5. Multimedia annotation and hypervideo¶
Consider a book critic; while reading a book, she can annotate it by writing comments in the margins, dog-earing pages and/or using colored post-it notes as bookmarks. If the book is a digital file (e.g. a PDF document), her reading software provides similar functionalities, as well as additional ones, such as a dynamic table of contents reminding her at every moment of the overall structure of the book, showing which part she is currently reading, and allowing her to quickly navigate to another part. She can search the whole text of the book as well as her own annotations, jump to the corresponding location immediately, and just as easily jump back to the previous visited locations. Finally, she can easily copy-paste parts of the text in order to include them in her review.
Now consider a film critic; not so long ago, she still had to rely on a tape or DVD to watch the movie, with little possible interaction besides pause, rewind and fast-forward (and jumping to a specific chapter, in the case of DVDs). Nowadays, files and streaming have largely replaced tapes and DVDs, but software video players hardly provide more functionalities than their mechanical counterparts. Why has digitization not allowed audiovisual documents to evolve the way text has?
The main reason is probably that practices around audiovisual are much less mature than practices around text. Indeed, the technical means to capture and render videos are very recent (when compared to written text or still images), and even more so their availability to a large public. Furthermore, video is inherently more complex, as it has its own temporality, to which the reader must yield in order to access the audiovisual material. While it is possible to skim a text or glance at a photo, such things are not immediately possible with a video. Interestingly, when Nelson (1965) coined the term “hypertext”, he also proposed the notion of “hyperfilm”, described as “a browsable or vari-sequenced movie”, noticing that video and sound documents were currently restricted to linear strings mostly for mechanical reasons. Obviously, although hypertext (and more generally text-centered hypermedia) has become common place, Nelson’s vision of hyperfilms is not so widespread yet.
In this chapter, I will present our contributions in the topic of hypervideo based on video annotations. The first part will focus on our seminal work on Advene and the Cinelab data model. Then I will describe how video annotations often relate to traces, and how hypervideos can be used as a modality of MTBS. Finally, in the last section, I will show how various standards are converging to bring hypervideos to the Web.
5.1. Advene and the Cinelab Data Model¶
The Advene project1 was born in 2002 out of this assessment that, although it was technically possible to improve the way an active reader may interact with videos, only basic tools were actually available, mostly because no well-established practice (such as bookmarking, annotation, etc.) existed yet for audiovisual documents, that could have set off the creation of better tools. To be fair, a few such tools did exist at the time (for example Anvil2), but those were generally very focused on a particular field and a particular task (for example behavior analysis in human sciences).
Our goal was therefore to build a generic and extensible platform, that would allow the exploration and stabilization of new practices for video active reading. Since such a platform would allow new forms of interactions with audiovisual material, it would also inevitably foster new documentary forms, so Advene is both a tool for active reading, and a hypermedia authoring platform.
In order to support the emergence of new active reading practices, Advene had to provide a versatile data model. This data model was refined over time, resulting to the Cinelab data model (Aubert, Champin, and Prié 2012).
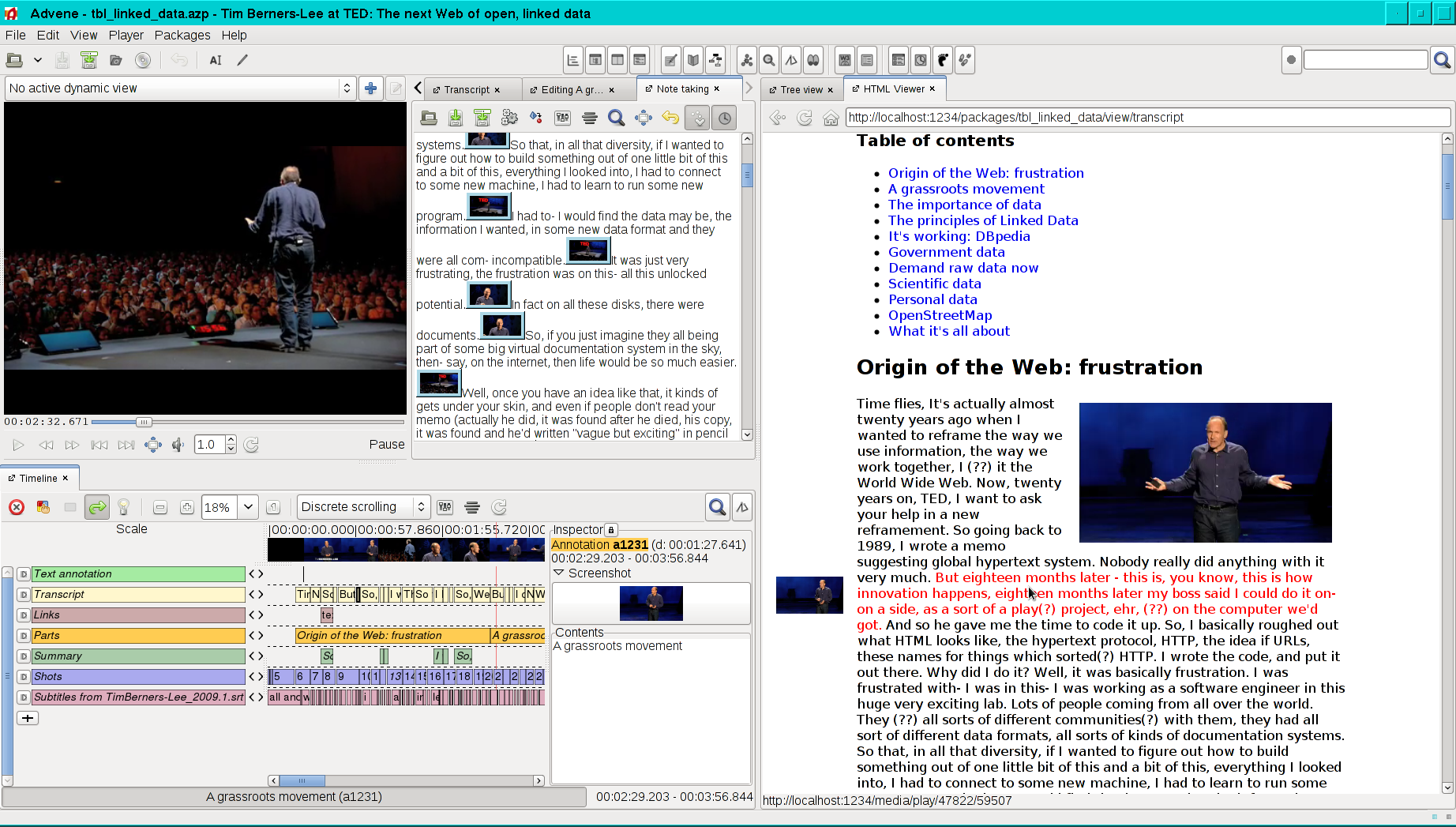
Fig. 5.1 A screenshot of Advene (http://advene.org/)¶
Anatomy of a Cinelab package¶
The central element in Cinelab is the annotation, which can be any piece of information attached to a temporal interval of an audiovisual document. An annotation is therefore specified by a reference to the annotated video, a pair of timestamps, and an arbitrary content. Note that we impose no a priori constraint on annotations, neither on the type of their content (which can be text, images, sound…) nor on their temporal structure (they can annotate any interval, from a single instant to the whole video, they can overlap with each other…). It is also possible for the annotator to define relations between annotations. A relation is specified by an arbitrary number of member annotations, and optionally a content.
With annotations and relations, users can mark and relate interesting fragments of the videos, and attach additional information to them. But they also need a way to further organize this information. For this purpose, the Cinelab data model provides two constructs: tags and lists, which allow to define, respectively, unordered or ordered groups of related elements. Tags and lists may contain any kind of Cinelab elements, including other tags or lists, and an element may belong to any number of tags or lists.
Tags and lists are simple and flexible enough to allow many organization structures. However it is often useful to group annotations and relations into distinct categories, called annotation types and relation types. Cinelab defines those as two specialized kinds of tags, with the constraint that any annotation (resp. relation) belong to exactly one annotation type (resp. relation type). Furthermore, a group of related annotation types and relations types can be defined as a specialized kind of list, called a description schema. For example, a description schema focusing on photography would contain the annotation types “long shot”, “medium shot” and “close-up”, while another schema focusing on the sound would contain the annotation types “voice”, “noise” and “music”.
It is important to understand that the information carried by annotations (and relations) is not bound a priori to any particular rendering. For example, consider annotations of type “voice” that contain the transcription of what is said in the annotated fragment of the video. They could obviously be displayed as subtitles (for the hearing impaired) but could also be displayed beside the video as an interactive and searchable transcript (as in the right side of Fig. 5.1); or they could be used indirectly by a hypervideo playing additional sounds (e.g. director’s comments or audio-descriptions for the visually impaired) to avoid overlapping with the characters speaking in the video. In this respect, annotations are analogous to HTML tags: they convey structure and semantics, and are orthogonal to presentation concerns.
Therefore, users also need to be able to specify and customize how they want their annotations to be presented, both during their activity, and afterwards to present the result of their work. In the Cinelab data model, a view is the specification of how to render a subset of the annotations. An application may support different kinds of views; in Advene, we distinguish
ad-hoc views, which are specific configurations of the GUI components available in the application (for example, the graphical time-line at the left-bottom of Fig. 5.1),
static views, which are XML or HTML documents generated through a dedicated template language (one of them illustrated on the right side of Fig. 5.1), and
dynamic views, which are described by a list of Event-Condition-Action (ECA) rules, triggered while the video is playing (in order, for example, to overlay annotation content on the video, or automatically pause at the end of a given annotation).
All the elements described above3 are grouped in a file called a package, which can be serialized in different formats (we have defined an XML-based and a JSON-based format). As packages do not contain the annotated audiovisual material, but only references to it, they are generally small enough to be easily shared (on the Web, via e-mail or USB sticks). This was also meant to avoid issues related to copyrighted videos; it is the responsibility of each user of a package to gain legitimate access to the videos referenced in it. Note also that any package can import elements from other packages, in order to build upon somebody else’s work.
Active reading with Advene¶

Fig. 5.2 Active reading processe (Aubert et al. 2008)¶
Our experience with Advene suggests that video active reading can be decomposed into a number of processes, enumerated in Fig. 5.2. We also propose to group those processes in four intertwined phases: inscription of marks, (re-)organization, browsing and publishing. We have shown (Aubert et al. 2008) how those processes are supported by Advene and the Cinelab model, and how they can be mapped to the canonical processes identified by Hardman et al. (2008).
As an example, let us consider Mr Jones, teacher in humanities, who wants to give a course about the expression of mood in movies. He bases his work on the movie Nosferatu (Murnau 1929), and more specifically on how the movie’s nightmarish mood is built4. He starts from scratch, having seen the movie only once and read some articles about it.
Using the note-taking editor of Advene, Mr Jones types timestamped notes in a textual form, that he will later convert to annotations (Create annotations). He also uses an external tool that generates a shot segmentation of the movie, and imports the resulting data in Advene, generating one annotation for each shot (Import annotations).
Now that the teacher has created a first set of annotations, and thought of some ideas while watching the movie, he organizes the annotations in order to emphasize the information that he considers relevant. From the shot annotations and his own notes, Mr Jones identifies the shots containing nightmarish elements (Visualize/Navigate), creates a new annotation type Nightmare (Create schema), copies the relevant annotations into it and adds to them a textual content describing their nightmarish features (Create/Restructure annotations). As he has gained a better understanding of the story, he also creates annotations dividing the movie in chapters, each of them containing a title and a short textual description, and he creates a new annotation type Chapter for those annotations.
In order to ease the navigation in the movie, Mr Jones defines a table of contents as a static-view (Create view), generated from the annotations of type Chapter, illustrated by screenshots extracted from the movie, with hyperlinks allowing to play the corresponding part of the movie. He also creates a dynamic view that displays the title of the current chapter as a caption over the video, in order to always know which part of the movie is playing when he navigates through the annotations.
Taking advantage of all those annotations and the newly created views, the teacher wants to dig into some ideas about the occurrence of specific characters or animals in the movie. He can select the corresponding annotations manually by identifying them in a view (Visualize/Navigate), or use Advene’s search functionalities to automatically retrieve a set of annotations meeting a given criterion (Query). Doing so, he identifies a number of shots featuring animals (spiders, hyenas…) that contribute to the dark mood of the movie.
While browsing the movie, he also creates new annotations (Create annotations) and new types (Create and modify schemas) as he notices other relevant recurring features. In the active-reading analysis, we find here a quick succession of browsing-inscription-organisation activities, when users decide to enrich the annotations while watching the movie. Inscription occurrences may last a couple of seconds, and should not be obtrusive to the browsing process.
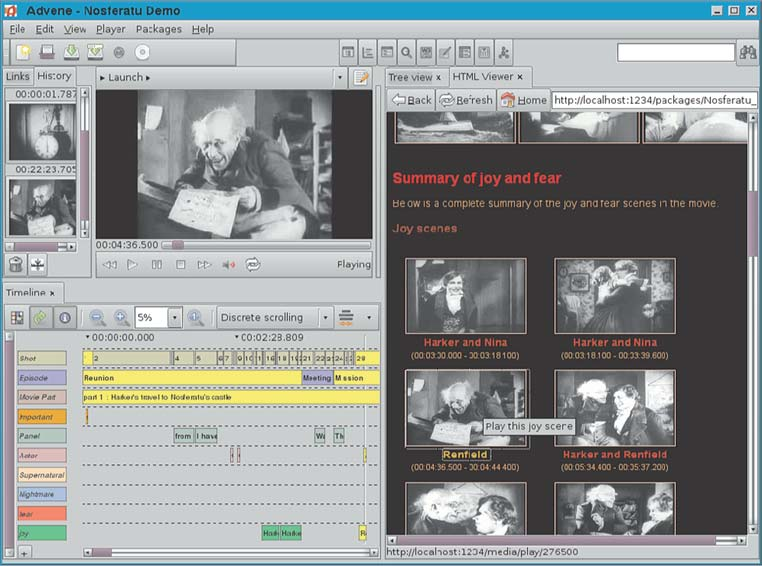
Fig. 5.3 An actual analysis of Nosferatu in Advene (Aubert et al. 2008)¶
This continuous cycle also brings Mr Jones to create more specific views, dedicated to the message/analysis that he wishes to carry: in order to have an overview of the nightmarish elements, he decides to create a view that generates a dynamic montage (Create view), chaining all the fragments annotated by the Nightmare type. This allows him to more precisely feel and analyze their relevance and relationships: watching his new montage (Select view/Visualize/Navigate) corroborates the ideas that he wishes to convey, and allows him to have a clearer view of how he will present them to his students.
Now that Mr Jones has identified the relevant items and refined his analysis, he can write it down as a critique, in a static view illustrated by screenshots of the movie linked to the corresponding video fragments (Create view). He prints the rendition of this static view from a standard web browser, in order to distribute it to his students in class (Publish view renditions). He also cleans up the package containing his annotations and views, removing intermediate remarks and notes, in order to keep only the final set of annotations, description schemas and views. He uploads that package to his homepage on a web-server (Publish package), so that his students can download it and use it to navigate in the movie. This second option is more constraining for the students, requiring them to use Advene or a compatible tool5. But on the other hand it allows them to pursue the analysis through the same active reading cycle as described above, without having to start from scratch.
From this use-case, it appears that Cinelab packages are very similar to the multi-structured documents presented in Section 4.2: the complex relations between the linear temporality of the video and the elements of a package allow multiple readings and interpretations. A subset of those interpretations is “materialized” by the views provided in the package, but it is not closed as long as the package is distributed as is, reusable and augmentable by others.
Finally, Mr Jones publishes a copy of his package after removing all annotations, leaving only the description schema he has defined and the associated generic views. As an assignment, he asks his student to analyze with Advene another horror movie, reusing the annotation structure provided in this “template” package (that they can import in their own package). This emphasizes another important feature of the Cinelab data model: not only does it allow the exploration of innovative annotation practices, it also encourages their stabilization and their sharing as explicit and reusable organization structures.
5.2. Videos and annotations as traces¶
There is an obvious similarity between the Cinelab model presented above and the Trace meta-model presented in Chapter 2. Indeed, videos are often used to record a situation, hence as a kind of raw traces. Video annotations, on the other hand, are a mean to describe the content of a video in a structured way, easier to handle and process that the audiovisual signal itself. As they provide a machine-readable description of the filmed situation, such annotations can therefore be considered as obsels, all the more that they have the same basic structural features: they are anchored to a time interval, typed, and potentially carrying additional information.
Conversely, any obsel about an activity that has been filmed can be synchronized with the corresponding video, hence considered as annotating that video. Following the principles explored with Advene and Cinelab, those obsels and the video can be used together to generate a hypervideo, which can in turn be used as a mean to visualize and interact with the trace. The trace model, defining the different types of obels that he trace may contain, plays a role very similar to the description schemas in Cinelab.
Video-assisted retrospection¶
In the Ithaca project6 (2008-2011), we have studied the use of traces to support synchronous collaborative activities, as well as the duality of traces and video annotations. For this, we have developed a proptotype called Visu.
Visu is an online application with two parts. The first part is a virtual classroom (see Fig. 5.4) for a teacher and a group of students, offering a video-conferencing and chat platform as well as more specific functionalities with educational purposes: the teacher can define in advance a course outline and a set of documents (left side of the figure), that he/she can push in the chat during the session. The second part of Visu is called the retrospection room; it allows the teacher to play back the video of a past session. In Ithaca, the teachers using Visu were actually in training, and the retrospection room was used to help them understand and overcome the difficulties they may have encountered during the class.
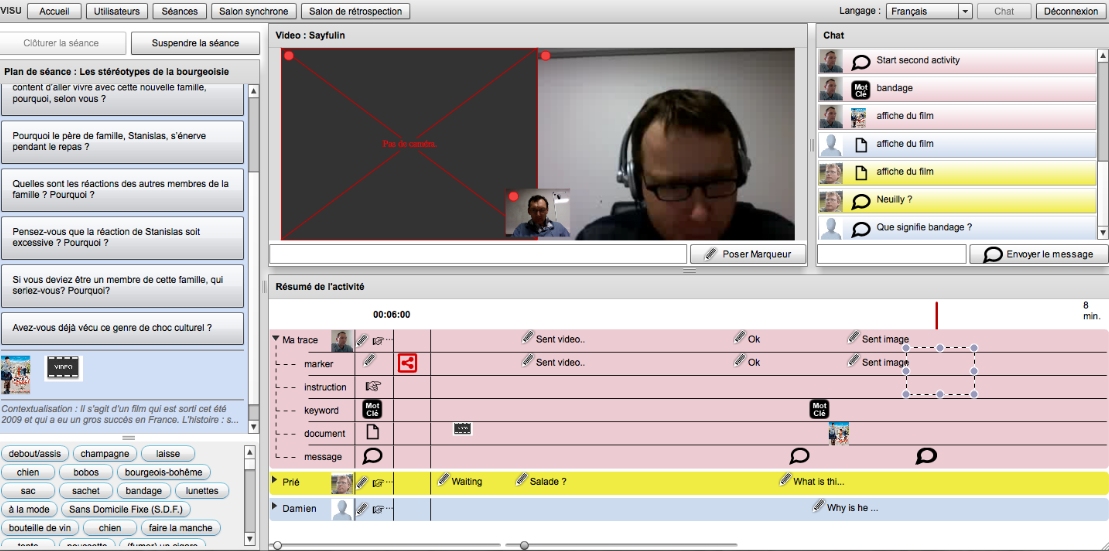
Fig. 5.4 The virtual classroom of Visu¶
During the session, every interaction of the users with the application (typing in the chat, pushing a document, opening a document, etc.) is traced and displayed on a graphical time-line (lower-part of Fig. 5.4). It provides the teacher and the students with a sense of reflexivity on the group’s activity. Information in the time-line can also be used by the teacher at the end of the session to do a short debriefing with the students. In the retrospection room, the time-line is synchronized with the video play-back, and gives the teacher a more complete view of what happened during the session.
In addition to those automatically collected annotations, Visu allows the teacher and the students to manually add markers in the time-line, containing short messages. Unlike chat messages, which are public and used to communicate synchronously with the group, markers are generally only visible by the teacher, and used to come back later (i.e. during the debriefing or the retrospection) to the moments of the session when they were created.
In the retrospection room, the teacher can further annotate the video with a third kind of annotation called “comments”. Contrarily to the annotations created during the session, comments are not restricted to annotate a single instant of the video, but may span a time interval. They are used to synthesize the hindsight gained by the training teacher in the retrospection room. It is also possible to produce a report by reorganizing the comments, adding more text and screenshots from the video. This functionality can be compared to the trace-based redocumentation process (Yahiaoui et al. 2011) presented in the third chapter.
Visu has been used in different settings, and an analysis of our first experiments was presented by Betrancourt, Guichon, and Prié (2011). Although the application may first be cognitively challenging, the teachers got used to it after the first session, and did use its specific functionalities (especially markers). Moreover, it has been observed that different teachers had developed different practices with markers, which confirms the flexibility of that functionality. Finally, the teachers used less markers during the last session, which tends to indicate that one motivation for using markers was to prepare for future sessions, using the retrospection room.
Archiving and heritage¶
Video traces are not limited to short-term usage, they can be archived to serve as cultural heritage, in which case it is critical to index them effectively, to ensure their usability in the long run. One of the goals of Spectacle en ligne(s) project7, presented in our paper by Ronfard et al. (2015), was to propose such effective indexing structures, based on the Cinelab model.

Fig. 5.5 Three steps in the theater rehearsal process for Cat on a hot tin roof: table readings, early rehearsals in a studio, late rehearsals on stage.¶
More precisely, this project aimed at creating a richly indexed corpus of filmed performing arts, and exploring innovative uses for the performers themselves, other professionals, and the larger public. Two shows were covered by that project: Cat on a hot tin roof by Tenessee Williams, directed by Claudia Stavisky at the Théatre des Célestins (Lyon), and the baroque opera Elena by Francesco Cavalli, directed by Jean-Yves Ruf and conducted by Leonardo García Alarcón at the Aix-en-Provence Festival. The originality of the created corpus was that we didn’t capture the public performances, instead we recorded all the rehearsals.
As rehearsals are typically private moments, sometimes even qualified as “sacred”, the setting for capturing them was designed to be as unintrusive as possible. A dedicated operator had the responsibility of recording each rehearsal, using a fixed full-HD camera controlled by a PC laptop, that also allowed them to annotate the video while it was being captured. More precisely, the embedded application was designed around a predefined description schema that had been created specifically for that project. The role of those annotations was to provide a first level of indexation: a rehearsal is segmented with annotations of two different types, Performance and Discussion. Each chapter is then described with a number of properties: which part of the play/opera was being rehearsed, which actors where presents, was it with or without costumes, with or without sets, etc. A third annotation type, Moment of interest, allowed to further describe specific instants of the rehearsals with a free-text comment and some categories, defined on the fly by the operator. In the end, 419 hours of video were captured, and 10,498 annotations were created.
But the annotation process didn’t stop at the end of the rehearsal. First, the annotations created during the session required some off-line manual cleansing (correcting misspellings, harmonizing categories…). Then, some partners in the project have proposed automatic annotation processes, based on the audiovisual signal and the cues provided by the manual annotations. For example, using machine learning techniques to recognize the voice and appearance of each actor, it was possible to create fine-grained annotations aligning the video with individual lines of the script, and annotations spatially locating each actor in each frame of the video. This is computationally very expensive, so we could only process a subset of the corpus in the timeframe of the project, but the results were very encouraging (Gandhi and Ronfard 2013).
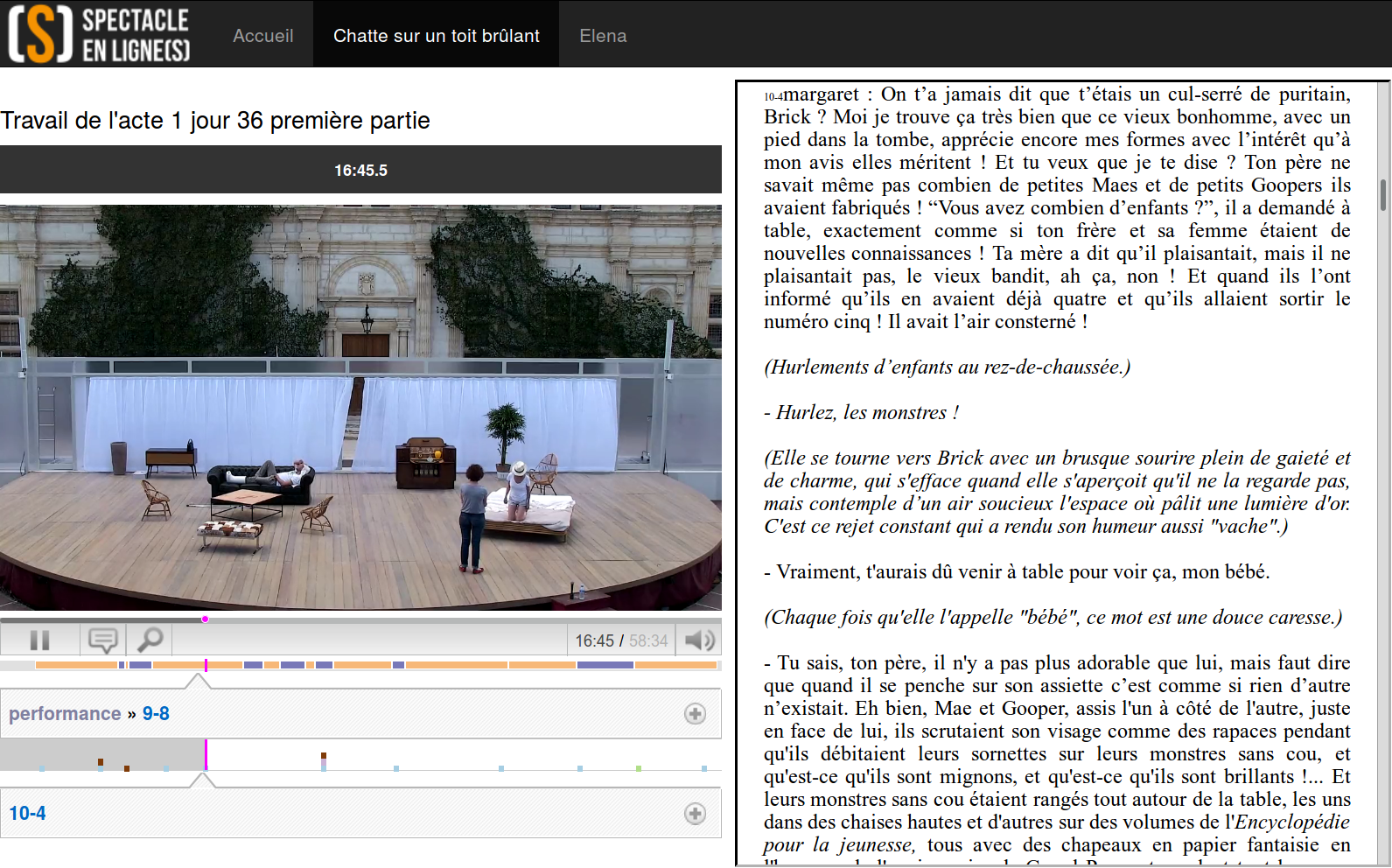
Fig. 5.6 The Spectacle en ligne(s) platform¶
To demonstrate the benefit of this annotated corpus, we have developed a number of prototypes. The whole corpus can be searched online7, with a faceted browser (based on the features describing each chapter, and the categories of the moments of interest). Each video can be watched, augmented with a time-line displaying the annotations (similar to the one of Advene), and a synchronized script, automatically scrolling to the part being rehearsed (Fig. 5.6). This allows critics, teachers and other professionals to study the creative process in an unprecedented way. On the scenes where we have computed line-level annotations, each line is highlighted in the script when it is delivered, and it is possible to navigate directly to the same line in any other rehearsal. Using the spatial location of the actors in the video we have simulated multiple cameras, each of them following one character (by simply zooming on the corresponding area of the original video). This was made possible by the high resolution of the original video. Then, using the line annotations, we have proposed a virtual montage by automatically switching to the character currently speaking, making the video less monotonous to watch. We have also considered alternative ways to generate such a virtual montage, like framing two characters instead of one during fast paced dialogues.
Interestingly, during the production of the archive, the creative crew reacted quite positively to the experiment and expressed interest in getting immediate feedback. While this had not been planned, we started designing mobile applications that they could tentatively use for (i) viewing on their smartphones the live feed being recorded and (ii) adding their own (signed) annotations and comments collaboratively. While not fully implemented, this feature was presented to the directors and their collaborators as mock-ups. These mock-ups were generally well received and are likely candidates as an addition to the existing system for future experiments.
Beyond Spectacle en ligne(s), we are involved in another project concerned with video archives and cultural heritage. The former prison of Montluc, in Lyon, has been turned into a memorial in 2010. This memorial focuses on the period when this prison was used by the Nazis during World War II. A research group in sociology has conducted an inquiry to analyze and document this heritage process, shedding light on other memorable periods where that prison was used. From this inquiry, they produced a corpus of video interviews and additional materials (photos, documents). Their goal was to publish it in order to sustain the continuous emergence of multiple memories related to Montluc, beyond the one highlighted by the memorial itself. Therefore, their challenge was to make this multiplicity of histories and memories legible, to allow multiple interpretations of the place by people with different experiences and pasts, and to encourage novel uses of the venue. In collaboration with them, we have designed a Web application8 providing access to this corpus (Michel et al. 2016), but also allowing users to add their own annotations, keeping the heritage process in constant momentum. In the future, we plan to study the interaction traces of the users, as well as the annotations they contributed, to evaluate and improve the design of the Web application with respect to those goals.
5.3. Hypervideos on the Web¶
When we started working on Advene (in 2002), hypervideo in general, and video integration with the Web in particular were still in their infancy. At that time, the main way to integrate a video player in a HTML page was to use a proprietary browser plugin (very much frowned upon), and none of the popular video sharing websites, that are now an integral part of the Web ecosystem, existed yet.
Still, from the very beginning, we aimed to integrate Advene with Web technologies as much as possible. As explained in Section 5.1, static views in Advene produce XML or HTML documents, which can be exported and published on any Web server, but also delivered dynamically by a HTTP server embedded in the application. The benefit of that embedded server is that it has access to the annotated video. It can for example extract content on the fly (such as snapshots) that will be included in the static view, but most importantly, it can control the video player included in the Advene GUI. Advene thus exposes a number of URLs that can be used to drive its video player from any HTML page. For example, in Fig. 5.1, the HTML transcript on the right side is dynamic: every sentence is a link that will start the video player at that point of the talk. Although this is not a full-Web solution (it requires Advene to run on the client’s machine) it allowed us to experiment very early-on with the interactions between video and HTML-based hypermedia.
In 2009, we started the ACAV project in partnership with Eurecom9 and Dailymotion10. The goal was to improve the accessibility of videos for people with visual and hearing disabilities, using annotations to enrich videos in various ways, adapted to the viewers’ impairment and to their preferences. For example, the descriptions for visually impaired people may be rendered on a braille display or as an audio-description (using a speech synthesizer), it may be more or less detailed, etc. The flexibility offered by the Cinelab data model could be leveraged to achieve this goal. We have defined a description schema, specifying the different types of annotations required to enrich the video in the various ways required by impaired users, and we have prototyped a number of views using those annotations. The intended workflow is described in Fig. 5.7: signal-processing algorithms automatically produce a first set of annotations, which is then manually corrected and augmented. Two kinds of users were expected to contribute to those annotations: associations and enthusiasts concerned with disabilities and accessibility, and institutional video contributors, bound by legal obligations to make their videos accessible. Unfortunately, despite encouraging results with our prototypes (Champin et al. 2010; Villamizar et al. 2011), Dailymotion didn’t go as far as put the system in production.

Fig. 5.7 The ACAV workflow for producing accessible hypervideos (Champin et al. 2010)¶
As video was increasingly becoming a first-class citizen of the Web,
it also became possible to refine the notion of view in Cinelab,
in order to align it with emerging technologies such as the HTML5 video tag.
CHM (Sadallah, Aubert, and Prié 2011; 2014)
is a generic component-based architecture for specifying Cinelab views,
with an open-source implementation based on HTML5.
Compared to Advene’s templates and ECA-rules,
CHM provides a more declarative way to describe hypervideos,
and incorporate high-level constructs for the most common patterns,
such as subtitles, interactive table of contents or interactive transcripts.
Then, we have put those ideas one step further (Steiner et al. 2015)11
by relying on the emerging Web Components standard (Glazkov 2016).
With this new specification,
it becomes possible to extend HTML with new tags,
making hypervideo components even more integrated with Web standards,
and easier to use by Web developers.
Finally, after video, annotations themselves are in the process of being standardized. With Media Fragment URIs (Troncy et al. 2012) we have a standard way to identify and address fragments of any video with its own URI, and a few proposals already exist to extend this recommendation1213 in a possible reactivation of the working group. Besides, the candidate recommendation by Sanderson, Ciccarese, and Young (2016) proposes a Web Annotation Data Model, which allows to annotate any Web resource or fragment thereof with arbitrary data (and possibly other resources), and to serialize those annotations as Linked Data (using JSON-LD). Our own work follows the same line as those standards. Our re-interpretation of WebVTT as Linked Data (Steiner et al. 2014) presented in Section 4.2 made use of Media Fragment URIs; although we defined a specific data-model (based on the structure of WebVTT), adapting it to Web Annotation should be relatively straightforward. Later, in the Spectacle en ligne(s) project presented above, we published the whole corpus of annotations as Linked Data (Steiner et al. 2015), after proposing an RDF vocabulary capturing the Cinelab data model. At the time, we aligned that vocabulary with some terms of the Web Annotation Data Model, but as the latter is about to become a recommendation, it would be interesting to update and refine this alignment.
In the longer term, we will probably redefine the Cinelab data model itself as an extension of the Web Annotation data model. Indeed, the overlapping concepts are close enough, so Cinelab annotations can ambivalently be re-interpreted as a special case of Web annotations. Both models would benefit from this unification, as Cinelab-aware tools (such as Advene) would become usable to publish standard-compliant annotations, and hence attractive to a larger audience.
Probably more than any other type of information, multimedia content lends itself to multiple interpretations. This is why the languages and tools used to handle this kind of content must be flexible enough. The works presented in this chapter describe our efforts to propose such languages and tools, not only by enabling subjective analyses to be expressed, but also by allowing to stabilize interpretative frameworks as sharable schemas.
Notes
- 1
- 2
- 3
Actually, the Cinelab model defines a few other categories of elements, which are not described here for the sake of conciseness and clarity. The interested reader can refer to the complete documentation (Aubert, Champin, and Prié 2012) for full details.
- 4
Although this example is fictional, an actual Advene package corresponding to what Mr Jones would have produced can be downloaded at http://advene.org/examples.html, and is illustrated in Fig. 5.3.
- 5
For example, the Institut de Recherche et d’Innovation (IRI) has adopted Cinelab for their own video annotation tools: http://www.iri.centrepompidou.fr/.
- 6
- 7(1,2)
- 8
- 9
- 10
- 11
- 12
- 13
Chapter bibliography
Aubert, Olivier, Pierre-Antoine Champin, and Yannick Prié. 2012. “Cinelab Data Model.” July 2012. http://advene.org/cinelab/.
Aubert, Olivier, Pierre-Antoine Champin, Yannick Prié, and Bertrand Richard. 2008. “Canonical Processes in Active Reading and Hypervideo Production.” Multimedia Systems Journal 14 (6): 427–33. https://doi.org/10.1007/s00530-008-0132-2.
Betrancourt, Mireille, Nicolas Guichon, and Yannick Prié. 2011. “Assessing the Use of a Trace-Based Synchronous Tool for Distant Language Tutoring.” In Computer-Supported Collaborative Learning, 1:478–85. Hong Kong, China. https://hal.archives-ouvertes.fr/hal-00806428.
Champin, Pierre-Antoine, Benoît Encelle, Nicholas W. D. Evans, Magali Ollagnier-Beldame, Yannick Prié, and Raphaël Troncy. 2010. “Towards Collaborative Annotation for Video Accessibility.” In 7th International Cross-Disciplinary Conference on Web Accessibility (W4A 2010). https://doi.org/10.1145/1805986.1806010.
Gandhi, Vineet, and Rémi Ronfard. 2013. “Detecting and Naming Actors in Movies Using Generative Appearance Models.” In CVPR 2013 - International Conference on Computer Vision and Pattern Recognition, 3706–13. Portland, Oregon, United States: IEEE. https://doi.org/10.1109/CVPR.2013.475.
Glazkov, Dimitri. 2016. “Custom Elements.” W3C Working Draft. W3C. https://www.w3.org/TR/custom-elements/.
Hardman, Lynda, Željko Obrenović, Frank Nack, Brigitte Kerhervé, and Kurt Piersol. 2008. “Canonical Processes of Semantically Annotated Media Production.” Multimedia Systems 14 (6): 327–40. https://doi.org/10.1007/s00530-008-0134-0.
Michel, Christine, Marie-Thérèse Têtu-Delage, Pierre-Antoine Champin, and Laetitia Pot. 2016. “Stimulating the Heritage Process with Web Platforms.” Les Cahiers Du Numérique, Médiation des mémoires en ligne, 12 (3): 31–50. https://doi.org/10.3166/lcn.12.3.31-50.
Murnau, Friedrich Wilhelm. 1929. Nosferatu. Centraal Bureau voor Ligafilms.
Nelson, Theodor Holm. 1965. “Complex Information Processing: A File Structure for the Complex, the Changing and the Indeterminate.” In Proceedings of the 1965 20th National Conference, 84–100. ACM ’65. New York, NY, USA: ACM. https://doi.org/10.1145/800197.806036.
Ronfard, Rémi, Benoit Encelle, Nicolas Sauret, Pierre-Antoine Champin, Thomas Steiner, Vineet Gandhi, Cyrille Migniot, and Florent Thiery. 2015. “Capturing and Indexing Rehearsals: The Design and Usage of a Digital Archive of Performing Arts.” In , 533–40. IEEE. https://doi.org/10.1109/DigitalHeritage.2015.7419570.
Sadallah, Madjid, Olivier Aubert, and Yannick Prié. 2011. “Component-Based Hypervideo Model: High-Level Operational Specification of Hypervideos.” In Document Engineering 2011 (DocEng 2011), edited by ACM, 53–56. http://liris.cnrs.fr/publis/?id=5290.
———. 2014. “CHM: An Annotation- and Component-Based Hypervideo Model for the Web.” Multimedia Tools and Applications 70 (2): 869–903. https://doi.org/10.1007/s11042-012-1177-y.
Sanderson, Robert, Paolo Ciccarese, and Benjamin Young. 2016. “Web Annotation Data Model.” W3C Candidate Recommendation. W3C. https://www.w3.org/TR/annotation-model/.
Steiner, Thomas, Hannes Mühleisen, Ruben Verborgh, Pierre-Antoine Champin, Benoît Encelle, and Yannick Prié. 2014. “Weaving the Web(VTT) of Data.” In Linked Data on the Web (LDOW2014), edited by Tim Berners-Lee Christian Bizer Tom Heath, Sören Auer, 1–10. http://liris.cnrs.fr/publis/?id=6501.
Steiner, Thomas, Rémi Ronfard, Pierre-Antoine Champin, Benoît Encelle, and Yannick Prié. 2015. “Curtains Up! Lights, Camera, Action! Documenting the Creation of Theater and Opera Productions with Linked Data and Web Technologies.” In . Rotterdam, NL. https://hal.inria.fr/hal-01159826/document.
Troncy, Raphaël, Erik Mannens, Silvia Pfeiffer, and Davy Van Deursen. 2012. “Media Fragments URI 1.0 (Basic).” W3C Recommendation. W3C. http://www.w3.org/TR/media-frags/.
Villamizar, José Francisco Saray, Benoît Encelle, Yannick Prié, and Pierre-Antoine Champin. 2011. “An Adaptive Videos Enrichment System Based On Decision Trees For People With Sensory Disabilities.” In 8th International Cross-Disciplinary Conference on Web Accessibility (W4A 2011). https://doi.org/10.1145/1969289.1969299.
Yahiaoui, Leila, Yannick Prié, Zizette Boufaïda, and Pierre-Antoine Champin. 2011. “Redocumenting Computer Mediated Activity from Its Traces: A Model-Based Approach for Narrative Construction.” Journal of Digital Information (JoDI) 12 (3). https://journals.tdl.org/jodi/index.php/jodi/article/view/2088.