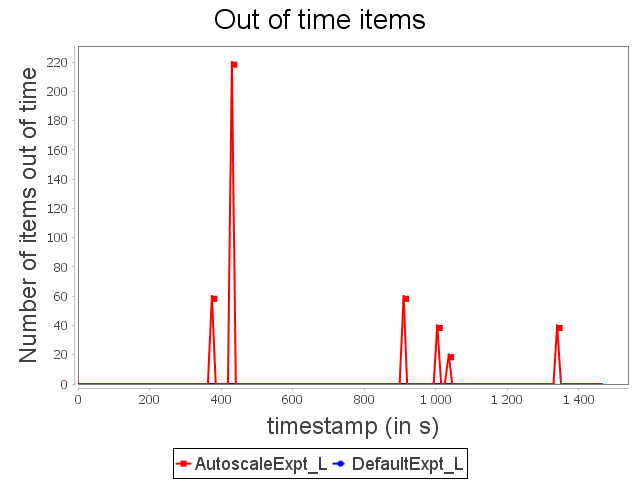
Linear topology: expt configuration
 |  | 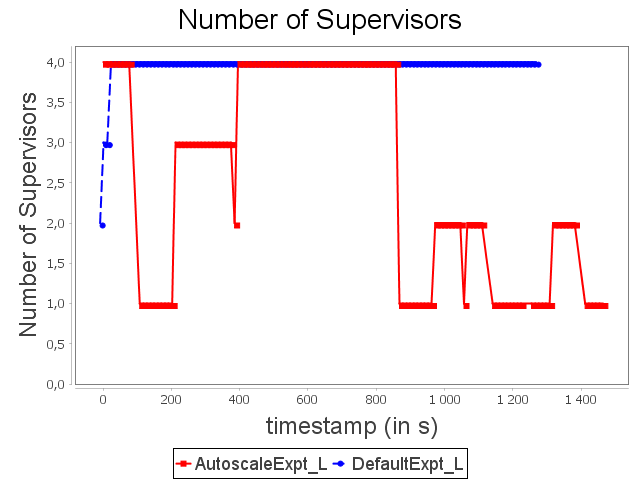 |
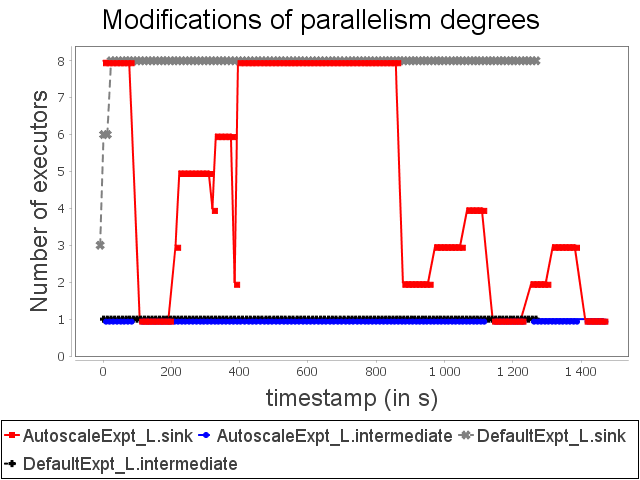 | 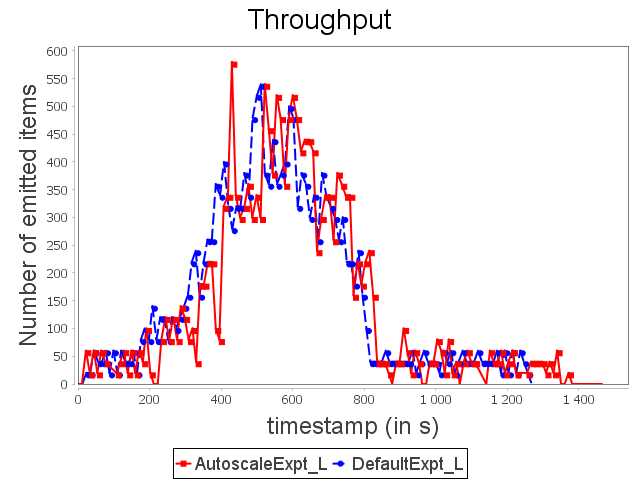 | 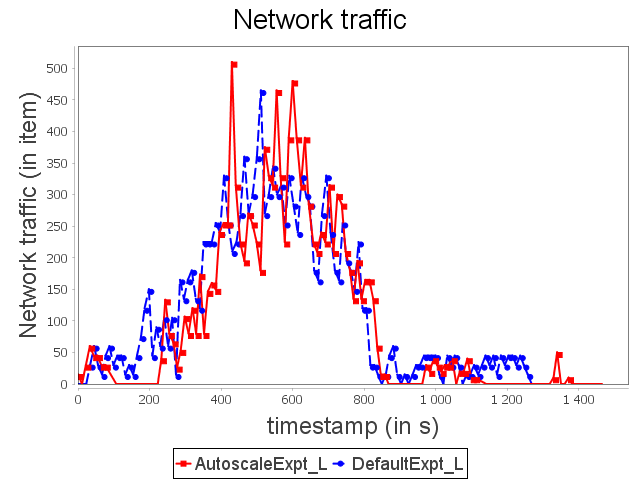 |
With expt configuration, we start with a configuration able to handle large loads. Nevertheless, this configuration overuses resources when the stream rate is low. It corresponds to the start and the end of the synthetic stream. Our auto-parallelization strategy reduces the parallelism degree when operators do not need large capacities. In this case, just as with min configuration, the parallelism degree is adapted dynamically.
AUTOSCALE then achieves equivalent performance with approximately 37.5% less CPU and memory resources. The significant increase in topology latency with AUTOSCALE is due to a scale-in from three to one supervisor, which re-routes multiple items and implies this significant overhead.
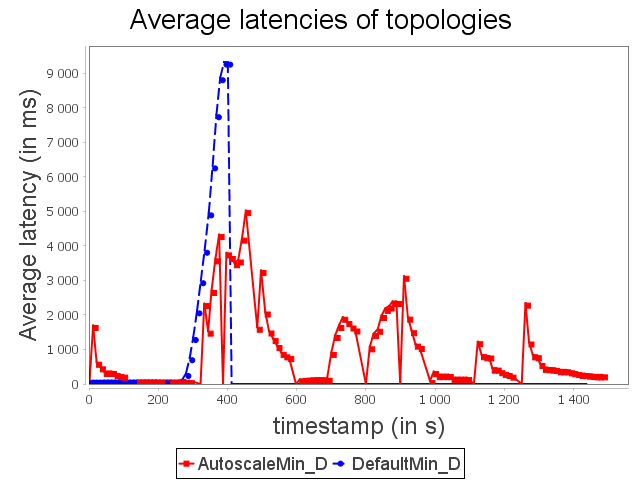
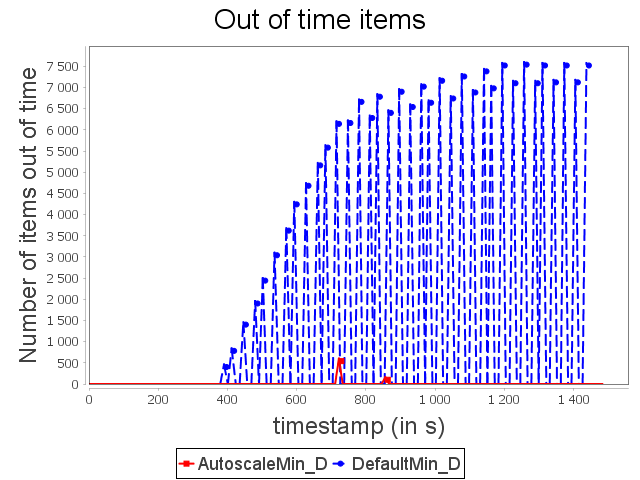
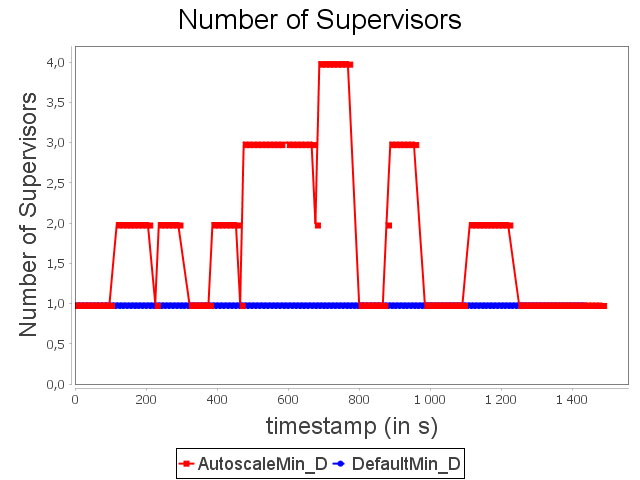
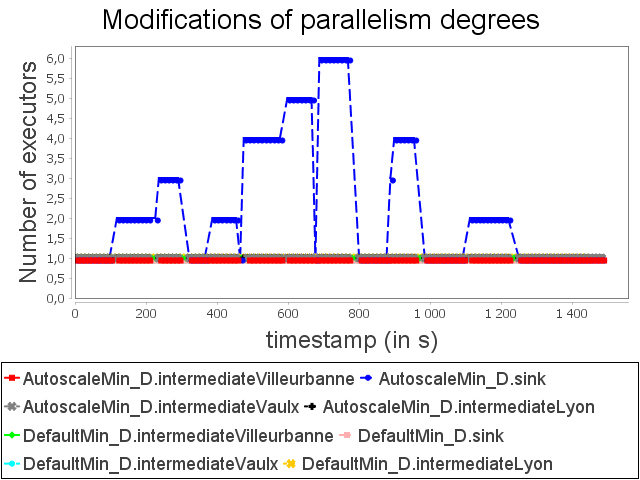
Diamond topology: min configuration
 |  |  |
 | 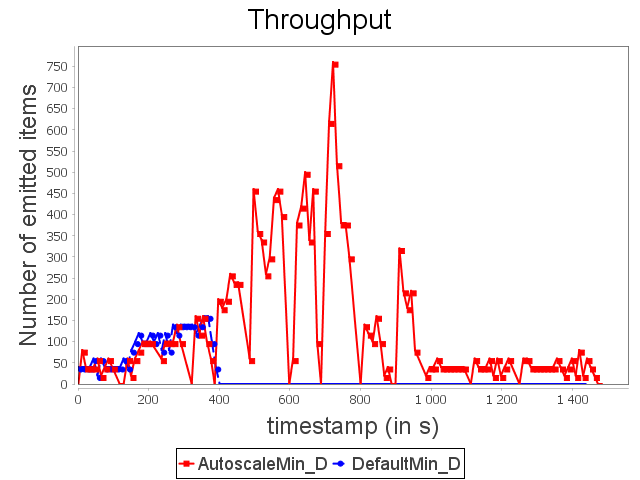 | 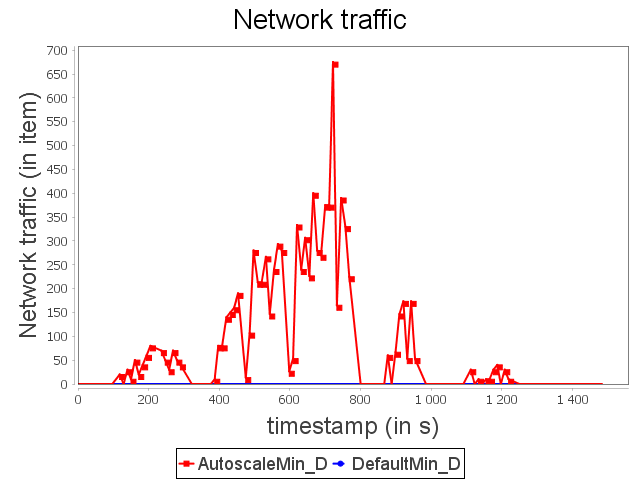 |
For the configuration ConfMin, we observe that the default scheduler of Storm is not able to avoid the congestion. As presented above, operators accumulate items on their pending without being able to respect the maximal timeout. Items are then replayed indefinitely which leads to complete congestion.
AUTOSCALE detects a congestion risk before it becomes effective and performs scale-out on sink operator in order to adapt dynamically its capacity.
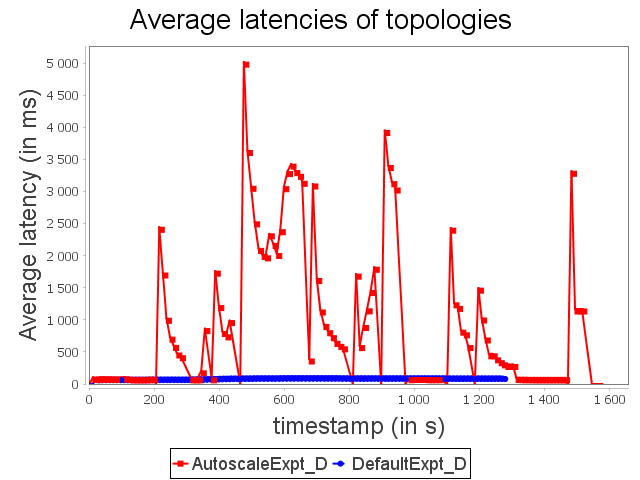
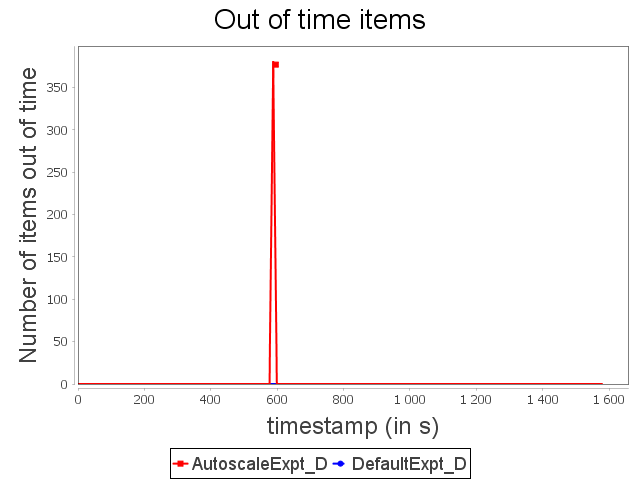
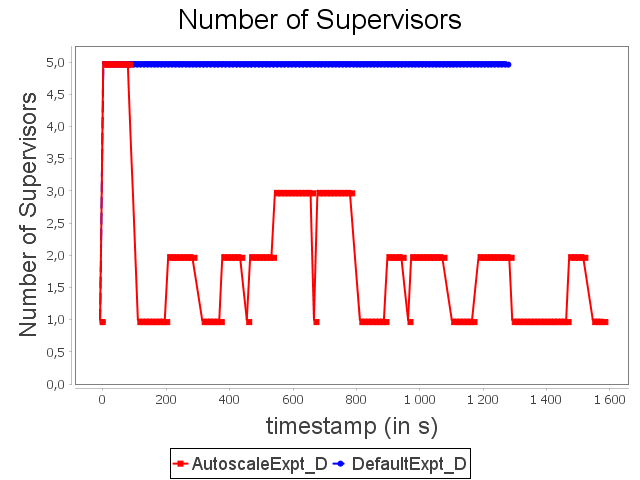
Diamond topology: expt configuration
 |  |  |
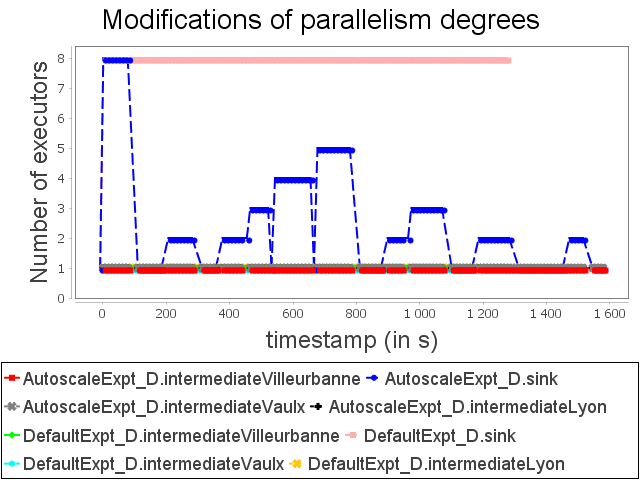 | 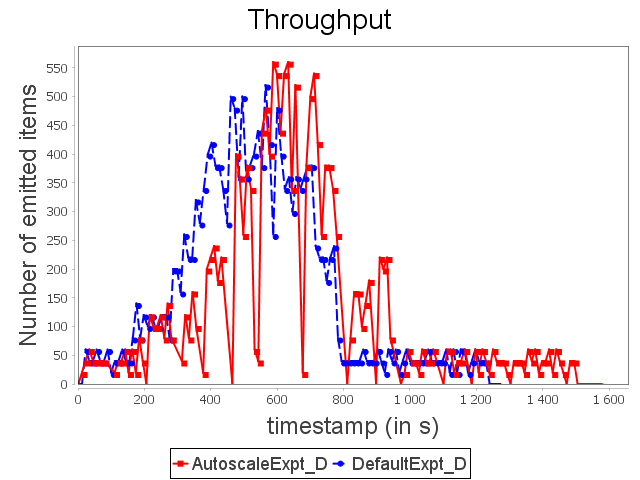 | 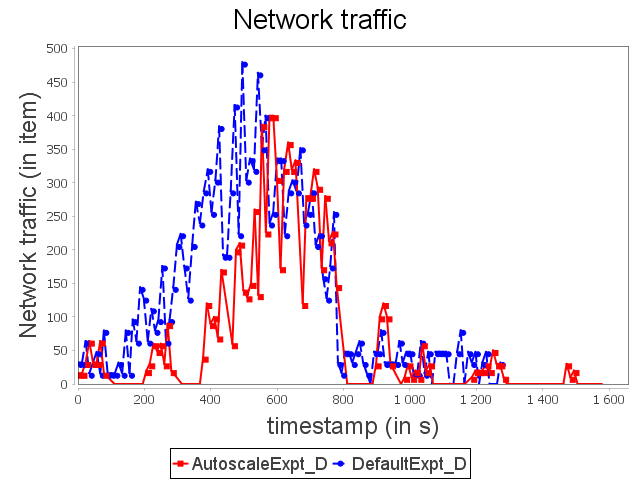 |
With ConfExpt, AUTOSCALE decreases the parallelism of the sink operator after a short time because the input rate does not require an important parallelism degree.
Then, AUTOSCALE adapts dynamically the parallelism of the sink operator like it did with ConfMin. It allows then to uses around 35% less resources than the default scheduler.
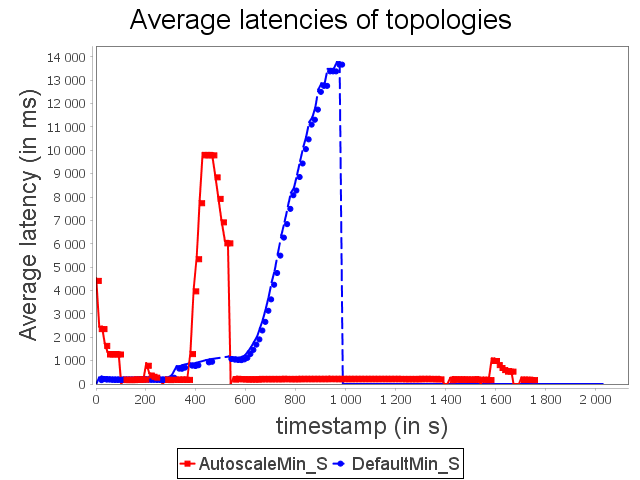
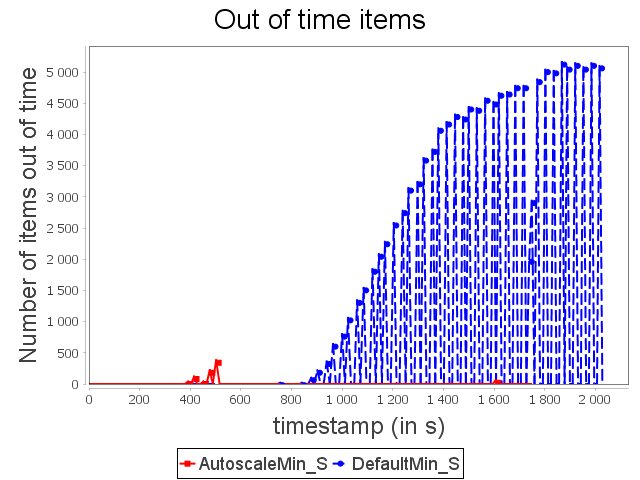
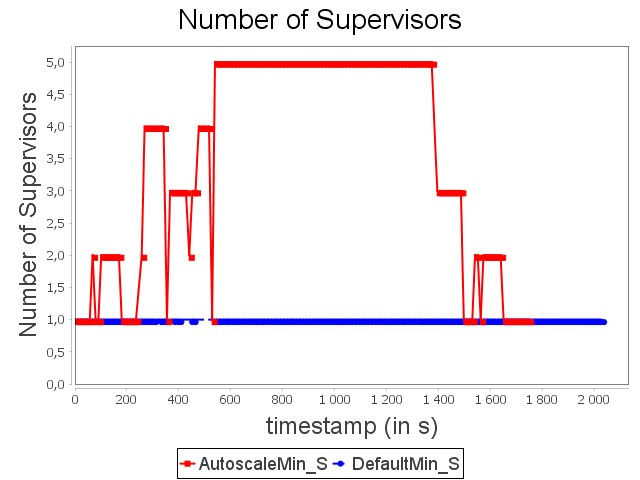
Star topology: min configuration
 |  |  |
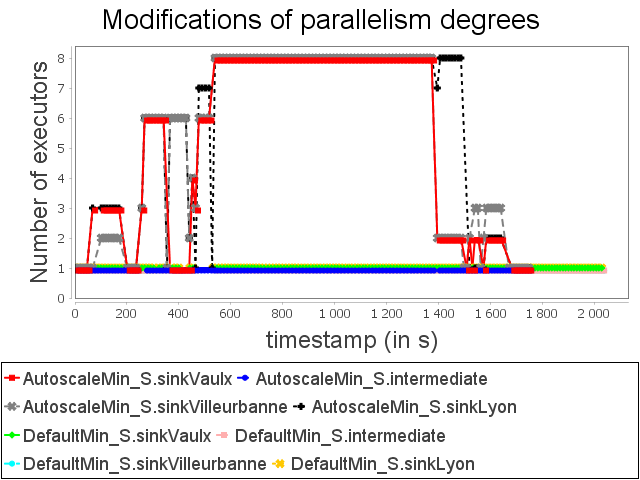 | 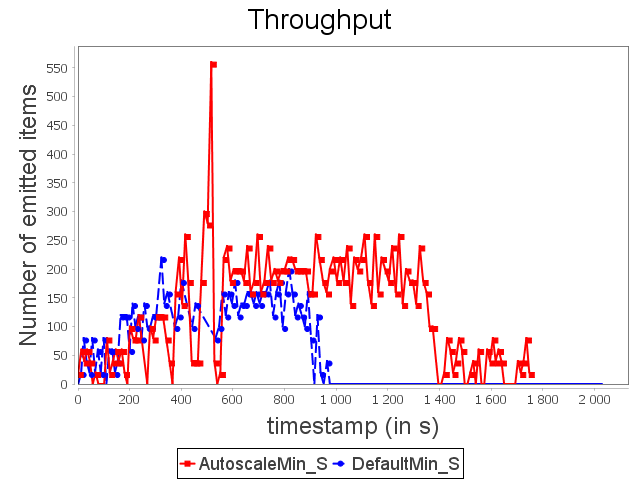 | 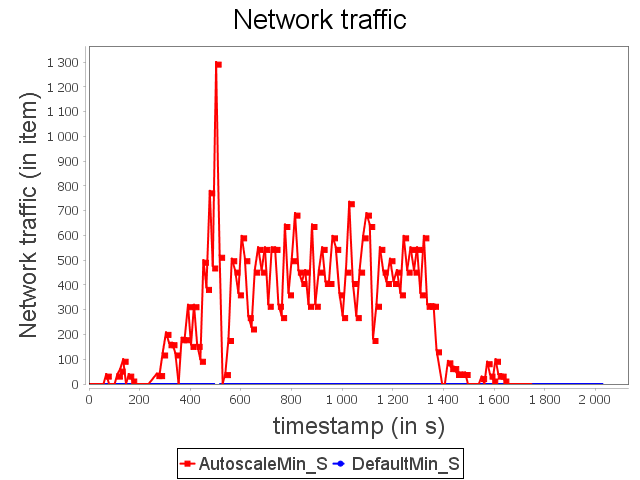 |
Concerning the star topology, a similar behavior is observed. It is worth noting that because of the structure of the star topology, AUTOSCALE is able to detect the risk of congestion before it actually happens. This can be done thanks to the awareness of the global context offered by AUTOSCALE.
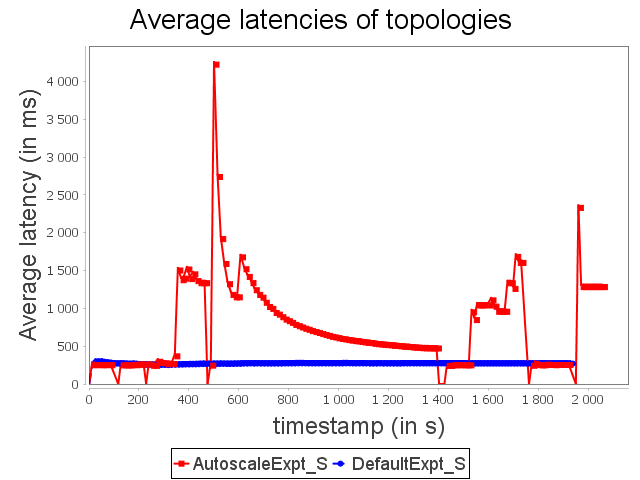
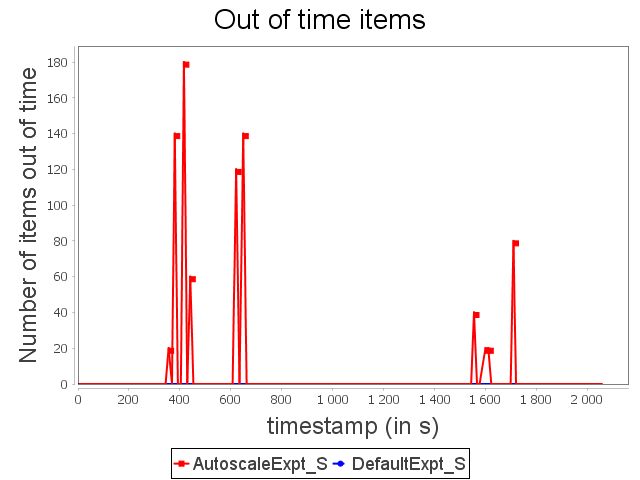
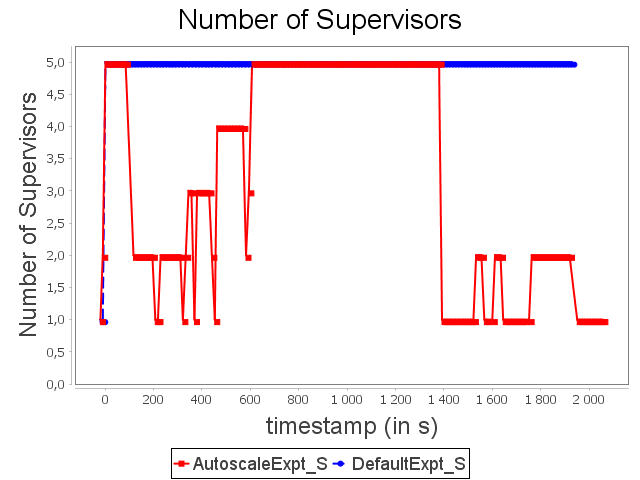
Star topology: expt configuration
 |  |  |
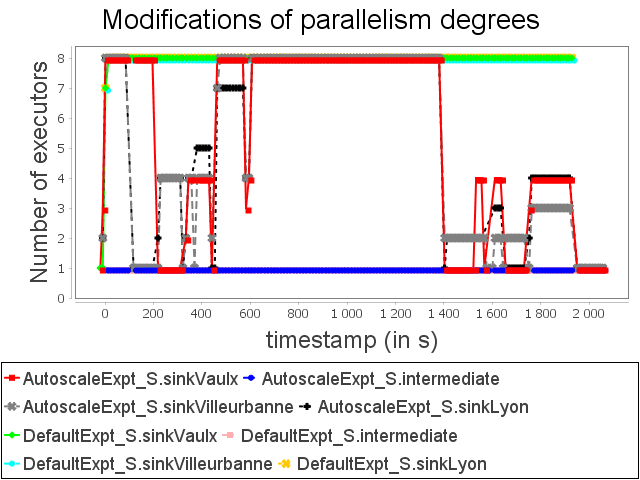 | 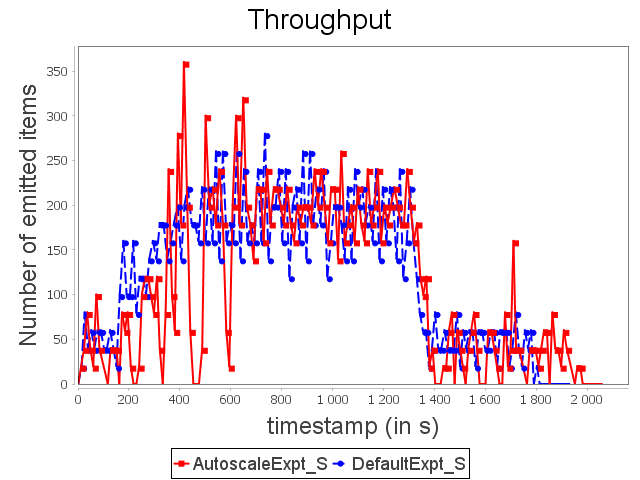 | 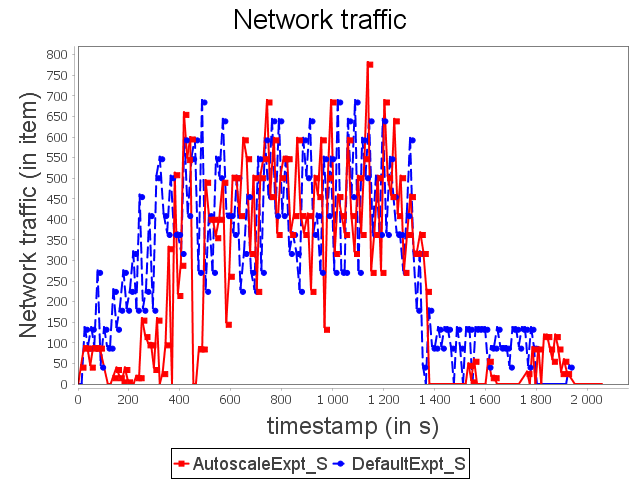 |
Finally, AUTOSCALE reduces resource usage around 24.6%. It is less than linear and diamond because there are more slow operators. Indeed, slow operators tend naturally to be more often in high or critical activity than fast ones.
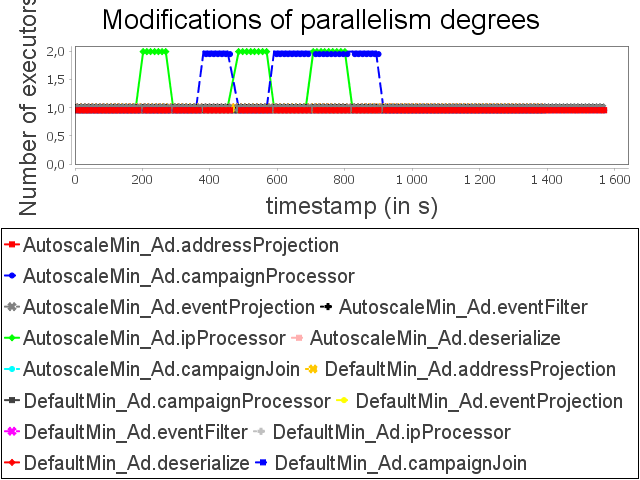
Advertising topology: min configuration
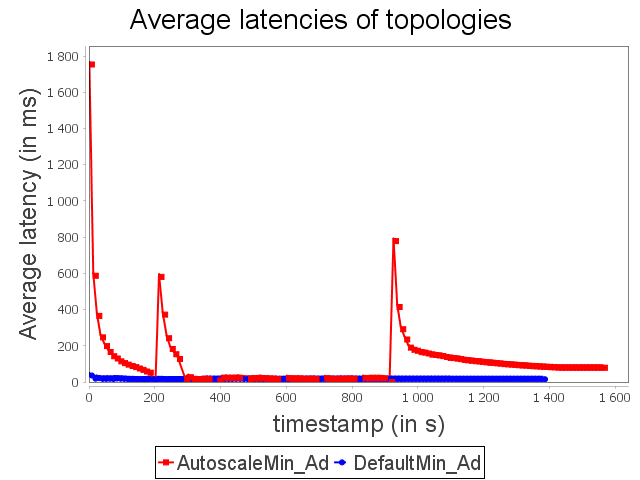 |  |  |
 | 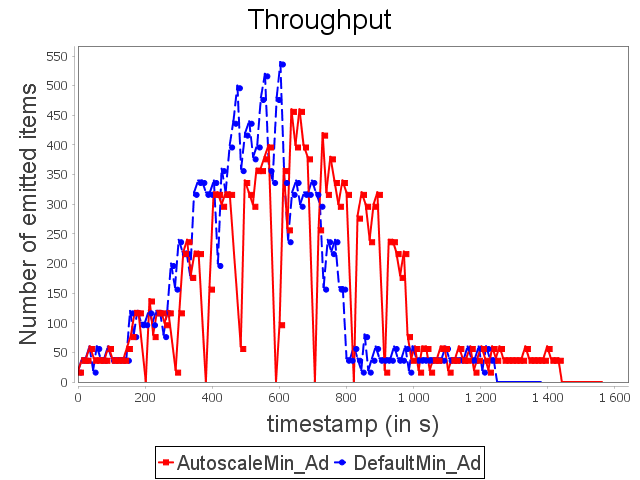 |  |
Finally, we test our approach on an advertising topology mainly inspired from a topology available on Github to validate our approach.
We essentially modify the source to be able to reproduce the same stream with different configurations and add two operators (ip projection and ip processor) to obtain a complex topology.
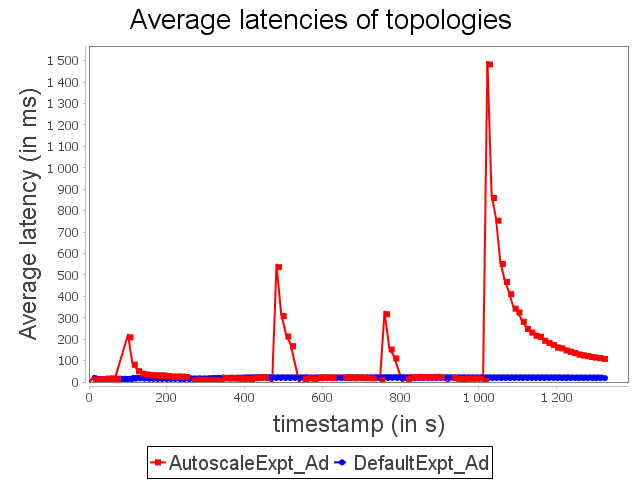
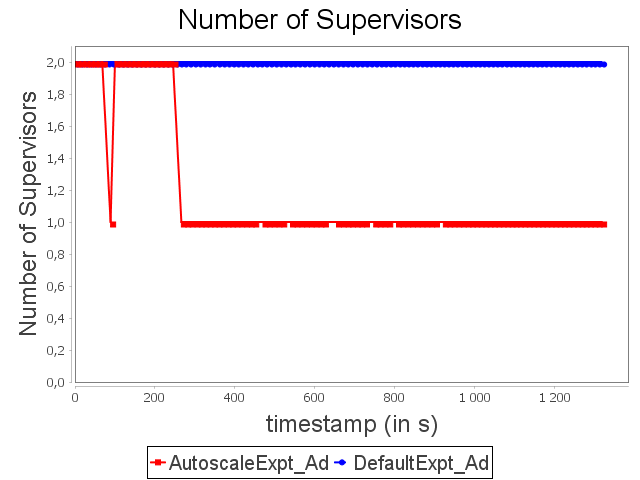
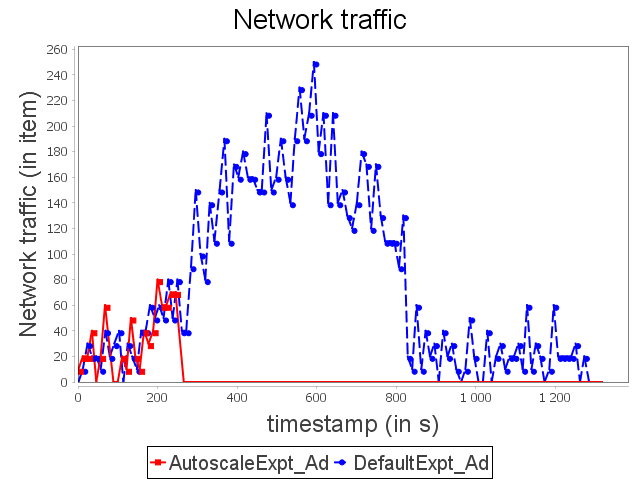
Advertising topology: expt configuration
 |  |  |
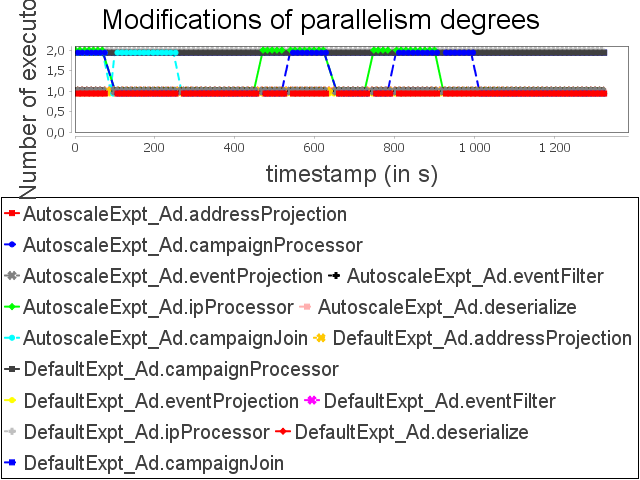 | 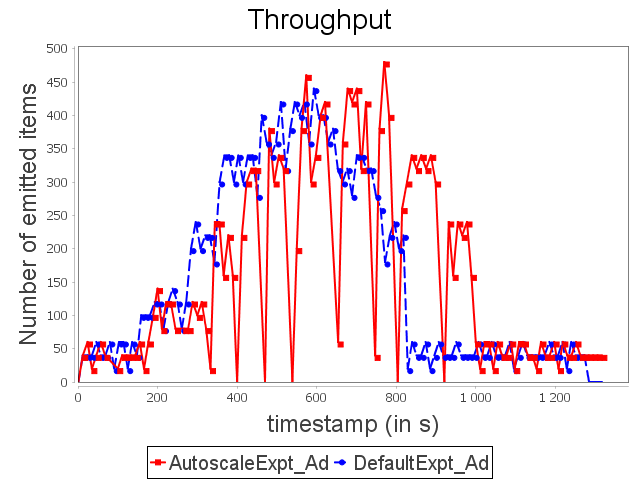 |  |
If a user bases his/her choice of parallelism degree exclusively on latencies, he/she will start the topology with some unnecessary executors. AUTOSCALE approach then performs scale-in to fit capacities of operators to their respective processing needs.
It is important to notice that the dynamic adaptation made by AUTOSCALE, combined with the scheduler, allows all treatments to be collected on a single supervisor. With AUTOSCALE, Storm is then able to handle biggest amount of data without generating network traffic, which is a large overhead factor, and using 50% less resources.
Downloads
AUTOSCALE scheduler v2.0
This version of AUTOSCALE is exclusively compatible with Apache Storm 1.0.1 and later because of package namespaces.
| Article submitted to ICDCS'17 | Download document |
| AUTOSCALE v2.0 (sources) | Download sources |
| AUTOSCALE v2.0 (jar) | Download zip file |
| AUTOSCALE v2.0 HOWTO | Download pdf |
| Monitoring database SQL script | Download SQL script |
Topologies
| Topologies + synthetic loads(sources) | Download zip file |
| Topologies + synthetic loads (jar) | Download zip file |
Contact
For any questions about AUTOSCALE, contact us at following address:
Email: roland.kotto-kombi@liris.cnrs.fr
Email: roland.kotto-kombi@liris.cnrs.fr
577 visites.